Capítulo 4: Arquiteturas de Visão#

Introdução#
Nos capítulos anteriores extraímos features de imagens manualmente. Calculávamos bordas, histogramas, descritores e os passávamos a um classificador. Deep learning inverte essa lógica: em vez de definirmos quais características importam, a própria rede aprende a extraí-las diretamente dos dados. As camadas iniciais capturam padrões simples (bordas, gradientes), as intermediárias combinam-nos em texturas e partes, e as profundas formam representações de objetos inteiros. Essa hierarquia de representações aprendidas é o que torna o deep learning a abordagem dominante em visão computacional moderna.
Três famílias de arquiteturas concentram hoje praticamente todo o estado da arte:
Aspecto |
CNN |
Transformer (ViT, DETR) |
VLM (Vision-Language) |
|---|---|---|---|
Mecanismo |
kernels deslizantes, local |
self-attention global |
encoder visual + LLM |
Entrada |
imagem (H × W × C) |
imagem em patches |
imagem + texto |
Exemplos |
ResNet, EfficientNet, YOLO |
ViT, SAM, DINO, CLIP |
Gemini, GPT-4V, Claude, LLaVA |
Forte em |
tempo real, embarcado |
escala, segmentação |
tarefas abertas, raciocínio |
Redes Convolucionais (CNNs)#
A revolução começou em 2012, com a AlexNet vencendo o desafio ImageNet por uma margem larga sobre os métodos clássicos. As CNNs aplicam kernels deslizantes que operam em vizinhanças locais da imagem e empilham camadas para formar uma hierarquia espacial. Duas propriedades as tornam particularmente boas para imagens: equivariância a translação (um padrão é reconhecido onde quer que apareça) e compartilhamento de pesos (o mesmo filtro varre a imagem inteira, reduzindo drasticamente o número de parâmetros). Mesmo após o avanço dos Transformers, CNNs continuam dominantes em cenários com restrição de hardware (mobile, edge, robótica) pela eficiência computacional. Famílias modernas incluem ResNet, EfficientNet e a linha YOLO (detecção em tempo real).
Transformers para Visão (ViT, DETR)#
Originalmente propostos para texto em 2017, os Transformers chegaram às imagens em 2020 com o Vision Transformer (ViT). A ideia é simples e radical: divide-se a imagem em pequenos patches (ex.: 16×16 pixels), trata-se cada um como um token (análogo a uma palavra em um texto) e aplica-se self-attention entre todos os patches. Isso permite que qualquer região da imagem interaja diretamente com qualquer outra, sem o viés de localidade das convoluções. O custo: Transformers precisam de muito mais dados para aprender o que as CNNs já sabem por construção (estrutura espacial). Em compensação, escalam melhor com tamanho de modelo e dataset, e são a espinha dorsal de modelos como SAM (segmentação universal), DINO (representações auto-supervisionadas) e CLIP (alinhamento visão-texto).
Modelos Multimodais: VLMs (Vision-Language Models)#
A geração mais recente combina um encoder visual (CNN ou ViT) com um LLM. O modelo recebe imagem e texto como entrada e responde em linguagem natural. Em vez de treinar um classificador específico para cada problema, fazemos a pergunta diretamente: “quantas pessoas há na foto?”, “descreva esta radiografia”, “extraia o texto desta nota fiscal”. Modelos como Gemini, GPT-4V, Claude com visão e seus equivalentes de código aberto (LLaVA, Qwen-VL) tornam viável resolver tarefas abertas (antes inviáveis sem grandes datasets anotados) com poucos exemplos ou apenas instruções em texto.
Por que estudar todas?#
Não há uma arquitetura “vencedora”: as três coexistem porque otimizam coisas diferentes. CNNs entregam baixa latência e baixo consumo; Transformers entregam acurácia e generalização em escala; VLMs entregam flexibilidade e raciocínio multimodal, ao custo de inferência cara. Escolher a ferramenta certa para o problema (e saber combiná-las) é parte central do trabalho em visão computacional hoje.
Começamos pelo pilar mais antigo e ainda mais usado: as redes neurais convolucionais.
Redes Neurais Convolucionais#
Como vimos na introdução, as CNNs foram o primeiro pilar do deep learning aplicado a imagens e seguem dominando aplicações em que latência e eficiência importam. A ideia central é simples: em vez de conectar cada pixel a cada neurônio (como faz uma rede densa), uma CNN aplica um pequeno conjunto de pesos compartilhados, o kernel, que percorre a imagem detectando o mesmo padrão em qualquer posição. Esse único princípio de projeto reduz drasticamente o número de parâmetros e introduz a equivariância a translação: reconhecer um gato no canto da imagem usa exatamente os mesmos pesos que reconhecê-lo no centro.
A operação de convolução#
A operação de convolução já foi apresentada no Capítulo 2 como uma técnica de processamento de imagens: um kernel (matriz de pesos K×K, com K ímpar) desliza sobre a imagem, multiplicando elemento a elemento e somando, para produzir um mapa de características (feature map) que destaca regiões onde o padrão do kernel está presente. Em uma CNN, a operação matemática é exatamente a mesma. O que muda é como o kernel surge.
A virada de chave: kernel aprendido
No Capítulo 2 os kernels eram definidos à mão (Sobel para bordas, Gaussiano para suavização). Em uma CNN, a rede aprende os pesos do kernel a partir dos dados de treino, por backpropagation, exatamente como aprende os pesos de uma camada densa. Curiosamente, filtros muito parecidos com Sobel costumam emergir nas primeiras camadas de redes treinadas em imagens naturais: a rede redescobre, por conta própria, que detectar bordas é um bom ponto de partida.
Três conceitos novos aparecem quando a convolução vira parte de uma rede neural:
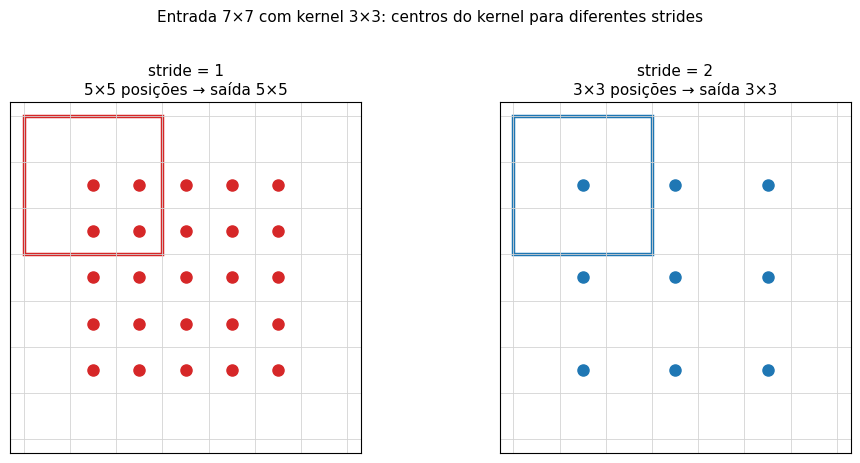
Stride. Quanto o kernel avança a cada passo. Stride 1 visita todas as posições; stride 2 pula uma, reduzindo a saída pela metade. Strides maiores são uma forma barata de reduzir a resolução espacial entre camadas.
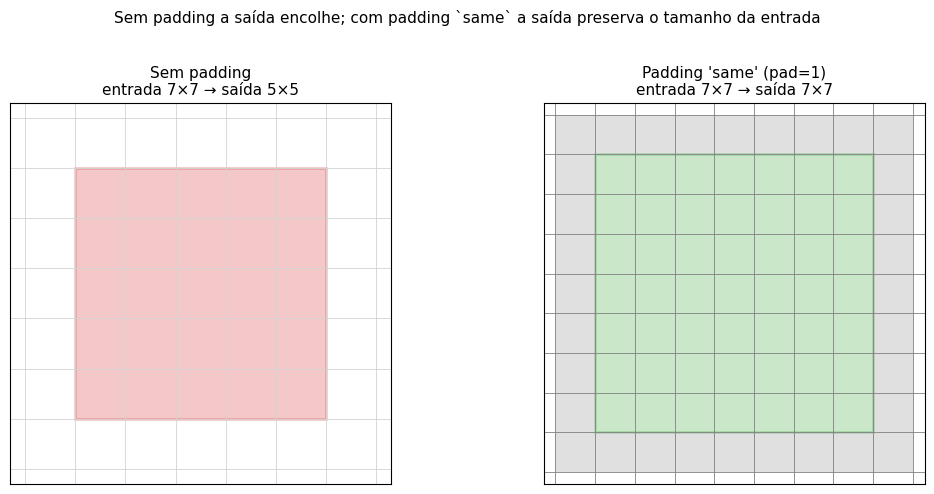
Padding. Bordas artificiais (geralmente zeros) adicionadas ao redor da imagem. Sem padding, a saída encolhe a cada camada. Uma imagem 32×32 com kernel 3×3 vira 30×30, depois 28×28, e assim por diante. Com padding same, a saída mantém o tamanho da entrada.
Múltiplos kernels, múltiplos canais. Uma camada convolucional não aplica um único kernel, mas dezenas ou centenas em paralelo, cada um aprendendo a detectar um padrão diferente. A saída é um tensor tridimensional (altura × largura × número de filtros), e a próxima camada convolucional opera sobre todos esses canais simultaneamente. É essa pilha de operações que constrói a hierarquia de representações que torna o deep learning poderoso: bordas → texturas → partes → objetos.

Antes de detalhar pooling e camadas densas, vale ver a CNN como um todo. A figura abaixo mostra o pipeline típico: a imagem de entrada passa por blocos sucessivos de convolução + pooling, onde cada bloco reduz a resolução espacial e aumenta o número de canais de features. Ao final desses blocos, chega-se a uma representação compacta. Essa representação é então achatada em um vetor e entregue a uma pequena rede densa, responsável pela decisão final. No exemplo da figura, a tarefa é classificar dígitos manuscritos do MNIST: o vetor de saída tem 10 posições, uma por dígito (0–9), e a posição com maior valor indica a previsão da rede.
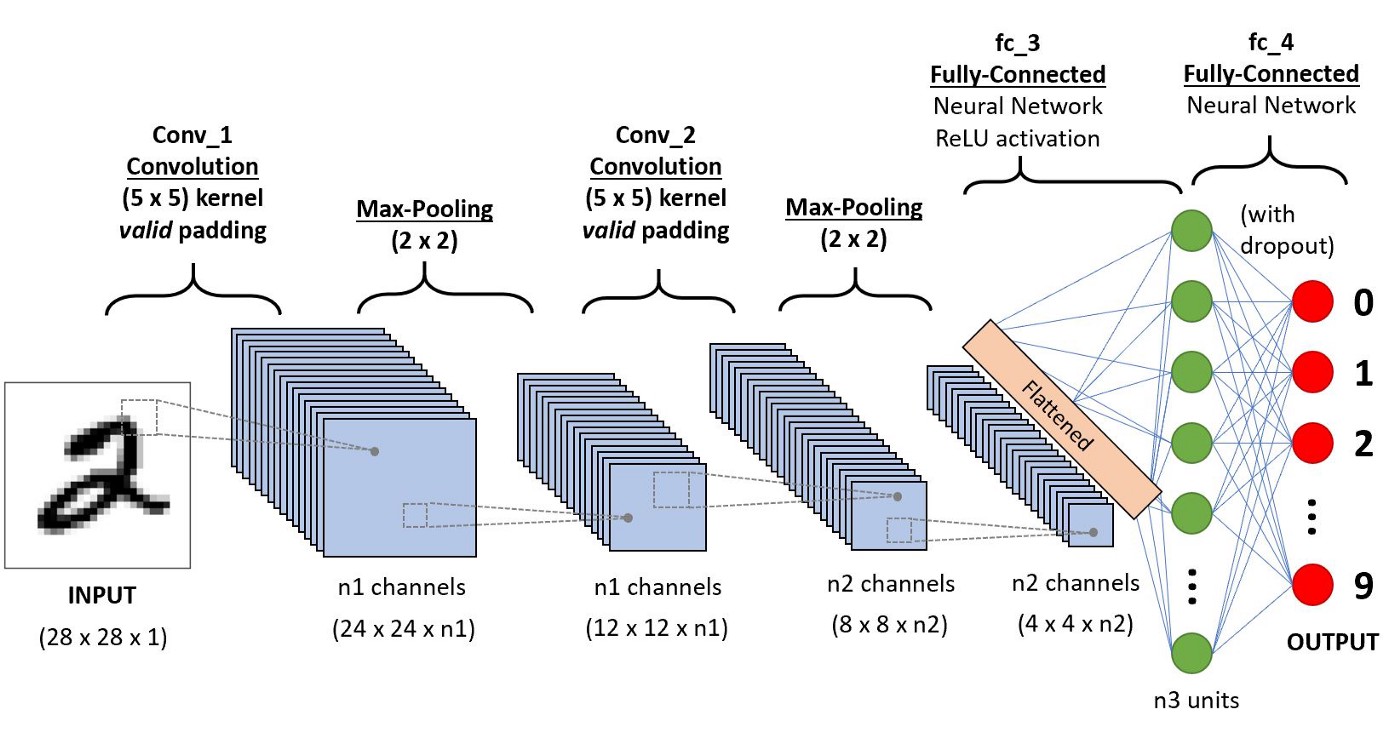
Fig. 1 Arquitetura típica de uma CNN: blocos de convolução + pooling extraem features progressivamente mais abstratas (bordas → texturas → partes), que são achatadas e classificadas por camadas densas. Fonte: Wikipedia.#
Para experimentar a convolução em uma CNN real e em tempo real, o demo do ConvNetJS treina uma rede pequena sobre o CIFAR-10 dentro do navegador, expondo os filtros aprendidos em cada camada. É uma forma rápida de visualizar o que diferentes kernels acabam detectando.
Camadas de pooling#
Depois das camadas convolucionais, costuma-se aplicar uma camada de pooling. Sua função é reduzir a resolução espacial do mapa de características, mantendo apenas a informação mais relevante de cada região. O resultado é uma representação mais compacta, com menor custo computacional nas camadas seguintes e maior robustez a pequenos deslocamentos do objeto na imagem.
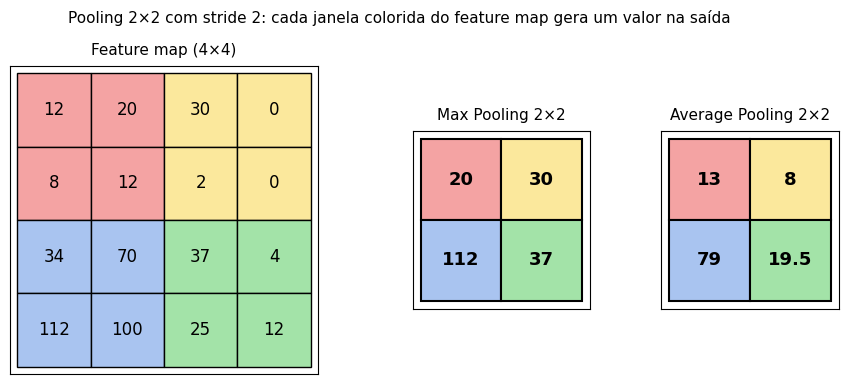
A operação é simples. Define-se uma janela (geralmente 2×2) e um stride igual ao tamanho da janela (no caso típico, stride 2). A janela percorre o mapa sem sobreposição, e cada posição produz um único valor na saída. O efeito é dividir altura e largura pela metade.
Max Pooling. Pega o valor máximo dentro da janela. Destaca as ativações mais fortes de cada região e descarta o resto. É o tipo mais usado em CNNs clássicas, especialmente nas primeiras camadas.
Average Pooling. Pega a média dos valores da janela. Produz uma saída mais suave, com sensibilidade menor a picos isolados. Costuma aparecer quando se quer preservar informação global em vez de máxima ativação local. Note que a média costuma gerar valores fracionários mesmo quando a entrada é inteira. Em uma CNN real, os mapas de características são floats em todo o pipeline.
Alternativa moderna: Global Average Pooling
Arquiteturas modernas (ResNet, EfficientNet, MobileNet) costumam substituir o bloco Flatten + camadas densas por uma única operação chamada Global Average Pooling (GAP). O GAP tira a média de cada canal inteiro do último mapa de características, produzindo um vetor com tamanho igual ao número de canais. Esse vetor segue direto para a camada de saída. A vantagem é eliminar milhões de parâmetros das camadas densas, reduzir o risco de overfitting e diminuir o tamanho do modelo final.
Flattening: transformando matrizes em vetores#
A última camada convolucional produz um tensor 3D com formato altura × largura × canais. As camadas densas, no entanto, esperam um vetor 1D na entrada. O flattening faz essa ponte: percorre o tensor em uma ordem fixa e concatena todos os valores em um único vetor linear.
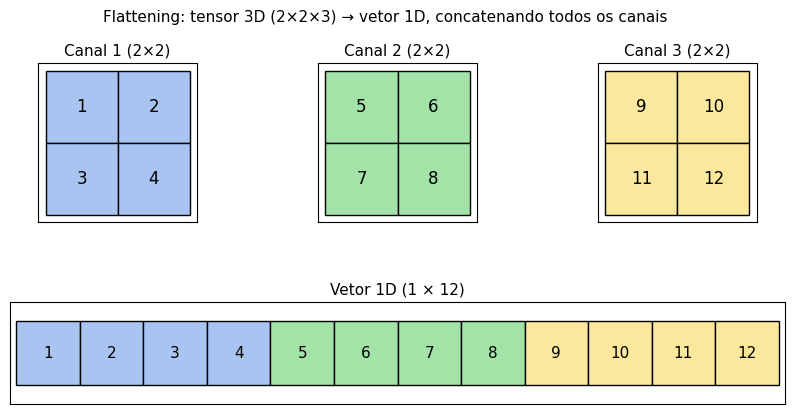
Em redes clássicas (LeNet, VGG, primeiras arquiteturas), o flatten é seguido por uma ou mais camadas densas grandes. Por exemplo, uma saída convolucional 7×7×512 produz um vetor de 25 088 elementos, conectado a uma camada densa de 4 096 neurônios. Isso sozinho gera mais de 100 milhões de parâmetros, dominando o tamanho da rede. Por essa razão, arquiteturas modernas costumam preferir o Global Average Pooling discutido acima, que produz um vetor muito menor (1 valor por canal) e elimina essa explosão de parâmetros.
Camadas totalmente conectadas#
Como vimos no Capítulo 3, em uma camada totalmente conectada (ou densa) cada neurônio recebe todos os valores da camada anterior, ponderados por pesos próprios. Em uma CNN, essas camadas aparecem depois do flatten (ou GAP) e cumprem o papel de converter as features visuais extraídas pelo bloco convolucional em uma decisão final.
A estrutura típica do “cabeçalho de classificação” de uma CNN é:
feature map → Flatten/GAP → Dense (ReLU) → Dropout → Dense (softmax) → probabilidades
A última camada densa tem tamanho igual ao número de classes do problema. Por exemplo, em uma rede treinada no MNIST a saída tem 10 neurônios, um por dígito. A ativação softmax transforma esses 10 valores em uma distribuição de probabilidade: cada um vira um número entre 0 e 1, e a soma dos 10 é igual a 1. A classe predita é o índice com maior probabilidade.
Dropout: regularização contra overfitting
Dropout é uma técnica de regularização que, durante o treino, desliga aleatoriamente uma fração dos neurônios de uma camada (tipicamente 30 a 50%). Cada batch vê uma rede ligeiramente diferente, o que força os neurônios a não dependerem demais uns dos outros. Em inferência, todos os neurônios voltam a operar normalmente. Dropout é praticamente padrão entre camadas densas em CNNs clássicas, justamente onde o risco de overfitting é maior por causa do alto número de parâmetros.
Recursos extras:
CNN Explainer - Visualização interativa
Dataset#
Um dataset é uma coleção organizada de amostras usada para treinar e avaliar modelos de machine learning. Em visão computacional, essas amostras são imagens (ou vídeos), normalmente acompanhadas de algum tipo de anotação que define o que a rede deve aprender: uma classe (classificação), caixas delimitadoras (detecção), máscaras (segmentação), ou um par com texto (modelos multimodais).
A qualidade e a quantidade dos dados costumam pesar tanto quanto a arquitetura escolhida. Um modelo simples treinado em um dataset bem curado tende a superar um modelo sofisticado treinado em dados ruidosos ou enviesados. Por isso, dedicar tempo à coleta e à limpeza dos dados é um investimento, não um custo.
Conjunto de treino, validação e teste#
Ao trabalhar com um dataset, é comum dividi-lo em três subconjuntos com papéis distintos. A figura abaixo mostra a divisão típica (70 % / 15 % / 15 %) e o que cada parte faz:

A regra de ouro é: o conjunto de teste deve ser usado apenas uma vez, ao final do projeto, para reportar o desempenho da rede. Se você ajustar hiperparâmetros olhando o teste, o número final deixa de ser uma estimativa honesta de generalização. É para isso que existe o conjunto de validação: dá feedback durante o desenvolvimento sem contaminar a medida final.
Overfitting
Overfitting ocorre quando o modelo aprende em excesso os detalhes e ruídos do conjunto de treino, perdendo capacidade de generalização. O sintoma clássico é alta acurácia no treino e baixa acurácia na validação ou teste. As principais defesas são: dataset maior, data augmentation, dropout, regularização L1/L2, e parar o treino antes que a curva de validação comece a piorar (early stopping).
Validação cruzada (cross-validation)#
A validação cruzada é uma técnica para estimar o desempenho de um modelo de forma mais confiável, especialmente quando o dataset é pequeno demais para reservar um conjunto de validação razoável.
Na forma mais comum, chamada k-fold cross-validation, o dataset é dividido em k partes iguais. O modelo é treinado k vezes, e cada iteração usa uma parte diferente como conjunto de teste, sendo as demais usadas para treino. A métrica final é a média das k execuções.

A vantagem da validação cruzada é usar todos os dados tanto para treino quanto para avaliação, ao custo de treinar k modelos em vez de um. Em deep learning, com datasets grandes (mais de 100 mil amostras) e treinos caros, raramente compensa. Mas em problemas com poucos dados, por exemplo imagens médicas com algumas centenas de exemplos por classe, é praticamente obrigatório.
Onde encontrar datasets#
A tabela abaixo lista os hubs mais usados em visão computacional hoje:
Site |
Descrição |
|---|---|
Hub principal para datasets de ML moderno (visão, NLP, multimodal). Integração direta com a biblioteca |
|
Datasets variados, notebooks com GPU/TPU gratuitos e competições. Boa fonte para baselines. |
|
Mais de 1 milhão de datasets específicos de visão computacional (detecção, segmentação, classificação), com anotações prontas em vários formatos. |
|
~9 milhões de imagens, com 15M caixas delimitadoras, 2.7M máscaras de segmentação e 61M labels em nível de imagem. |
|
~163 mil imagens em 80 categorias cotidianas, com caixas, máscaras de segmentação, keypoints e legendas. Benchmark padrão de detecção. |
|
14,2 milhões de imagens em 21.841 categorias. Berço da revolução do deep learning em visão. |
|
Catálogo de datasets organizados por tarefa, com benchmarks e papers associados. Útil para descobrir o estado da arte. |
|
Biblioteca com datasets prontos para uso em pipelines TF/Keras. |
Para tarefas comuns (classificação MNIST e CIFAR, detecção em COCO), praticamente todos os frameworks já trazem o dataset embutido. Basta uma linha de código para carregar:
# Keras
from tensorflow.keras.datasets import mnist, cifar10
# Hugging Face
from datasets import load_dataset
ds = load_dataset("cifar10")
Licenças de datasets#
Antes de baixar um dataset, vale checar a licença associada. Ela define o que você pode (e o que não pode) fazer com as imagens e com as anotações: usar em projeto comercial, publicar um modelo treinado, redistribuir, modificar. Em trabalhos puramente acadêmicos a tolerância é maior; em qualquer cenário que envolva produção, redistribuição ou monetização, ignorar esse passo costuma sair caro.
A tabela abaixo resume as licenças mais comuns em datasets de visão computacional:
Licença |
Uso comercial |
Modificação |
Redistribuição |
Exigência principal |
|---|---|---|---|---|
CC0 / Domínio público |
sim |
sim |
sim |
nenhuma |
CC BY 4.0 |
sim |
sim |
sim |
citar a fonte (autor, licença, link) |
CC BY-SA 4.0 |
sim |
sim |
sim |
citar; obra derivada precisa adotar a mesma licença |
CC BY-NC 4.0 |
não |
sim |
sim |
citar; uso restrito a fins não comerciais |
CC BY-ND 4.0 |
sim |
não |
sim |
citar; proibido publicar versões modificadas |
MIT / Apache 2.0 |
sim |
sim |
sim |
manter o aviso de licença (comum em código, raro em imagens) |
ODbL |
sim |
sim |
sim |
citar; derivados adotam ODbL (específica para bancos de dados) |
Research-only / termos próprios |
em geral não |
varia |
em geral não |
termos definidos pelos autores; comum em datasets clássicos (ImageNet, etc.) |
Algumas observações práticas que costumam pegar quem está começando:
A licença do dataset nem sempre cobre as imagens. Datasets como COCO e Open Images agregam fotos do Flickr. As anotações são liberadas em CC BY, mas cada imagem traz a licença do autor original. Reusar uma imagem específica exige checar essa segunda camada; algumas licenças do Flickr são mais restritivas do que a do dataset.
Modelo treinado herda restrições? Juridicamente é zona cinzenta e há litígios em andamento (Stability AI, GitHub Copilot). Por isso, pipelines comerciais hoje evitam datasets
NC(não comercial) e research-only. Em projetos pessoais ou acadêmicos, raramente é um obstáculo, mas convém deixar a procedência documentada.Datasets gerados por IA. Imagens sintéticas (Stable Diffusion, GANs, modelos generativos em geral) podem carregar as restrições do modelo gerador. A licença do dataset sintético não anula a do modelo que o produziu.
Datasets retirados do ar. Vários datasets de faces clássicos foram retirados pelos próprios autores por questões éticas e jurídicas (MS-Celeb-1M, Duke MTMC, MegaFace). Um link que existia ontem pode não existir mais; vale guardar
READMEe documentação localmente.
Quando a licença não estiver clara, prefira fontes que documentem essa informação no próprio card do dataset. Hugging Face e Roboflow Universe costumam ser explícitos; em Kaggle e repositórios universitários, a documentação varia bastante.
LGPD e proteção de dados#
Licença responde “posso usar este dataset?”. A pergunta complementar é: “posso tratar estas pessoas?”. No Brasil, isso é regido pela LGPD (Lei Geral de Proteção de Dados, Lei nº 13.709/2018), em vigor desde 2020. Para visão computacional, alguns pontos são essenciais:
Imagem de pessoa identificável é dado pessoal. A foto de um rosto, em resolução suficiente para reconhecer alguém, está protegida.
Biometria é dado pessoal sensível. Embeddings faciais, impressão digital, padrão de íris, marcha. Têm proteção reforçada e, em regra, exigem consentimento explícito do titular.
Bases legais para tratamento. A LGPD lista dez bases (art. 7º). As mais relevantes para ML são consentimento, legítimo interesse e pesquisa científica realizada por órgão de pesquisa, esta última com a obrigação de anonimizar sempre que possível.
Direitos do titular. Toda pessoa cujo dado é tratado pode pedir acesso, correção, anonimização ou eliminação. Atender a esse pedido sobre um modelo já treinado é tecnicamente difícil; vale considerar antes de treinar.
ANPD e penalidades. A Autoridade Nacional de Proteção de Dados fiscaliza e aplica multas que podem chegar a 2 % do faturamento ou R$ 50 milhões por infração.
Boas práticas para datasets e modelos de visão:
Anonimize sempre que possível. Desfoque rostos, placas, crachás. Manter rostos claros só quando é o objetivo do estudo (reconhecimento facial) e com base legal adequada.
Documente a procedência. Quem coletou, quando, com qual base legal. Esse registro é exigido pela LGPD e protege quem treina o modelo depois.
Cuidado com datasets de terceiros. Muito dataset público de faces foi montado por scraping sem consentimento. Usá-lo em produção no Brasil expõe o controlador, não o autor do dataset.
Domínios sensíveis. Saúde, educação, crianças e adolescentes têm exigências adicionais. Em dúvida, procure orientação jurídica.
Para um panorama mais amplo: na União Europeia o equivalente é o GDPR (2018); nos EUA não há lei federal unificada, mas regulações setoriais e estaduais (HIPAA, CCPA). Modelos com uso internacional precisam atender ao conjunto mais restritivo.
Aviso. Esta seção é uma introdução técnica e não substitui orientação jurídica especializada. Em projetos com risco a direitos (vigilância, decisões automatizadas, dados sensíveis), procure um(a) profissional da área.
Exercício de pesquisa: explorando datasets#
Escolha um tema em visão computacional que te interesse (por exemplo, placas de trânsito, plantas, células, gestos, animais, alimentos, raios-X) e encontre pelo menos dois datasets diferentes nos hubs apresentados acima que tratem desse tema. Preencha a tabela abaixo com o que conseguir levantar de cada um:
Dataset |
Origem (hub, ano) |
Tamanho |
Tipo de anotação |
Licença e qualidade |
|---|---|---|---|---|
? |
? |
? |
? |
? |
? |
? |
? |
? |
? |
Em sala, apresente brevemente o que encontrou: como os datasets diferem, qual deles você escolheria para um projeto pequeno e por quê.
Classificação no Fashion MNIST com Redes Convolucionais#
No exercício do Capítulo 3, uma rede neural densa simples no Fashion MNIST costuma atingir cerca de 88 % de acurácia no conjunto de teste. Aquela abordagem tinha um limite claro: cada imagem 28×28 era achatada em um vetor de 784 valores antes de entrar na rede, descartando toda a informação espacial entre pixels vizinhos. As CNNs preservam essa estrutura e tendem a fechar boa parte dessa diferença.
Nesta seção repetimos o mesmo problema com uma CNN e comparamos os resultados.
Carregando e preparando o dataset#
O Fashion MNIST traz 60 000 imagens de treino e 10 000 de teste, em tons de cinza, resolução 28×28, divididas em 10 classes de peças de roupa.
import tensorflow as tf
from tensorflow.keras import layers, models
import numpy as np
import matplotlib.pyplot as plt
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
# Normaliza para [0, 1]
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
# Conv2D espera tensores 4D: (batch, altura, largura, canais)
x_train = x_train[..., np.newaxis] # (60000, 28, 28, 1)
x_test = x_test[..., np.newaxis] # (10000, 28, 28, 1)
A normalização para [0, 1] ajuda na convergência do otimizador. A dimensão extra de canal (np.newaxis) é necessária porque Conv2D espera tensores 4D, mesmo para imagens em tons de cinza.
Visualizando algumas amostras:
plt.figure(figsize=(10, 2))
for i in range(10):
plt.subplot(1, 10, i + 1)
plt.imshow(x_train[i].squeeze(), cmap='gray')
plt.title(class_names[y_train[i]], fontsize=8)
plt.axis('off')
plt.show()
Arquitetura da CNN#
A rede usa dois blocos de convolução + pooling seguidos do clássico flatten + densas:
model = models.Sequential([
layers.Input(shape=(28, 28, 1)),
# Bloco 1: 32 filtros 3x3, pooling 2x2
layers.Conv2D(32, (3, 3), activation='relu', padding='same'),
layers.MaxPooling2D((2, 2)), # 28×28 → 14×14
# Bloco 2: 64 filtros 3x3, pooling 2x2
layers.Conv2D(64, (3, 3), activation='relu', padding='same'),
layers.MaxPooling2D((2, 2)), # 14×14 → 7×7
# Cabeçalho de classificação
layers.Flatten(), # 7×7×64 → vetor de 3136
layers.Dropout(0.3), # desliga 30 % dos neurônios no treino
layers.Dense(128, activation='relu'), # camada totalmente conectada
layers.Dense(10, activation='softmax'), # 10 probabilidades, uma por classe
])
model.summary()
Filtros aprendidos, não fixos
Os 32 filtros 3×3 do primeiro bloco (e os 64 do segundo) não são definidos à mão como os filtros de Sobel, Prewitt ou Gaussiano vistos no Capítulo 2. Cada filtro é uma matriz de pesos inicializada aleatoriamente e ajustada pelo otimizador durante o treino, junto com os pesos das camadas densas. Em vez de o projetista decidir “vou usar este kernel para detectar bordas”, a rede descobre sozinha quais filtros são úteis para o problema em questão: bordas, texturas, formas, ou padrões que sequer têm nome claro para um humano.
Pontos importantes da arquitetura:
padding='same'mantém a resolução espacial entre as convoluções (28×28 → 28×28). Quem reduz o tamanho é o pooling (28×28 → 14×14 → 7×7).O número de filtros dobra entre blocos (32 → 64). É um padrão comum: à medida que a resolução espacial diminui, aumenta-se o número de canais de features.
Dropout(0.3)desliga 30 % dos neurônios da camada densa durante o treino, combatendo o overfitting.A camada final tem 10 neurônios com softmax, produzindo uma probabilidade por classe.
Compilação e treinamento#
model.compile(
optimizer='adam', # ajusta o passo do gradiente por parâmetro
loss='sparse_categorical_crossentropy', # rótulos como inteiros (0..9), sem one-hot
metrics=['accuracy'], # métrica acompanhada a cada época
)
history = model.fit(
x_train, y_train,
epochs=10, # passa o dataset inteiro 10 vezes
batch_size=128, # 128 imagens por atualização de pesos
validation_split=0.1, # reserva 10 % do treino para validação
verbose=2, # uma linha de log por época
)
Adam: otimizador padrão, ajusta a taxa de aprendizado por parâmetro.
sparse_categorical_crossentropy: usa rótulos inteiros (0 a 9) diretamente, sem precisar de one-hot encoding.validation_split=0.1reserva 10 % do treino para acompanhar a curva de validação.
Avaliação no conjunto de teste#
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print(f"Acurácia no teste: {test_acc:.2%}")
Em uma execução típica, essa CNN atinge entre 91 % e 93 % de acurácia no teste, contra os ~88 % da rede densa do Capítulo 3.
Resultados#
Previsões em algumas amostras
predictions = model.predict(x_test[:10]) # 10 distribuições softmax sobre as 10 classes
plt.figure(figsize=(12, 2.5))
for i in range(10):
plt.subplot(1, 10, i + 1)
plt.imshow(x_test[i].squeeze(), cmap='gray')
pred = np.argmax(predictions[i])
true = y_test[i]
ok = '✓' if pred == true else '✗'
color = 'green' if pred == true else 'red'
plt.title(f"{ok} {class_names[pred]}\n({class_names[true]})",
fontsize=7, color=color)
plt.axis('off')
plt.suptitle('Previsões da CNN no Fashion MNIST (Previsto sobre Verdadeiro)')
plt.show()
Erros costumam aparecer em classes visualmente próximas: shirt contra T-shirt, pullover contra coat, sneaker contra sandal. Esses pares são os clássicos do Fashion MNIST e mostram que mesmo uma CNN tem limites quando duas categorias compartilham silhueta.
Curvas de acurácia e perda
fig, axes = plt.subplots(1, 2, figsize=(11, 4))
axes[0].plot(history.history['accuracy'], label='Treino')
axes[0].plot(history.history['val_accuracy'], label='Validação')
axes[0].set_title('Acurácia')
axes[0].set_xlabel('Época')
axes[0].set_ylabel('Acurácia')
axes[0].legend()
axes[1].plot(history.history['loss'], label='Treino')
axes[1].plot(history.history['val_loss'], label='Validação')
axes[1].set_title('Perda (loss)')
axes[1].set_xlabel('Época')
axes[1].set_ylabel('Loss')
axes[1].legend()
plt.tight_layout()
plt.show()
O comportamento esperado:
Acurácia de treino subindo continuamente. A acurácia de validação acompanha, com leve folga (a versão de treino fica um pouco acima).
Perda decrescente para ambas as curvas.
Se a curva de validação começar a subir enquanto a de treino continua descendo, é sinal de overfitting. Nesse caso, vale aumentar o
Dropout, reduzir o tamanho da rede, ou parar o treino mais cedo (early stopping).
Matriz de confusão
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
y_pred = np.argmax(model.predict(x_test), axis=1) # classe predita por imagem (índice do maior softmax)
cm = confusion_matrix(y_test, y_pred)
fig, ax = plt.subplots(figsize=(8, 7))
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=class_names)
disp.plot(ax=ax, cmap='Blues', xticks_rotation=45, values_format='d')
plt.title('Matriz de confusão: CNN no Fashion MNIST')
plt.tight_layout()
plt.show()
A diagonal concentra a grande maioria das amostras. Fora dela, dois blocos pequenos costumam aparecer: confusões entre classes da parte superior do vestuário (T-shirt, Shirt, Pullover, Coat) e, ocasionalmente, Sandal contra Sneaker.
Comparando com a rede densa do Capítulo 3#
Modelo |
Parâmetros aprox. |
Acurácia no teste |
|---|---|---|
Rede densa (Cap. 3) |
~100 K |
~88 % |
CNN (este capítulo) |
~420 K |
~92 % |
A CNN entrega cerca de 4 a 5 pontos percentuais a mais com parâmetros da mesma ordem de grandeza. O ganho vem da preservação da estrutura espacial: a rede passa a enxergar bordas, vincos e silhuetas, em vez de um vetor “anônimo” de 784 pixels.
Exercício prático: variando a arquitetura da CNN#
A CNN da seção anterior atinge cerca de 92 % de acurácia no Fashion MNIST. Este exercício investiga, na prática, quais decisões de projeto realmente movem o ponteiro e quais quase não fazem diferença.
A partir da CNN baseline, escolha 3 ou 4 variações e treine cada uma por 10 épocas. Em cada variação, altere um único elemento e mantenha o resto igual. Para que as comparações sejam justas, fixe a semente do gerador aleatório antes de construir o modelo:
import tensorflow as tf, numpy as np, random
SEED = 42
tf.random.set_seed(SEED); np.random.seed(SEED); random.seed(SEED)
Algumas sugestões de variação:
Dropout: experimente valores diferentes do baseline (
0.3). Por exemplo0.0,0.2,0.5.Otimizador: troque
adamporsgdourmsprop.Camadas de convolução: use apenas 1 bloco, ou adicione um terceiro (com mais filtros, por exemplo 128).
Outra variação à sua escolha: pesquise e proponha uma variação que faça sentido (ex.: tamanho do lote, data augmentation, normalização, função de ativação, número de neurônios da densa).
Para cada variação, registre:
Acurácia final no teste, em uma tabela com uma linha por variação (incluindo o baseline).
Curvas de treino e validação (acurácia e perda por época).
Uma observação curta sobre o que aconteceu: convergiu mais rápido, aumentou a folga entre treino e validação, estagnou, etc.
Em sala, comparamos os resultados. O objetivo não é encontrar a “melhor” CNN, e sim entender qual ingrediente da arquitetura é decisivo para este problema e qual é praticamente irrelevante. Em geral, o resultado não é o que a intuição prevê.
Arquiteturas Convolucionais Clássicas#
A CNN da seção anterior tem uma limitação prática: só vai longe enquanto for rasa. Empilhar muitas camadas convolucionais “puras” começa a piorar a precisão em vez de melhorar, fenômeno conhecido como degradação do treinamento (a rede mais profunda fica pior que a mais rasa) e que está conectado ao problema do vanishing gradient, em que o sinal do gradiente se dissolve antes de chegar nas primeiras camadas. Resolver isso, conseguir escalar para dezenas ou centenas de camadas, e fazer com que tudo isso rode em hardware modesto, foi o que motivou as três famílias de arquiteturas a seguir.
Para os exemplos práticos vamos usar PyTorch com torchvision (modelos pré-treinados no ImageNet) e timm (PyTorch Image Models, biblioteca com o catálogo mais completo de backbones modernos).
!pip install torch torchvision timm
Visão geral#
Modelo |
Ano |
Parâmetros |
Top-1 ImageNet |
Quando escolher |
|---|---|---|---|---|
ResNet-50 |
2015 |
25,6 M |
~76 % |
Baseline confiável, fácil de raciocinar |
EfficientNet-B0 |
2019 |
5,3 M |
~78 % |
Boa precisão por parâmetro, sem precisar de hardware móvel |
MobileNetV3-Large |
2019 |
5,4 M |
~75 % |
Dispositivos móveis e edge, baixa latência |
Os valores de precisão variam ligeiramente entre fontes (recipe de treino, crops usados na avaliação, versões dos pesos); use a documentação oficial de cada biblioteca para os números exatos.
Vamos usar a mesma imagem de teste para os três modelos, o que facilita comparar as predições:
import urllib.request
from PIL import Image
url = "https://upload.wikimedia.org/wikipedia/commons/thumb/4/4d/Cat_November_2010-1a.jpg/500px-Cat_November_2010-1a.jpg"
req = urllib.request.Request(url, headers={"User-Agent": "Mozilla/5.0"})
with urllib.request.urlopen(req) as resp, open("gato.jpg", "wb") as f:
f.write(resp.read())
img = Image.open("gato.jpg").convert("RGB")
ResNet (Residual Networks)#
A grande sacada da ResNet [He et al., 2016] foi introduzir as conexões residuais (também chamadas de skip connections ou atalhos). Em vez da camada aprender a função \(H(x)\) que mapeia entrada para saída, ela aprende o resíduo \(F(x) = H(x) - x\), com a saída final dada por:
Em outras palavras, se a camada não tiver nada útil a aprender, basta zerar \(F(x)\) e ela vira a identidade. Isso permite empilhar dezenas ou centenas de camadas sem que o gradiente “morra” durante o backpropagation. A ResNet original já vinha em variantes de 18, 34, 50, 101 e 152 camadas, e a ResNet-50 segue sendo o backbone padrão histórico em detecção (Faster R-CNN, Mask R-CNN) e segmentação.
graph LR
X[entrada x] --> Conv1[Conv 3x3]
Conv1 --> BN1[BN + ReLU]
BN1 --> Conv2[Conv 3x3]
Conv2 --> BN2[BN]
X -->|skip connection| Add(("+"))
BN2 --> Add
Add --> ReLU[ReLU]
ReLU --> Y[saida y]
Carregando uma ResNet-50 pré-treinada e classificando a imagem:
import torch
import matplotlib.pyplot as plt
from torchvision import models
weights = models.ResNet50_Weights.IMAGENET1K_V2
model = models.resnet50(weights=weights)
model.eval()
# Pré-processamento padrão do ImageNet (resize, center-crop, normalização)
preprocess = weights.transforms()
x = preprocess(img).unsqueeze(0)
with torch.no_grad():
probs = model(x).softmax(dim=1)[0]
classes = weights.meta["categories"]
# Helper reutilizado nos próximos modelos: mostra a imagem e as 5 classes mais prováveis
def mostrar_top5(img, probs, classes, titulo):
top5 = probs.topk(5)
labels = [classes[idx] for idx in top5.indices]
scores = [p.item() for p in top5.values]
fig, (ax_img, ax_bar) = plt.subplots(1, 2, figsize=(8, 3))
ax_img.imshow(img)
ax_img.set_title("Imagem de entrada")
ax_img.axis("off")
ax_bar.barh(labels[::-1], scores[::-1], color="#4C72B0")
ax_bar.set_xlim(0, 1)
ax_bar.set_xlabel("Probabilidade")
ax_bar.set_title(titulo)
fig.tight_layout()
plt.show()
mostrar_top5(img, probs, classes, "Top-5 ResNet-50")
O atributo weights.transforms() já devolve a sequência de transforms (resize, center crop, normalização ImageNet) que a torchvision usou no treino. Sempre pré-processe com o transform que veio com o peso: usar normalização errada degrada a precisão silenciosamente.
EfficientNet#
A EfficientNet [Tan and Le, 2019] parte de uma observação simples: ao escalar uma rede, é possível aumentar a profundidade (mais camadas), a largura (mais filtros por camada) ou a resolução de entrada. Antes da EfficientNet, esses três eixos eram tratados de forma ad hoc. A contribuição dos autores foi o compound scaling, que usa um único coeficiente \(\phi\) para escalar os três simultaneamente, em proporções fixas:
com \(\alpha \cdot \beta^2 \cdot \gamma^2 \approx 2\), garantindo que o crescimento de FLOPs por incremento de \(\phi\) seja controlado (cada \(+1\) em \(\phi\) aproximadamente dobra os FLOPs). Combinado a um bloco base inspirado no MobileNet (MBConv, com squeeze-and-excitation), o resultado é a família B0 a B7, que dominou o trade-off precisão × FLOPs por anos. A EfficientNet-B0 entrega precisão melhor que a ResNet-50 com cinco vezes menos parâmetros.
Inferência com EfficientNet-B0 via timm:
import timm
model = timm.create_model("efficientnet_b0", pretrained=True)
model.eval()
# O timm devolve o transform correto para o modelo carregado
config = timm.data.resolve_model_data_config(model)
preprocess = timm.data.create_transform(**config, is_training=False)
x = preprocess(img).unsqueeze(0)
with torch.no_grad():
probs = model(x).softmax(dim=1)[0]
# Reaproveitamos a lista de classes ImageNet do peso da torchvision
mostrar_top5(img, probs, classes, "Top-5 EfficientNet-B0")
A grande vantagem do timm é o catálogo: além das B0–B7 originais, ele expõe variantes como efficientnetv2_*, tf_efficientnet_* (com pesos do código TensorFlow original) e diversas combinações com pesos pré-treinados em datasets maiores que o ImageNet-1k.
MobileNet#
A família MobileNet [Howard et al., 2017] (e versões seguintes) foi pensada para rodar em dispositivos com restrição de recursos: celulares, microcontroladores, câmeras embarcadas. A inovação central é a convolução separável em profundidade (depthwise separable convolution), que fatora uma convolução padrão \(K \times K \times C_{in} \times C_{out}\) em duas etapas:
Depthwise: aplica um filtro \(K \times K\) independente em cada canal de entrada (sem misturar canais).
Pointwise: aplica uma convolução \(1 \times 1\) para combinar os \(C_{in}\) canais nos \(C_{out}\) canais de saída.
O custo computacional cai aproximadamente \(\tfrac{1}{C_{out}} + \tfrac{1}{K^2}\) vezes em relação à convolução padrão. Para \(K=3\) e \(C_{out}=64\), isso significa quase 9 vezes mais barato, com perda pequena de precisão. A MobileNetV3 [Howard et al., 2019] acrescenta blocos squeeze-and-excitation, ativações h-swish e usa busca de arquitetura neural (NAS) para refinar a topologia, oferecendo as variantes Small (ainda mais leve) e Large.
Inferência com MobileNetV3-Large:
weights = models.MobileNet_V3_Large_Weights.IMAGENET1K_V2
model = models.mobilenet_v3_large(weights=weights)
model.eval()
preprocess = weights.transforms()
x = preprocess(img).unsqueeze(0)
with torch.no_grad():
probs = model(x).softmax(dim=1)[0]
mostrar_top5(img, probs, weights.meta["categories"], "Top-5 MobileNetV3-Large")
Ao comparar as três saídas (ResNet, EfficientNet, MobileNet) sobre a mesma imagem, vale observar que as predições raramente são idênticas mesmo entre modelos confiáveis: cada arquitetura “vê” a imagem com um viés indutivo um pouco diferente.
Quando escolher cada uma#
Não existe “melhor arquitetura”: existe a que se encaixa melhor no problema. Algumas heurísticas para guiar a escolha:
ResNet quando você quer um baseline sólido, fácil de raciocinar, com vasta literatura, checkpoints pré-treinados em quase todo domínio (médico, satélite, microscopia) e backbone padrão de detectores históricos.
EfficientNet quando o orçamento de FLOPs/parâmetros é apertado mas você não está em hardware móvel; a família escala bem para problemas em que cada ponto de precisão importa.
MobileNet quando o modelo precisa rodar no celular, em câmeras embarcadas ou em latências muito baixas; aceite uma queda de alguns pontos em troca de inferência rápida e binário pequeno.
Para tarefas além de classificação (detecção, segmentação, pose estimation), essas arquiteturas viram backbones de modelos maiores. Compreender como uma ResNet ou MobileNet codifica uma imagem é pré-requisito para entender modelos como YOLOv11 e SAM, que vamos estudar no próximo capítulo.
Transformers de Visão#
As arquiteturas que vimos até aqui são todas convolucionais: o filtro percorre a imagem com um campo receptivo local que vai crescendo conforme empilhamos camadas. Isso embute um viés indutivo poderoso (vizinhança importa, equivariância à translação), mas custa caro quando o problema exige contexto global desde o início, como ocorre em segmentação semântica ou em cenas com relações de longa distância entre objetos.
Os transformers, criados originalmente para NLP, tratam a entrada como um conjunto de tokens e usam atenção para conectar qualquer token com qualquer outro. Adaptar essa ideia para imagens significa duas coisas: decidir o que é um token visual e lidar com o custo quadrático da atenção sobre milhares deles. As três arquiteturas abaixo respondem a essa pergunta de jeitos diferentes.
Os exemplos usam torchvision, timm e a biblioteca transformers da Hugging Face (necessária para o DETR):
!pip install torch torchvision timm transformers
Visão geral#
Modelo |
Ano |
Parâmetros |
Foco principal |
Métrica de referência |
|---|---|---|---|---|
ViT-B/16 |
2020 |
86 M |
Classificação |
~81 % top-1 ImageNet (pré-treino IN-21k) |
Swin-T |
2021 |
28 M |
Classificação + previsão densa |
~81 % top-1 ImageNet |
DETR (R50) |
2020 |
41 M |
Detecção de objetos |
~42 mAP COCO |
Continuamos com a mesma imagem-teste da seção anterior:
import urllib.request
from PIL import Image
url = "https://upload.wikimedia.org/wikipedia/commons/thumb/4/4d/Cat_November_2010-1a.jpg/500px-Cat_November_2010-1a.jpg"
req = urllib.request.Request(url, headers={"User-Agent": "Mozilla/5.0"})
with urllib.request.urlopen(req) as resp, open("gato.jpg", "wb") as f:
f.write(resp.read())
img = Image.open("gato.jpg").convert("RGB")
ViT (Vision Transformer)#
O ViT [Dosovitskiy et al., 2021] é a aplicação mais direta possível do transformer da literatura de NLP a imagens. A receita tem três passos:
Patchify: a imagem \(H \times W \times 3\) é dividida em \(N\) patches de tamanho \(P \times P\) (tipicamente \(P=16\)). Cada patch é achatado e projetado linearmente para um vetor de dimensão \(D\), virando um token visual.
Embeddings posicionais + token de classe: aos \(N\) tokens é prepended um token especial
[CLS](aprendido) e somados embeddings posicionais (também aprendidos), já que a atenção é, por padrão, invariante à ordem.Encoder transformer + head: a sequência passa por \(L\) camadas de auto-atenção multi-cabeça com MLP intercalado. O vetor de saída do token
[CLS]alimenta um classificador linear.
graph LR
Img[imagem<br/>HxWx3] --> Patch[divisao em<br/>patches PxP]
Patch --> Proj[projeção linear<br/>flatten + linear]
Proj --> Tokens[tokens visuais]
CLS[token CLS] --> Concat
Tokens --> Concat[concat]
Concat --> Pos[+ pos. embedding]
Pos --> Enc[L camadas<br/>self-attention + MLP]
Enc --> Head[MLP head]
Head --> Y[classe]
A consequência prática é que o ViT tem pouquíssimo viés indutivo para imagens: não há noção embutida de localidade nem de equivariância à translação. Em troca, ele se beneficia muito de mais dados, e supera CNNs equivalentes quando pré-treinado em datasets gigantes (ImageNet-21k, JFT-300M) e depois afinado em ImageNet-1k.
Inferência com ViT-B/16:
import torch
from torchvision import models
weights = models.ViT_B_16_Weights.IMAGENET1K_V1
model = models.vit_b_16(weights=weights)
model.eval()
preprocess = weights.transforms()
x = preprocess(img).unsqueeze(0)
with torch.no_grad():
probs = model(x).softmax(dim=1)[0]
classes = weights.meta["categories"]
mostrar_top5(img, probs, classes, "Top-5 ViT-B/16")
Swin Transformer#
O Swin [Liu et al., 2021] ataca o ponto fraco do ViT em previsão densa (detecção, segmentação): o ViT usa um único nível de resolução, e a atenção global custa \(O(N^2)\) no número de tokens, o que inviabiliza imagens grandes. Duas mudanças resolvem isso:
Atenção em janelas locais: em vez de calcular atenção entre todos os tokens, o Swin particiona o feature map em janelas não sobrepostas (por exemplo, \(7 \times 7\) tokens) e computa atenção dentro de cada janela. O custo cai para \(O(N)\) no número de tokens.
Shifted windows: para que tokens em janelas diferentes possam interagir, camadas alternadas deslocam o particionamento por metade do tamanho da janela. Assim a informação flui entre janelas sem o custo da atenção global.
Combinando isso com agrupamento progressivo de patches (patch merging) entre estágios, o Swin produz uma pirâmide de features parecida com a de uma CNN, o que o torna drop-in como backbone em FPNs, Mask R-CNN e UperNet. Hoje o Swin (e a evolução Swin-V2) é referência em segmentação semântica e instancia (Cityscapes, ADE20K, COCO).
Inferência com Swin-T via timm:
import timm
model = timm.create_model("swin_tiny_patch4_window7_224", pretrained=True)
model.eval()
config = timm.data.resolve_model_data_config(model)
preprocess = timm.data.create_transform(**config, is_training=False)
x = preprocess(img).unsqueeze(0)
with torch.no_grad():
probs = model(x).softmax(dim=1)[0]
# Reaproveitamos a lista de classes ImageNet da torchvision
mostrar_top5(img, probs, classes, "Top-5 Swin-T")
DETR (DEtection TRansformer)#
Os detectores que vamos estudar no capítulo 5 (YOLO em particular) dependem de uma engenharia delicada: caixas-âncora, non-max suppression, regressão de offsets. O DETR [Carion et al., 2020] propõe um pipeline end-to-end que dispensa essa parafernália. A arquitetura tem três peças:
Backbone CNN (tipicamente ResNet-50) que extrai um feature map da imagem.
Encoder-decoder transformer sobre esses features, semelhante ao da tradução automática.
Object queries: \(N\) vetores aprendidos (por exemplo, \(N=100\)) que percorrem o decoder e, ao final, são projetados em pares (classe, caixa).
O treinamento usa bipartite matching (algoritmo húngaro) entre as \(N\) predições e os ground-truths da imagem, garantindo que cada objeto da cena seja casado com uma única query. Não precisa de NMS no final: o próprio mecanismo de matching especializa as queries em objetos distintos.
O DETR é, ao mesmo tempo, simples conceitualmente e relevante historicamente: marcou o início de uma família de detectores baseados em transformer (Deformable-DETR, DINO, Grounding DINO) que hoje compete com YOLO e bate detectores de duas etapas em vários benchmarks.
Detecção com DETR-ResNet-50 via Hugging Face:
from transformers import DetrImageProcessor, DetrForObjectDetection
processor = DetrImageProcessor.from_pretrained("facebook/detr-resnet-50")
model = DetrForObjectDetection.from_pretrained("facebook/detr-resnet-50")
model.eval()
inputs = processor(images=img, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# Pós-processamento: filtra por confiança e converte para caixas em pixels
target_sizes = torch.tensor([img.size[::-1]]) # (H, W)
results = processor.post_process_object_detection(
outputs, target_sizes=target_sizes, threshold=0.7
)[0]
for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
cls = model.config.id2label[label.item()]
x1, y1, x2, y2 = [round(v, 1) for v in box.tolist()]
print(f"{cls:15s} conf={score.item():.2f} bbox=({x1}, {y1}, {x2}, {y2})")
Quando escolher cada uma#
ViT quando você tem (ou pode pré-treinar em) muitos dados e quer um backbone fácil de combinar com pipelines multimodais (CLIP, BLIP, VLMs em geral usam ViT no lado da imagem). Pouco apropriado para treinar do zero em datasets pequenos.
Swin quando o problema é de previsão densa (detecção, segmentação) ou quando você quer um transformer que se comporte como drop-in para CNNs em FPNs e Mask R-CNN.
DETR (e descendentes) quando você quer um pipeline de detecção simples, sem ancoras nem NMS, e está disposto a aceitar treinos mais longos. Para detecção em tempo real, o YOLO ainda costuma ser mais prático, como veremos no próximo capítulo.
Vale frisar que essa divisão (CNN clássica × transformer) é cada vez menos rígida. Modelos modernos como ConvNeXt e MaxViT combinam ideias dos dois mundos, e os backbones de VLMs (que vamos estudar a seguir) são quase sempre ViTs ou variantes dele.
LLMs de Visão e Uso de APIs#
Os Vision-Language Models (VLMs) combinam compreensão visual e textual em um único modelo, permitindo descrever imagens, responder perguntas sobre elas e realizar raciocínio multimodal. Modelos como Gemini (Google), Claude (Anthropic), GPT-4o (OpenAI) e Llama 3.2 Vision (Meta) tornaram acessíveis, via APIs, capacidades que antes exigiam pipelines complexos de visão.
Esses modelos são, na essência, LLMs (modelos de linguagem em larga escala) treinados também com bilhões de pares texto-imagem. Isso lhes permite raciocinar sobre uma imagem da mesma forma que sobre um documento de texto: você passa a imagem junto com uma instrução em linguagem natural (“descreva esta cena”, “liste os objetos”, “isso é uma fratura?”) e o modelo devolve uma resposta também em texto. A diferença em relação a um detector clássico como o YOLO é que o vocabulário não está restrito a um conjunto fixo de classes; o modelo é capaz de responder em linguagem aberta.
A família Gemini#
Gemini é a família multimodal do Google DeepMind. A evolução foi rápida: o Gemini 1.0 (final de 2023) já era multimodal nativo, aceitando texto e imagens; o 1.5 (2024) introduziu janelas de contexto de até 2 milhões de tokens e ampliou o suporte a vídeo e áudio; a série 2.x consolidou as variantes Flash (baixa latência) e Pro (raciocínio profundo); e a partir do Gemini 3 (final de 2025) o foco passou a ser uso agêntico e ferramentas, com versões intermediárias como 3.1 Pro e a família 3.5 (Flash e Pro), que combinam contexto de 1 milhão de tokens com capacidades agênticas e um modo Deep Think para problemas científicos. Como a versão mais nova muda a cada poucos meses, vale conferir os nomes atuais em ai.google.dev/models. Nos exemplos a seguir usamos gemini-2.5-flash, a versão rápida e barata, suficiente para descrição e análise de imagens. Para tarefas que exigem raciocínio mais profundo (laudo de exame, análise técnica), troque por gemini-2.5-pro.
Você pode testar os modelos diretamente no Google AI Studio, que oferece uma interface web para experimentar prompts antes de partir para a API.
Acessando VLMs via OpenRouter#
Cada provedor mantém um SDK próprio (google.genai, anthropic, openai, etc.). Quando o objetivo é comparar VLMs entre si ou alternar entre eles sem reescrever código, vale usar o OpenRouter, uma camada de API unificada compatível com o protocolo da OpenAI. Você cria uma única chave e o OpenRouter encaminha as requisições para o provedor escolhido (Google, Anthropic, OpenAI, Meta, Mistral, xAI, entre outros), cobrando por token com markup pequeno.
O exemplo abaixo descreve a mesma imagem em quatro VLMs trocando apenas a string do modelo. Confira a lista atualizada de modelos em openrouter.ai/models antes de copiar os identificadores:
import base64
import os
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key=os.environ["OPENROUTER_API_KEY"],
)
with open("gato.jpg", "rb") as f:
img_b64 = base64.b64encode(f.read()).decode()
modelos = {
"Gemini": "google/gemini-3-flash-preview",
"Claude": "anthropic/claude-sonnet-4.5",
"GPT-4o": "openai/gpt-4o",
"Llama": "meta-llama/llama-3.2-90b-vision-instruct",
}
for nome, model_id in modelos.items():
resp = client.chat.completions.create(
model=model_id,
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "Descreva esta imagem em duas frases."},
{"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{img_b64}"}},
],
}],
)
print(f"\n--- {nome} ---")
print(resp.choices[0].message.content)
Essa abordagem é especialmente útil em pesquisa: o mesmo prompt roda em quatro VLMs diferentes e as descrições podem ser comparadas lado a lado, sem precisar de quatro SDKs nem quatro chaves.
Exemplo prático: descrição de imagem com o SDK do Gemini#
Se você prefere usar o SDK nativo do Google (sem passar pelo OpenRouter), o fluxo é semelhante. Instale google-genai, configure a chave de API e envie a imagem como parte do conteúdo:
!pip install -U -q google-genai
import os
from google import genai
from google.genai import types
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
with open("gato.jpg", "rb") as f:
image_bytes = f.read()
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=[
types.Part.from_bytes(data=image_bytes, mime_type="image/jpeg"),
"Descreva esta imagem em detalhes.",
],
config=types.GenerateContentConfig(
system_instruction="Você é um assistente especializado em descrição detalhada de imagens.",
temperature=0.4,
),
)
print(response.text)
A chave da API pode ser obtida gratuitamente em aistudio.google.com. No Google Colab basta armazená-la em userdata e exportá-la como variável de ambiente antes de instanciar o cliente.
Variando apenas o prompt textual é possível extrair informações qualitativas e quantitativas da mesma imagem sem treinar nenhum modelo: “liste todos os objetos visíveis”, “descreva o humor das pessoas na cena”, “estime o número de pedestres”, “isso pode ser uma radiografia anormal?”. Para análises mais técnicas (radiografias, imagens científicas, mapas), considere subir para gemini-2.5-pro ou comparar com o Claude, que costuma ser mais conservador em domínios sensíveis.
Ferramentas para Anotação de Dados#
Modelos supervisionados como CNNs e detectores (YOLO, DETR) precisam de dados rotulados. Para classificação, o rótulo é apenas uma classe por imagem; para detecção, segmentação e tracking, o rótulo precisa codificar posição e forma de cada instância (caixa, polígono, máscara). É essa segunda categoria que torna a anotação trabalhosa, e foi por isso que surgiu um ecossistema de ferramentas dedicadas.
Formatos comuns de anotação#
Três formatos dominam o mercado e a maioria das ferramentas exporta para ao menos um deles:
YOLO: um arquivo
.txtpor imagem, com uma linha por objeto:<classe> <x_centro> <y_centro> <largura> <altura>, todos normalizados em [0, 1]. Compacto e direto, é o padrão de fato dos detectores em tempo real (YOLOv5, v8, v11).COCO: um único
.jsoncom a estrutura completa (images,annotations,categories) seguindo o schema do dataset COCO original. Suporta bounding boxes, polígonos de segmentação e keypoints. É o formato esperado pela maioria dos pipelines de pesquisa (Detectron2, MMDetection,transformersda Hugging Face).Pascal VOC: um
.xmlpor imagem, mais verboso que o YOLO mas mais legível para humanos. Conserva metadados como dimensões originais, autor e dificuldade do objeto. Ainda comum em datasets clássicos e em muitas ferramentas mais antigas.
Ao escolher uma ferramenta, vale verificar se ela exporta diretamente para o formato que o seu pipeline de treino consome. A conversão manual entre formatos é fácil mas propensa a erros silenciosos (coordenadas trocadas, classes deslocadas em uma posição, normalização ausente).
Comparação de ferramentas#
A tabela abaixo compara algumas das ferramentas mais usadas, considerando hospedagem, tipos de anotação suportados, automação e formatos de exportação:
Ferramenta |
Tipo |
Hospedagem |
Tipos de Anotação |
Recursos Adicionais |
Formatos de Exportação |
|---|---|---|---|---|---|
Freemium |
Nuvem |
Bounding boxes, segmentação |
Augmentations automáticas, versionamento, integração com Git |
YOLO, COCO, Pascal VOC, CSV |
|
Comercial |
Nuvem |
Bounding boxes, polígonos, keypoints, segmentação |
Automação com IA, revisão em equipe, API REST |
COCO, JSON, outros customizáveis |
|
Gratuito, open-source |
Local (navegador) |
Bounding boxes, polígonos, pontos |
Sem necessidade de servidor, extensível com JS |
JSON, CSV, customizados |
|
Freemium |
Nuvem |
Bounding boxes, segmentação, keypoints |
IA assistida, dashboards, controle de papéis, CI/CD |
YOLO, COCO, outros |
|
Gratuito |
Navegador |
Bounding boxes, polígonos, keypoints |
Uso anônimo, sem upload para servidores |
YOLO, VOC XML, VGG JSON, CSV |
|
Gratuito, open-source |
Local ou Nuvem |
Multimodal (imagem, texto, áudio, vídeo) |
Projetos via JSON, auto-label com IA, self-hosted |
JSON, CSV, customizável |
|
Gratuito, open-source |
Local ou Nuvem (Docker) |
Bounding boxes, segmentação, keypoints, tracking |
Suporte colaborativo, integração com OpenVINO, plugins |
COCO, YOLO, XML, etc. |
|
Gratuito, open-source |
Local ou Nuvem |
Bounding boxes, segmentação, tracking |
Interface web simples, suporte a vídeo e 3D |
JSON, COCO |
|
Comercial |
Nuvem |
Bounding boxes, texto, áudio, vídeo |
IA assistida, controle de qualidade, revisão |
JSON, outros |
|
Gratuito, open-source |
Local (Docker) |
Pose (keypoints) em vídeo |
Extração de frames de vídeo, fluxo multiusuário, foco em pesquisa |
JSON, CSV, YOLO-pose, COCO |
Algumas observações sobre os trade-offs entre essas ferramentas: soluções 100% locais como VIA e CVAT são preferíveis em domínios com restrição de privacidade (imagens médicas, dados internos de empresa), enquanto Roboflow, SuperAnnotate e Kili compensam o envio para a nuvem com pré-anotação assistida por IA, que acelera bastante o trabalho em datasets grandes. Para anotação multimodal (texto, áudio ou vídeo junto da imagem), Label Studio e Kili saem na frente; e quando o problema é de vídeo com poses, NeoLabel e Scalabel são pensados para esse caso.
Para tarefas como segmentação semântica em exames médicos ou anotação de keypoints, vale também considerar pré-anotação com VLMs (Gemini, Claude), seguida de revisão humana. O modelo gera uma primeira passada (caixas ou descrições de regiões) e o anotador apenas corrige, em vez de marcar do zero. Esse fluxo híbrido vem se tornando padrão em pipelines de produção.
Referências e Conteúdo Extra#
Anotação de Dados
Vídeos
Ferramentas
Bibliografia#
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In European Conference on Computer Vision (ECCV), 213–229. 2020. URL: https://arxiv.org/abs/2005.12872.
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: transformers for image recognition at scale. In International Conference on Learning Representations (ICLR). 2021. URL: https://arxiv.org/abs/2010.11929.
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–778. 2016. URL: https://arxiv.org/abs/1512.03385.
Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, and Hartwig Adam. Searching for MobileNetV3. In IEEE/CVF International Conference on Computer Vision (ICCV), 1314–1324. 2019. URL: https://arxiv.org/abs/1905.02244.
Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861, 2017. URL: https://arxiv.org/abs/1704.04861.
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: hierarchical vision transformer using shifted windows. In IEEE/CVF International Conference on Computer Vision (ICCV), 10012–10022. 2021. URL: https://arxiv.org/abs/2103.14030.
Mingxing Tan and Quoc V. Le. Efficientnet: rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning (ICML), 6105–6114. 2019. URL: https://arxiv.org/abs/1905.11946.