Capítulo 3: Machine Learning#

O que é Inteligência Artificial?#
Inteligência Artificial (IA) é o campo da ciência da computação que estuda como construir sistemas capazes de executar tarefas que tradicionalmente exigiam inteligência humana — perceber, raciocinar, aprender, decidir e se comunicar.
Neste capítulo, vamos trabalhar num subconjunto específico da IA: o aprendizado de máquina (machine learning), e em particular com redes neurais. Antes, vale situar como essas ideias se encaixam:
%%{init: {"flowchart": {"htmlLabels": true, "curve": "basis"}, "themeVariables": {"fontSize": "12px"}} }%%
flowchart TB
IA["<b>Inteligência Artificial</b><br/><span style='font-size:0.85em'>Sistemas que exibem comportamento inteligente</span>"]
ML["<b>Machine Learning</b><br/><span style='font-size:0.85em'>Aprende padrões a partir de dados</span>"]
DL["<b>Deep Learning</b><br/><span style='font-size:0.85em'>Redes neurais com muitas camadas</span>"]
GEN["<b>IA Generativa</b><br/><span style='font-size:0.85em'>Cria imagens, texto, áudio, vídeo</span>"]
AG["<b>Agentes</b><br/><span style='font-size:0.85em'>Planejam e executam tarefas</span>"]
IA --> ML --> DL
DL --> GEN
DL --> AG
Note
Onde a Visão Computacional entra? A visão computacional moderna é majoritariamente baseada em deep learning. Os modelos deste livro — classificadores, detectores, segmentadores — são redes neurais profundas. Este capítulo é pré-requisito direto do Capítulo 4.
Contexto Histórico#
A IA não nasceu com o ChatGPT. Sua história se entrelaça com a da própria computação, e entender os marcos ajuda a situar por que vivemos hoje a “era do deep learning”:
%%{init: {"flowchart": {"htmlLabels": true, "curve": "basis"}, "themeVariables": {"fontSize": "16px"}} }%%
flowchart TB
subgraph E1["Era Fundacional"]
direction LR
A1["<b>1950</b><br/>Teste de Turing"] --> A2["<b>1956</b><br/>Dartmouth<br/><i>nasce o termo IA</i>"] --> A3["<b>1958</b><br/>Perceptron<br/><i>Rosenblatt</i>"] --> A4["<b>1966</b><br/>ELIZA<br/><i>Weizenbaum</i>"]
end
subgraph E2["Retomada"]
direction LR
B1["<b>1986</b><br/>Backpropagation<br/><i>popularizado</i>"] --> B2["<b>1998</b><br/>LeNet-5<br/><i>primeira CNN prática</i>"]
end
subgraph E3["Big Bang do Deep Learning"]
direction TB
subgraph E3R1[" "]
direction LR
C1["<b>2012</b><br/>AlexNet"] --> C2["<b>2014</b><br/>GANs"] --> C3["<b>2017</b><br/>Transformer"] --> C4["<b>2020</b><br/>Vision Transformer"] --> C5["<b>2021</b><br/>CLIP"]
end
subgraph E3R2[" "]
direction LR
C6["<b>2022</b><br/>ChatGPT<br/>Stable Diffusion"] --> C7["<b>2023</b><br/>GPT-4, SAM,<br/>Llama"] --> C8["<b>2024</b><br/>Sora, Gemini,<br/>Claude 3"] --> C9["<b>2025</b><br/>DeepSeek-R1"]
end
C5 --> C6
end
classDef invisSub fill:none,stroke:none
class E3R1,E3R2 invisSub
E1 --> E2 --> E3
A era fundacional (1950 – 1970)#
1950 — Teste de Turing. Alan Turing propõe um critério operacional para avaliar se uma máquina “pensa”: ela passa no teste se uma pessoa, trocando mensagens cegas, não conseguir distinguir se do outro lado está um humano ou um programa.

1956 — Conferência de Dartmouth. McCarthy, Minsky, Shannon e Rochester organizam um workshop de dois meses em Dartmouth. É ali que o termo Inteligência Artificial é cunhado oficialmente.
1958 — Perceptron. Frank Rosenblatt constrói o primeiro modelo treinável inspirado em neurônios biológicos. O New York Times daquele ano descreveu-o como “a máquina que vai andar, falar, ver e se reproduzir” — otimismo que logo cobraria seu preço. Você encontrará esse mesmo modelo, em forma matemática, nas próximas seções.
1966 — ELIZA. Joseph Weizenbaum, do MIT, cria o primeiro chatbot da história. ELIZA simulava um psicoterapeuta de escola rogeriana por meio de regras simples de pattern matching — respondia a “estou triste” com “por que você está triste?”. O próprio Weizenbaum ficou alarmado ao perceber que usuários atribuíam empatia genuína ao programa, fenômeno que passou a ser chamado de “efeito ELIZA” — nossa tendência a projetar inteligência em qualquer sistema que responda de forma coerente. O efeito ELIZA segue vivo na era dos LLMs (Large Language Models).
Inverno e renascimento (1970 – 2010)#
Depois do otimismo fundacional, a IA entrou em duas décadas difíceis. Em 1969, Minsky e Papert publicam Perceptrons, demonstrando formalmente a incapacidade do modelo de Rosenblatt de resolver problemas tão simples quanto o XOR. O livro (e a reação que provocou) funcionou como gatilho do primeiro inverno da IA (1974 – 1980): financiamento secou, laboratórios fecharam, redes neurais saíram de moda.
Nos anos 1980, surgem os sistemas especialistas — programas que codificavam conhecimento humano em regras se/então. O MYCIN (diagnóstico de infecções) e o XCON (configuração de computadores DEC) chegaram a gerar valor comercial, e o ambicioso Projeto de Quinta Geração japonês mobilizou bilhões. Mas, no fim da década, a euforia desabou — os sistemas não escalavam para além dos nichos em que foram treinados — precipitando o segundo inverno (final dos 80, início dos 90).
O renascimento começou em 1986, quando Rumelhart, Hinton e Williams popularizam o algoritmo backpropagation. Pela primeira vez, tornava-se prático treinar redes com múltiplas camadas ocultas. Ainda assim, o resto da década foi dominado por métodos estatísticos: SVMs (Vapnik, 1995), random forests e boosting — o ecossistema do que hoje chamamos de machine learning clássico.
Em 1998, Yann LeCun publica a LeNet-5 — primeira CNN de uso prático, aplicada à leitura de cheques bancários. Pequena (apenas 60 mil parâmetros), ela já continha os ingredientes da arquitetura que dominaria a visão computacional 15 anos depois: convoluções, pooling e camadas densas.
Os palcos estavam sendo montados para a próxima revolução. Faltavam três coisas: dados em massa, GPUs e uma nova geração disposta a apostar em redes profundas. As três convergiriam em 2012.
O Big Bang do Deep Learning (2012 – presente)#
Em setembro de 2012, a equipe de Krizhevsky, Sutskever e Hinton vence o ImageNet Large Scale Visual Recognition Challenge com uma CNN profunda, a AlexNet, derrubando o erro em mais de 40 % em relação aos métodos clássicos. Três ingredientes se encaixaram: ImageNet (Fei-Fei Li, 2009) fornecia os dados (1,2 milhão de imagens anotadas), GPUs NVIDIA forneciam o compute, e a AlexNet trouxe truques decisivos — ReLU, dropout e data augmentation. Era o marco zero do deep learning moderno.
Nos anos seguintes, as CNNs (Convolutional Neural Networks) dominaram a visão computacional. VGG (2014) mostrou que ir mais fundo funcionava; GoogLeNet / Inception (2014) introduziu módulos paralelos para eficiência; ResNet (2015) resolveu o problema do vanishing gradient com conexões residuais e viabilizou redes de mais de 100 camadas, vencendo o ImageNet com erro abaixo do humano. Em paralelo, a U-Net (2015) se tornaria a arquitetura padrão para segmentação — hoje ainda dominante em imagens médicas.
Em 2014, Goodfellow et al. introduzem as GANs (Generative Adversarial Networks) — dois modelos em competição — inaugurando a era da geração de imagens por rede neural. Três anos depois, em 2017, Vaswani et al. publicam “Attention is All You Need” e apresentam o Transformer. Originalmente proposto para tradução automática, viria a substituir CNNs e RNNs (Recurrent Neural Networks) em praticamente todas as tarefas de IA.
Em 2020, Dosovitskiy et al. mostram que a mesma arquitetura — sem convoluções — supera CNNs quando treinada em larga escala. É o Vision Transformer (ViT). No ano seguinte, CLIP alinha texto e imagem no mesmo espaço vetorial, fundando a era dos modelos multimodais.
2022 foi o ponto de virada para o grande público: o Stable Diffusion (agosto) democratizou a geração de imagens, e o ChatGPT (novembro) levou os LLMs ao mainstream. A partir dali, o campo acelerou vertiginosamente:
2023 — GPT-4 (OpenAI), SAM (Meta, segmentação universal), Llama e Llama 2 (Meta, abertos), Claude (Anthropic), Mistral (modelos abertos compactos).
2024 — Sora (OpenAI, vídeo), Gemini 1.5 (Google, contexto longo), Claude 3, Llama 3; proliferam os modelos multimodais (texto + imagem + áudio).
2025 — DeepSeek-R1 (raciocínio a baixo custo, código aberto), modelos o-series da OpenAI (cadeias longas de pensamento), e a ascensão dos agentes autônomos que usam ferramentas e operam navegadores.
Tip
Os três pilares da era atual
Dados em escala — ImageNet, LAION-5B, Common Crawl.
Poder computacional — GPUs e TPUs massivamente paralelas.
Algoritmos — arquiteturas (CNNs, Transformers) e técnicas de treinamento (backprop, Adam, dropout, batch norm).
Remova qualquer um dos três e a revolução não acontece.
Exercício de Reflexão: Os Arquitetos da IA#
Antes de seguir para as fronteiras atuais, vale parar e conhecer as pessoas por trás da trajetória que acabamos de percorrer. Boa parte do seu futuro trabalho em visão computacional e IA em geral dependerá de decisões e descobertas feitas por esses pesquisadores.
Tarefa. Em grupos de 2–3 pessoas (ou individualmente), escolham 3 nomes — um de cada era — e preparem uma apresentação de 5 minutos ou um texto de 1 página respondendo:
O quê? Qual foi a contribuição concreta (artigo, algoritmo, sistema)?
Como? Em que contexto — instituição, colaboradores, recursos, momento histórico da computação?
E hoje? Como essa contribuição aparece no que usamos em 2025 — ChatGPT, Stable Diffusion, visão computacional, agentes?
O que deu certo, o que deu errado? Houve hype e decepção? A pessoa previu o futuro ou desistiu cedo demais?
Nomes sugeridos (escolha um de cada coluna):
Era Fundacional (1950 – 1970) |
Inverno & Retomada (1970 – 2010) |
Big Bang (2012 – presente) |
|---|---|---|
Alan Turing |
Geoffrey Hinton |
Geoffrey Hinton |
John McCarthy |
Yann LeCun |
Yann LeCun |
Marvin Minsky |
David Rumelhart |
Fei-Fei Li |
Claude Shannon |
Vladimir Vapnik |
Ian Goodfellow |
Frank Rosenblatt |
Jürgen Schmidhuber |
Ilya Sutskever |
Joseph Weizenbaum |
Fei-Fei Li (ImageNet, 2009) |
Alec Radford |
Ashish Vaswani |
Tip
Perguntas para guiar o debate
Hinton aparece 3 vezes na tabela (anos 80 com backprop, 2012 com AlexNet, Nobel de Física em 2024). O que essa longevidade diz sobre como se constrói uma carreira em pesquisa de fronteira?
O Perceptron (1958) foi anunciado com euforia e quase enterrou o campo em 1969 com a crítica de Minsky e Papert. O ChatGPT (2022) também chegou com uma onda de hype comparável. Há paralelo? O que os ciclos de hype / inverno ensinam?
Weizenbaum, criador do ELIZA, virou um dos primeiros críticos públicos dos riscos da IA ainda nos anos 1970. Geoffrey Hinton saiu do Google em 2023 justamente para poder falar abertamente sobre o que o deep learning pode trazer de perigoso. Qual o papel do cientista em alertar sobre os riscos da sua própria criação? O que muda quando o alerta vem de dentro?
O Transformer (2017) foi proposto para tradução automática — hoje é a base de quase tudo em IA moderna, do ChatGPT ao ViT e ao Stable Diffusion. Quantas descobertas em IA vieram de objetivos específicos e quantas de acidentes felizes? O que isso diz sobre como planejar e financiar pesquisa de fronteira?
Apenas uma mulher aparece na lista (Fei-Fei Li, em duas eras). Investiguem: a história da IA é mesmo assim tão masculina, ou faltam figuras reconhecidas que deveríamos estar citando?
Redes Generativas e Agentes Autônomos: A Nova Fronteira da IA#
Se o deep learning tradicional é sobre reconhecer padrões (classificar, detectar, segmentar), a fronteira recente é sobre gerar conteúdo — e, mais recentemente, agir no mundo.
%%{init: {"flowchart": {"htmlLabels": true, "curve": "basis"}, "themeVariables": {"fontSize": "14px"}} }%%
flowchart LR
GEN["<b>Modelos Generativos</b><br/>GAN · VAE · Diffusion"]
FOUND["<b>Foundation Models</b><br/>LLMs · VLMs · Multimodal<br/><i>GPT, Claude, Gemini, Sora, SAM</i>"]
AG["<b>Agentes Autônomos</b><br/>Foundation Model + Ferramentas<br/>+ Memória + Planejamento"]
GEN -.->|base técnica| FOUND -->|compõem| AG
Modelos Generativos#
A primeira onda foram as GANs — Generative Adversarial Networks (Goodfellow et al., 2014) — dois modelos competindo (gerador × discriminador) até o gerador produzir amostras indistinguíveis das reais. Vieram depois os VAEs — Variational Autoencoders (Kingma & Welling, 2013), de base probabilística, e os Modelos de Difusão (Ho et al., 2020), que hoje dominam a geração de imagens (Stable Diffusion, Midjourney, DALL·E 3) e vídeo (Sora, Veo).
Foundation Models#
A partir de 2022 consolidou-se uma nova classe: modelos de base — redes enormes, treinadas em volumes massivos de dados, adaptáveis a muitas tarefas. Os LLMs (GPT-4, Llama, Claude, Gemini, DeepSeek-V3/R1) lidam com texto e, crescentemente, múltiplas modalidades — são as VLMs (Vision-Language Models), como CLIP, GPT-4V e Gemini, que combinam texto e imagem no mesmo modelo. Em visão computacional, o SAM (Segment Anything) da Meta se tornou o modelo de base para segmentação.
Um marco recente é o DeepSeek-R1 (2025), que mostrou ser possível obter capacidade de raciocínio (cadeias longas de pensamento) em LLMs de código aberto com custo bem abaixo do estado da arte fechado.
Agentes Autônomos#
Um agente de IA combina um foundation model com três elementos:
Ferramentas — o modelo chama APIs, executa código, busca na web;
Memória — persistência entre turnos;
Planejamento — decomposição de objetivos em passos.
O elo técnico que conecta um LLM às suas ferramentas é o function calling (tool use, na nomenclatura da Anthropic). No fluxo padrão, a aplicação expõe ao modelo um catálogo de ferramentas — funções com nome, descrição e esquema de argumentos em JSON Schema. Diante de uma tarefa, o modelo emite uma chamada estruturada com o nome da função e os argumentos; a aplicação executa a função e devolve o resultado ao modelo, que incorpora a resposta ao raciocínio e continua — possivelmente encadeando novas chamadas.
O protocolo foi popularizado pela OpenAI em 2023 e hoje é padrão em Anthropic, Google e no ecossistema aberto. Em 2024, a Anthropic propôs o Model Context Protocol (MCP) — padrão aberto para que qualquer cliente (Claude Desktop, VS Code, ChatGPT) se conecte a qualquer servidor de ferramentas, acelerando a interoperabilidade do ecossistema de agentes.
Projetos como AutoGen (Microsoft) e benchmarks como AgentBench vêm estruturando esse campo. A convergência entre foundation models + ferramentas é o que torna possíveis assistentes que escrevem código, fazem pesquisa e operam navegadores de forma autônoma.
Note
Uma distinção útil
Modelo generativo — produz conteúdo (imagem, texto, vídeo).
Foundation model — base pré-treinada que se adapta a muitas tarefas.
Agente — usa um foundation model para agir no mundo (chama ferramentas, executa passos).
Todo agente usa um foundation model; nem todo foundation model é generativo no sentido estrito (embora a maioria seja).
Estado da Arte em 2026#
Na virada de 2025 para 2026, três frentes avançaram em paralelo — vale estar ciente delas para situar o que o livro não consegue cobrir em profundidade.
Agentes que operam computadores e código. Modelos como Claude (Anthropic), Gemini (Google) e GPT (OpenAI) ganharam a habilidade de operar interfaces gráficas — clicar, rolar, preencher formulários e executar tarefas de várias etapas em navegadores e sistemas operacionais. Para programação, Claude Code (Anthropic) e Codex (OpenAI, agora rodando em GPT-5.5, lançado em 24/abr/2026) se tornaram padrão, ao lado de Cursor e Windsurf. O agente lê o repositório, propõe mudanças, roda testes e itera.
Modelos de raciocínio e novas gerações. No mundo fechado: Claude Opus 4.7 (Anthropic, 16/abr/2026) — janela de 1M de tokens e ganhos em codificação agêntica e raciocínio multidisciplinar — junto da Mythos Preview, modelo restrito a parceiros de segurança via Project Glasswing (abr/2026); GPT-5.5 (OpenAI, 23/abr/2026), nova fronteira da OpenAI sucedendo a série o (o3 e o4-mini) e modelos especializados como GPT-Rosalind; e Gemini 3.1 Pro (Google, fev/2026) — com janela de 1M de tokens, três níveis de “esforço de raciocínio” ajustável e 77,1% no benchmark ARC-AGI-2. No mundo aberto: Qwen 3.6-Plus (Alibaba, abr/2026) e o Qwen3.6-35B-A3B open-source MoE liberado em 16/abr/2026; DeepSeek V4 Preview (24/abr/2026 — V4-Pro MoE com 1,6T parâmetros / 49B ativos e V4-Flash com 284B / 13B ativos, ambos com 1M de contexto); MiniMax M2.7 (self-evolving, mar/2026); e Mistral Large 3 / Small 4. Os custos por token dos abertos despencaram ordens de grandeza desde 2022 — o M2.7 custa cerca de US$ 0,30 por milhão de tokens de entrada, contra aproximadamente US$ 5 do Opus fechado em tarefas comparáveis de engenharia de software.
Multimodalidade e vídeo de alta qualidade. Modelos nativos multimodais dominam. Para geração de vídeo: Veo 4 (Google, abr/2026 — 4K a 120 FPS, clipes de até 30 s, storyboarding nativo e consistência de personagens reforçada), Kling 3.0 (Kuaishou — 4K HDR com arquitetura unificada que gera vídeo, áudio e imagem em uma só passagem), Hailuo 2.3 (MiniMax — última geração da família, foco em expressões faciais realistas) e a linha Sora 2 (OpenAI — em desligamento em duas etapas: app encerrado em 26/abr/2026 e API em 24/set/2026). Em visão computacional, Qwen3-VL (variantes densas 2B/4B/8B/32B e MoE 30B-A3B/235B-A22B) e os multimodais de OpenAI e Google fazem raciocínio sobre imagens em nível comparável ao humano em vários benchmarks.
Tip
Onde encontrar e testar os modelos
Hugging Face — repositório de referência para modelos abertos. Qwen, DeepSeek, Mistral, MiniMax, Meta e muitos outros publicam pesos, fine-tunes e datasets por lá. Essencial para projetos de CV: você encontra backbones pré-treinados, datasets anotados e demos prontas (Spaces).
OpenRouter — ponto único para testar via API dezenas de modelos fechados e abertos pagando pelo consumo. Útil para comparar Claude, GPT, Gemini, Qwen, DeepSeek e outros no mesmo benchmark sem precisar de conta em cada provedor.
Fundamentos Matemáticos#
Antes de mergulharmos no universo das redes neurais artificiais, é fundamental construir uma base sólida em dois pilares da matemática: álgebra linear e cálculo. Essas áreas nos ajudam a entender como os modelos processam, transformam e aprendem a partir dos dados.
Vamos explorar os principais conceitos de álgebra linear com exemplos práticos em Python, utilizando a biblioteca NumPy — uma ferramenta poderosa e amplamente utilizada em ciência de dados e inteligência artificial.
Álgebra Linear#
A álgebra linear estuda estruturas como escalares, vetores, matrizes e tensores — elementos essenciais para o funcionamento interno das redes neurais. A seguir, veremos cada um desses conceitos acompanhados de suas expressões matemáticas e exemplos computacionais.
Para tornar a abstração palpável, pense em cada estrutura como uma forma específica de organizar dados que já conhecemos do universo de imagens:
%%{init: {"flowchart": {"htmlLabels": true, "curve": "basis"}, "themeVariables": {"fontSize": "14px"}} }%%
flowchart LR
E["<b>Escalar</b><br/>0D · ℝ<br/><i>intensidade de 1 pixel</i>"]
V["<b>Vetor</b><br/>1D · ℝ<sup>n</sup><br/><i>histograma, feature vector</i>"]
M["<b>Matriz</b><br/>2D · ℝ<sup>H×W</sup><br/><i>imagem em tons de cinza</i>"]
T3["<b>Tensor 3D</b><br/>ℝ<sup>H×W×C</sup><br/><i>imagem RGB (C=3)</i>"]
T4["<b>Tensor 4D</b><br/>ℝ<sup>B×C×H×W</sup><br/><i>batch de imagens</i>"]
E --> V --> M --> T3 --> T4
Escalares#
Um escalar é simplesmente um número real, denotado por:
Onde \(a\) representa qualquer número real, como 3.5. Esse valor pode, por exemplo, representar um parâmetro ajustável de uma rede neural.
import numpy as np
# Exemplo de escalar
escalar = 3.5
print(escalar)
Saída do Código
3.5
Vetores#
Um vetor é uma sequência ordenada de números reais. Ele é representado como:
Onde cada \(v_i \in \mathbb{R}\) é um componente do vetor \(\mathbf{v}\), que pode conter, por exemplo, atributos como altura, peso e idade.
# Exemplo de vetor
vetor = np.array([1.0, 2.0, 3.0])
print(vetor)
Saída do Código
[1. 2. 3.]
Matrizes#
Uma matriz é uma grade de números organizada em linhas e colunas, representada por:
Onde \(m_{ij}\) representa o elemento da linha \(i\) e coluna \(j\). Matrizes são muito úteis para representar conjuntos de dados ou os pesos entre camadas de uma rede.
# Exemplo de matriz
matriz = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(matriz)
Saída do Código
[[1 2 3]
[4 5 6]
[7 8 9]]
Tensores#
Um tensor é uma generalização de vetores e matrizes para mais de duas dimensões. Um tensor 3D, por exemplo, pode ser representado como:
Onde \(d_1\), \(d_2\), \(d_3\) representam as dimensões do tensor (como altura, largura e canais de cor no caso de uma imagem RGB).
# Exemplo de tensor 3D
tensor = np.random.rand(3, 3, 3)
print(tensor)
Saída (valores aleatórios):
[[[0.86 0.68 0.33]
[0.77 0.42 0.90]
[0.22 0.35 0.75]]
[[0.96 0.17 0.39]
[0.34 0.67 0.72]
[0.91 0.59 0.74]]
[[0.05 0.37 0.93]
[0.32 0.25 0.69]
[0.02 0.27 0.30]]]
Resumo Visual#
Conceito |
Representação Matemática |
Exemplo em Python |
Dimensão |
|---|---|---|---|
Escalar |
\(a \in \mathbb{R}\) |
|
0D |
Vetor |
\(\mathbf{v} \in \mathbb{R}^n\) |
|
1D |
Matriz |
\(\mathbf{M} \in \mathbb{R}^{m \times n}\) |
|
2D |
Tensor |
\(\mathcal{T} \in \mathbb{R}^{d_1 \times d_2 \times \cdots}\) |
|
3D+ |
Note
Convenções de dimensões em frameworks de deep learning A ordem dos eixos em um tensor 4D varia entre frameworks. Considere um lote de 2 imagens RGB 32×32:
PyTorch — channels-first: [B, C, H, W].
import torch
x = torch.zeros(2, 3, 32, 32) # 2 imagens RGB 32x32
print(x.shape) # torch.Size([2, 3, 32, 32])
TensorFlow / Keras — channels-last: [B, H, W, C].
import tensorflow as tf
x = tf.zeros((2, 32, 32, 3)) # mesmo lote
print(x.shape) # (2, 32, 32, 3)
Ambas as representações são equivalentes — muda apenas a ordem em que os eixos aparecem na memória. Para migrar de um framework para outro basta uma transposição: por exemplo, x.permute(0, 2, 3, 1) no PyTorch leva de channels-first para channels-last. Esquecer essa transposição é fonte clássica de bugs.
Operações entre Escalares, Vetores e Matrizes#
Antes de apresentar as operações isoladamente, vale ver onde elas se encaixam. Toda camada densa de uma rede neural é, na essência, a composição das operações desta seção:
%%{init: {"flowchart": {"htmlLabels": true, "curve": "basis"}, "themeVariables": {"fontSize": "15px"}} }%%
flowchart LR
X["<b>x</b><br/><i>vetor de entrada</i>"]
MULT["<b>W · x</b><br/><i>multiplicação<br/>matriz-vetor</i>"]
BIAS["<b>+ b</b><br/><i>bias</i>"]
ACT["<b>σ</b><br/><i>ativação</i>"]
Y["<b>y</b><br/><i>vetor de saída</i>"]
X --> MULT --> BIAS --> ACT --> Y
As próximas subseções apresentam os blocos dessa sequência.
Produto Interno (Produto Escalar)#
O produto interno é amplamente usado no cálculo da ativação de neurônios em redes neurais.
Aplicação prática:
Cálculo da saída de um neurônio na regressão linear.
Similaridade entre vetores de características (por exemplo, em embeddings de imagens ou textos).
Matematicamente, para dois vetores \( \mathbf{a} = [a_1, a_2, \ldots, a_n] \) e \( \mathbf{b} = [b_1, b_2, \ldots, b_n] \), ambos com \(n\) componentes reais:
Ou seja, somamos o produto dos elementos correspondentes de cada vetor.
# Produto Interno (equivalente a np.dot para vetores 1D)
vetor1 = np.array([1, 2, 3])
vetor2 = np.array([4, 5, 6])
produto_interno = vetor1 @ vetor2 # operador @ equivale a np.dot aqui
print(produto_interno)
# Produto elemento a elemento (Hadamard)
produto_elementwise = vetor1 * vetor2
print(produto_elementwise)
Saída do Código
32
[ 4 10 18]
Multiplicação Matriz-Vetor#
Usada para calcular a saída de uma camada densa (fully connected) em redes neurais.
Aplicação prática:
Propagação de sinais em redes feedforward.
Transformações lineares em imagens (ex: escala de brilho ou contraste).
Seja \(\mathbf{A} \in \mathbb{R}^{m \times n}\) uma matriz com \(m\) linhas e \(n\) colunas, e \(\mathbf{x} \in \mathbb{R}^n\) um vetor com \(n\) elementos. O produto resulta em um vetor \(\mathbf{y} \in \mathbb{R}^m\):
Onde cada elemento de \(\mathbf{y}\) é obtido por um produto interno entre as linhas de \(\mathbf{A}\) e o vetor \(\mathbf{x}\).
# Multiplicação Matriz-Vetor (np.dot e @ são equivalentes aqui)
matriz = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
vetor = np.array([1, 2, 3])
resultado = matriz @ vetor # mais legível que np.dot para produto linear
print(resultado)
# Produto elemento a elemento não é válido aqui: erro se tentar matriz * vetor
Saída do Código
[14 32 50]
Note
Por que matriz @ vetor e não vetor @ matriz?
A ordem dos operandos não é arbitrária. A convenção matemática \(\mathbf{y} = \mathbf{A}\mathbf{x}\) coloca a matriz à esquerda e o vetor-coluna à direita. Em NumPy, matriz @ vetor respeita essa ordem: uma matriz \(m \times n\) “consome” um vetor de dimensão \(n\) e devolve um vetor de dimensão \(m\) (a dimensão de saída).
Se você escrever vetor @ matriz, o NumPy trata o vetor como linha (\(1 \times n\)), e a operação só é válida quando o número de linhas da matriz é \(n\) — resultado equivalente a \(\mathbf{x}^\top \mathbf{A}\), com forma e semântica diferentes.
Em redes neurais isso é crucial: a matriz de pesos \(\mathbf{W}\) é armazenada como (neurônios_saída, neurônios_entrada). Então W @ x entrega diretamente o vetor de ativações com a dimensão certa da camada seguinte — trocar a ordem quebra o pipeline da rede.
Multiplicação Matriz-Matriz#
A multiplicação de duas matrizes resulta em uma nova matriz. Essa operação é essencial em modelos de machine learning para processar lotes de dados e compor camadas de redes neurais.
Aplicação prática:
Propagação de múltiplas amostras ao mesmo tempo (minibatches).
Implementação eficiente de camadas densas e convolucionais.
Seja \(\mathbf{A} \in \mathbb{R}^{m \times n}\) e \(\mathbf{B} \in \mathbb{R}^{n \times p}\). O produto \(\mathbf{C} = \mathbf{A} \mathbf{B}\) resulta em uma nova matriz \(\mathbf{C} \in \mathbb{R}^{m \times p}\), onde:
\(m\) = número de linhas de \(\mathbf{A}\)
\(n\) = número de colunas de \(\mathbf{A}\) = número de linhas de \(\mathbf{B}\)
\(p\) = número de colunas de \(\mathbf{B}\)
Warning
Compatibilidade de dimensões Para que a multiplicação \(\mathbf{A}\mathbf{B}\) seja válida, o número de colunas de \(\mathbf{A}\) deve ser igual ao número de linhas de \(\mathbf{B}\).
# Multiplicação Matriz-Matriz (np.dot e @ são equivalentes para 2D)
matriz1 = np.array([[1, 2], [3, 4], [5, 6]]) # 3x2
matriz2 = np.array([[7, 8], [9, 10]]) # 2x2
resultado = matriz1 @ matriz2 # mais claro que np.dot para 2D
print(resultado)
# Produto elemento a elemento (Hadamard) só pode ser feito entre matrizes com mesma forma
produto_elementwise = matriz1 * matriz1 # Exemplo: 3x2 * 3x2
print(produto_elementwise)
Saída do Código
[[ 25 28]
[ 57 64]
[ 89 100]]
[[ 1 4]
[ 9 16]
[25 36]]
Transposição de Matrizes#
A transposição inverte as dimensões de uma matriz, trocando linhas por colunas.
Aplicação prática:
Alinhamento de pesos e entradas.
Inversão de filtros em convoluções transpostas (usadas em redes geradoras, como GANs).
Seja \(\mathbf{A} \in \mathbb{R}^{m \times n}\), a transposta \(\mathbf{A}^\top\) é:
# Transposição de Matriz
matriz = np.array([[1, 2, 3], [4, 5, 6]])
matriz_transposta = matriz.T
print(matriz_transposta)
Saída do Código
[[1 4]
[2 5]
[3 6]]
Calculando Normas de Vetores: L1 e L2#
As normas de vetores medem o “tamanho” ou a “magnitude” de um vetor no espaço. Duas das normas mais utilizadas são a norma L1 e a norma L2 (euclidiana).
A Norma L1 é a soma dos valores absolutos dos componentes de um vetor:
Aplicação prática:
Regularização L1, que incentiva esparsidade nos coeficientes de modelos.
Métricas de distância em espaços de alta dimensão, como a “manhattan distance”.
# Norma L1
vetor = np.array([1, 2, 3])
norma_l1 = np.linalg.norm(vetor, ord=1)
print(norma_l1)
Saída do Código
6.0
A norma L2 mede a distância do vetor até a origem, levando em conta o “comprimento reto” no espaço vetorial:
Aplicação prática:
Regularização L2 (weight decay) para evitar overfitting.
Cálculo de distância entre embeddings em tarefas como reconhecimento facial.
# Norma L2 (Euclidiana)
norma_l2 = np.linalg.norm(vetor) # padrão é a norma L2
print(norma_l2)
Saída do Código
3.7416573867739413
Observação: np.linalg.norm calcula, por padrão, a norma L2. Para outras normas, como L1, é necessário especificar o parâmetro ord.
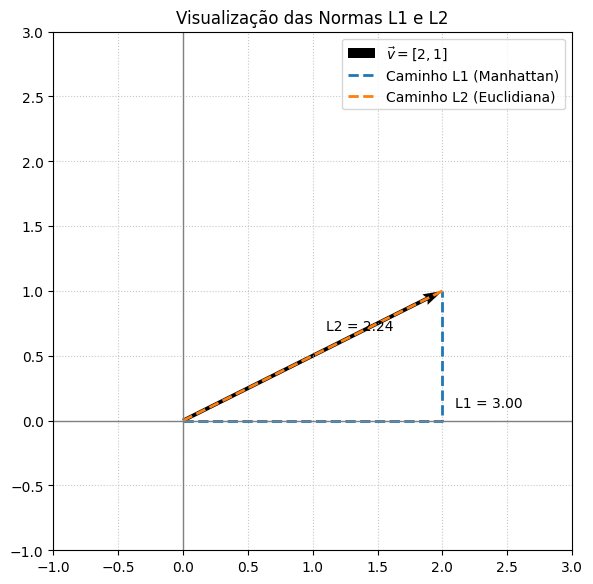
Visualizando as Normas
A seguir, temos uma representação gráfica das normas L1 e L2 para o vetor \(\vec{v} = [2, 1]\):
Linha sólida: representa o vetor original.
Linha tracejada para L1: caminho em forma de “escada”, que soma os deslocamentos absolutos nas direções x e y.
Linha tracejada para L2: caminho retilíneo direto da origem até o ponto, correspondente à distância euclidiana.
import numpy as np
import matplotlib.pyplot as plt
# Vetor de exemplo
v = np.array([2, 1])
# Cálculo das normas
norma_l1 = np.linalg.norm(v, ord=1) # 3.0
norma_l2 = np.linalg.norm(v) # 2.23606797749979
# Plotagem
fig, ax = plt.subplots(figsize=(6, 6))
# Vetor
ax.quiver(0, 0, v[0], v[1], angles='xy', scale_units='xy', scale=1,
linewidth=2, label=r'$\vec{v} = [2, 1]$')
# Caminhos
ax.plot([0, v[0], v[0]], [0, 0, v[1]], '--', linewidth=2, label='Caminho L1 (Manhattan)')
ax.plot([0, v[0]], [0, v[1]], '--', linewidth=2, label='Caminho L2 (Euclidiana)')
# Anotações
ax.text(2.1, 0.1, f'L1 = {norma_l1:.2f}', fontsize=10)
ax.text(1.1, 0.7, f'L2 = {norma_l2:.2f}', fontsize=10)
# Ajustes do gráfico
ax.set_xlim(-1, 3)
ax.set_ylim(-1, 3)
ax.set_aspect('equal')
ax.grid(True, linestyle=':', alpha=0.7)
ax.axhline(0, color='gray', lw=1)
ax.axvline(0, color='gray', lw=1)
ax.legend()
ax.set_title('Visualização das Normas L1 e L2', fontsize=12)
plt.tight_layout()
plt.show()
Cálculo em Machine Learning#
O cálculo é uma das ferramentas matemáticas fundamentais para o funcionamento de algoritmos de machine learning. Ele está diretamente relacionado com o processo de otimização, no qual ajustamos os parâmetros de um modelo para minimizar uma função de custo e, assim, melhorar o desempenho do modelo.
Na prática, o cálculo entra em ML através do laço de otimização — a cada iteração, o modelo avalia uma entrada, compara com o valor esperado, mede o erro, calcula o gradiente e corrige os pesos. As próximas subseções explicam cada peça.
%%{init: {"flowchart": {"htmlLabels": true, "curve": "basis"}, "themeVariables": {"fontSize": "15px"}} }%%
flowchart LR
P["<b>pesos θ</b>"]
M["<b>modelo</b><br/>f(x, θ)"]
L["<b>custo</b><br/>J(θ)"]
G["<b>gradiente</b><br/>∇J(θ)"]
U["<b>atualiza</b><br/>θ ← θ − η∇J(θ)"]
P --> M --> L --> G --> U --> P
Derivadas Parciais (Gradientes)#
As derivadas parciais indicam como pequenas variações em um parâmetro específico afetam o valor de uma função. No contexto de ML, usamos derivadas parciais para calcular como cada parâmetro influencia o erro do modelo — isso é o que chamamos de gradiente.
Aplicação Prática: Durante o treinamento de um modelo (como uma rede neural), utilizamos o gradiente da função de custo em relação aos pesos para saber como atualizá-los. Isso é feito com algoritmos como gradiente descendente.
Definição Matemática:
Se temos uma função \(f(x_1, x_2, \ldots, x_n)\), a derivada parcial em relação a \(x_i\) é:
Exemplo Analítico: Considere \(f(x, y) = x^2 + 3y\). Então:
\(\frac{\partial f}{\partial x} = 2x \Rightarrow \frac{\partial f}{\partial x}(2, 1) = 4\)
\(\frac{\partial f}{\partial y} = 3 \Rightarrow \frac{\partial f}{\partial y}(2, 1) = 3\)
Exemplo em Python:
def f(x, y):
return x**2 + 3*y
def derivada_parcial_x(f, x, y, delta=1e-5):
return (f(x + delta, y) - f(x, y)) / delta
def derivada_parcial_y(f, x, y, delta=1e-5):
return (f(x, y + delta) - f(x, y)) / delta
print("∂f/∂x:", derivada_parcial_x(f, 2, 1))
print("∂f/∂y:", derivada_parcial_y(f, 2, 1))
Saída:
∂f/∂x: 4.000009999951316
∂f/∂y: 3.000000248221113
Gradiente#
O gradiente de uma função multivariada é um vetor composto pelas derivadas parciais em relação a todos os seus parâmetros. Ele indica a direção de maior crescimento da função — ou seja, é usado para decidir para onde mover os pesos na minimização da função de custo.
Definição Matemática:
Se \(J(\theta)\) é a função de custo e \(\theta = [\theta_1, \theta_2, \ldots, \theta_n]\) os parâmetros do modelo:
Exemplo Analítico: Considere \(J(\theta_1, \theta_2) = \theta_1^2 + \theta_2^2\). Então:
\(\frac{\partial J}{\partial \theta_1} = 2\theta_1 \Rightarrow 2\)
\(\frac{\partial J}{\partial \theta_2} = 2\theta_2 \Rightarrow 4\)
Gradiente: \(\nabla J(\theta) = [2, 4]\) para \(\theta = [1, 2]\)
Exemplo em Python:
import numpy as np
def J(theta):
return theta[0]**2 + theta[1]**2
def gradiente(J, theta, delta=1e-5):
grad = np.zeros_like(theta)
for i in range(len(theta)):
theta_up = np.copy(theta)
theta_up[i] += delta
grad[i] = (J(theta_up) - J(theta)) / delta
return grad
theta = np.array([1.0, 2.0])
print("Gradiente:", gradiente(J, theta))
Saída:
Gradiente: [2.00000001 4.00000033]
Regra da Cadeia#
A regra da cadeia é uma técnica fundamental do cálculo usada para derivar funções compostas — isto é, quando uma função está “dentro” de outra. Em machine learning, essa regra é essencial durante o backpropagation (retropropagação do erro), pois as redes neurais profundas consistem em múltiplas camadas de funções encadeadas.
Tip
Intuição didática Para derivar uma função composta, primeiro derivamos a função de fora (a mais externa), mantendo a de dentro intacta, e depois multiplicamos pela derivada da função de dentro.
É como “descascar uma cebola”: você começa de fora para dentro.
Definição Matemática
Se temos duas funções:
\(u = g(x)\)
\(y = f(u)\)
Então a derivada de \(y\) com relação a \(x\) é:
Exemplo Analítico
Seja:
\(g(x) = 3x + 1\)
\(f(u) = u^2 \Rightarrow f(g(x)) = (3x + 1)^2\)
A derivada de \(f(g(x))\) usando a regra da cadeia será:
Calculando cada parte:
\(f'(u) = 2u \Rightarrow f'(g(x)) = 2(3x + 1)\)
\(g'(x) = 3\)
Logo:
Substituindo \(x = 2\):
Exemplo em Python
def f(u):
return u**2 # f(u) = u²
def g(x):
return 3*x + 1 # g(x) = 3x + 1
def composicao(x):
return f(g(x)) # f(g(x)) = (3x + 1)²
def derivada(x):
df_du = 2 * g(x) # f'(g(x)) = 2 * (3x + 1)
du_dx = 3 # g'(x) = 3
return df_du * du_dx # Regra da cadeia
# Teste no ponto x = 2
x = 2
print("Valor da função composta:", composicao(x)) # Deve ser 49
print("Derivada via regra da cadeia:", derivada(x)) # Deve ser 42
Saída esperada:
Valor da função composta: 49
Derivada via regra da cadeia: 42
Redes Neurais Artificiais (ANNs)#
As Redes Neurais Artificiais (ANNs) são modelos computacionais inspirados no funcionamento do cérebro humano. Elas conseguem aprender padrões complexos a partir de dados, sendo amplamente utilizadas em tarefas como reconhecimento de imagens, processamento de linguagem natural e previsão de séries temporais.
Neste material, exploraremos os principais conceitos de forma passo a passo: começando pelo neurônio artificial, passando pelo processo de aprendizado (ajuste de pesos, propagação e retropropagação), e finalizando com a otimização da rede.
O Neurônio Artificial: A Unidade Básica#
Definição. O neurônio artificial é o bloco fundamental de uma rede neural. A ideia foi inspirada no neurônio biológico — as entradas correspondem aos dendritos, os pesos representam a força sináptica, a soma ponderada equivale ao potencial de membrana e a função de ativação ao disparo do axônio. Vale ressaltar que essa analogia é histórica e simplificada: um neurônio artificial é matematicamente muito mais simples que um neurônio biológico real.
O processamento da informação ocorre em quatro passos:
Recebe entradas (\(x_1, x_2, \ldots, x_n\)).
Multiplica cada entrada por um peso (\(w_1, w_2, \ldots, w_n\)), que indica sua importância relativa.
Soma todas as entradas ponderadas e adiciona um bias (\(b\)), termo que desloca a função de ativação e permite ao neurônio responder mesmo quando todas as entradas são zero.
Passa o resultado por uma função de ativação (\(f(\cdot)\)), que introduz não-linearidade na resposta do neurônio.
Diagrama do neurônio. A figura abaixo destaca dois blocos: a Função de Transferência (\(\Sigma\)), que calcula a soma ponderada das entradas com os pesos somada ao bias, e a Função de Ativação, que aplica \(f(\cdot)\) a esse valor.
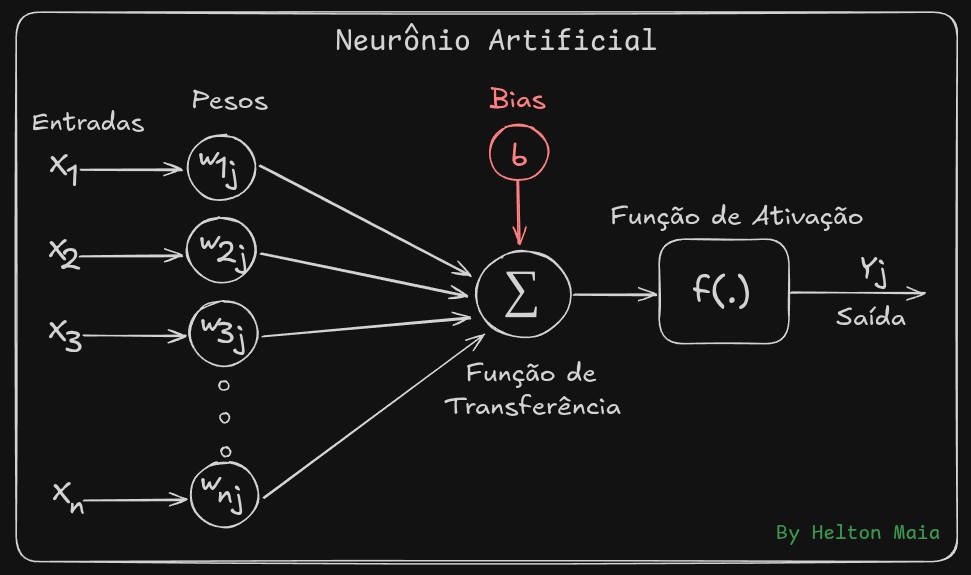
Formulação matemática. A operação realizada por um neurônio pode ser escrita como
onde:
\(x_i\): valores de entrada;
\(w_i\): pesos (parâmetros ajustáveis durante o treinamento);
\(b\): bias (parâmetro que desloca a função de ativação);
\(f(\cdot)\): função de ativação (introduz não-linearidade);
\(y\): saída do neurônio.
Quando precisamos identificar um neurônio específico dentro de uma camada, é comum acrescentar um segundo índice e separar o cálculo em duas etapas — pré-ativação e ativação:
Na notação \(w_{ji}\), o primeiro índice indica o neurônio de destino (o que recebe a conexão) e o segundo, a entrada de origem — convenção que casa com a forma matricial \(\mathbf{z} = \mathbf{W}\mathbf{a} + \mathbf{b}\) usada mais adiante. A soma \(Z_j\) é chamada de pré-ativação na literatura recente. Enquanto estivermos analisando um único neurônio, omitimos o índice \(j\) por simplicidade — ele será útil quando trabalharmos com múltiplos neurônios mais adiante.
Implementação em Python. O trecho a seguir aplica a fórmula diretamente com NumPy, usando a ReLU como função de ativação:
import numpy as np
# Entradas, pesos e bias do neurônio
x = np.array([0.5, 1.2, -0.7]) # entradas (x_1, x_2, x_3)
w = np.array([0.4, -0.3, 0.8]) # pesos (w_1, w_2, w_3)
b = 0.1 # bias
def f(z): # ReLU
return max(0.0, z)
# Aplicação direta da fórmula y = f( Σ wᵢ xᵢ + b )
z = np.dot(w, x) + b # pré-ativação Z
y = f(z) # ativação final
print(f"z = {z:.3f}")
print(f"y = {y:.3f}")
Saída esperada:
z = -0.620
y = 0.000
Como \(z < 0\), a ReLU zera a saída — uma forma simples de o neurônio “não disparar” quando a soma ponderada é negativa.
Pesos e Bias: Como a Rede Aprende?#
Os pesos (\(w_i\)) e o bias (\(b\)) são os parâmetros ajustáveis da rede — é neles que o conhecimento aprendido fica armazenado. Cada peso controla a intensidade e o sinal com que a entrada correspondente influencia a soma ponderada:
\(w_i > 0\) → a entrada aumenta a soma; quanto maior \(w_i\), maior o impacto.
\(w_i \approx 0\) → a entrada é praticamente ignorada.
\(w_i < 0\) → a entrada reduz a soma (relação inversa).
O bias desloca a função de ativação, permitindo ao neurônio responder mesmo com todas as entradas zeradas — sem ele, a fronteira de decisão passaria sempre pela origem.
Como os parâmetros são ajustados? O treinamento começa com inicialização aleatória dos pesos em valores pequenos (esquemas como Xavier/Glorot ou He evitam saturação ou explosão dos sinais). A cada iteração, uma função de perda mede o erro entre a saída gerada e a esperada, e o gradiente descendente atualiza pesos e bias na direção que reduz esse erro — usando os gradientes calculados pela retropropagação, detalhada mais adiante.
Funções de Ativação: Introduzindo Não-Linearidade#
Sem funções de ativação, uma rede neural seria apenas uma combinação linear de entradas, incapaz de aprender padrões complexos. As funções de ativação introduzem não-linearidade, permitindo que a rede modele relações mais sofisticadas.
Para tornar isso concreto, vamos antes ver o que acontece sem ativação. Considere a rede totalmente conectada com duas camadas lineares ilustrada abaixo:

A entrada é o vetor \(\mathbf{x} \in \mathbb{R}^2\); a primeira camada (oculta) tem matriz de pesos \(\mathbf{W}^{(1)} \in \mathbb{R}^{2 \times 2}\) e bias \(\mathbf{b}^{(1)} \in \mathbb{R}^2\); e a segunda camada (saída) tem \(\mathbf{W}^{(2)} \in \mathbb{R}^{1 \times 2}\) e \(b^{(2)} \in \mathbb{R}\). Adotando os valores
a propagação direta sem ativação se reduz a duas multiplicações de matriz seguidas de soma do bias. Na camada oculta temos
e a camada de saída produz
Note
Por que precisamos de não-linearidade Sem função de ativação, qualquer composição de camadas lineares se reduz a uma única transformação linear. Empilhar duas ou mais camadas não adiciona capacidade representacional — é a não-linearidade da função de ativação que permite à rede modelar padrões complexos.
Código Python:
import numpy as np
# Entrada
x = np.array([[1.0], [2.0]]) # vetor coluna
# Parâmetros da primeira camada
W1 = np.array([[0.2, -0.1],
[0.0, 0.3]])
b1 = np.array([[0.1], [-0.2]])
# Parâmetros da segunda camada
W2 = np.array([[0.3, 0.5]])
b2 = np.array([[0.5]])
# Forward pass sem ativação
h = W1 @ x + b1 # Saída da camada oculta
y = W2 @ h + b2 # Saída final
print(f"Saída da camada oculta h:\n{h}")
print(f"Saída final y: {y.item():.2f}")
Saída esperada:
Saída da camada oculta h:
[[0.1]
[0.4]]
Saída final y: 0.73
Para introduzir a não-linearidade que falta a essa rede, basta aplicar uma função de ativação ao final de cada camada — em geral nas ocultas, e às vezes também na saída, dependendo da tarefa. A tabela a seguir resume as principais opções:
Principais Funções de Ativação#
Função |
Fórmula |
Python |
Comportamento e aplicação |
|---|---|---|---|
Sigmoid |
\(\sigma(x) = \frac{1}{1 + e^{-x}}\) |
|
Mapeia para \((0, 1)\); pode sofrer com vanishing gradient. Comum em saída de classificadores binários. |
ReLU |
\(\text{ReLU}(x) = \max(0, x)\) |
|
Retorna \(x\) se positivo, senão \(0\); simples e eficiente, mas pode zerar neurônios. Padrão em camadas ocultas de redes profundas. |
Tanh |
\(\tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}\) |
|
Mapeia para \((-1, 1)\); saída centrada, mas sofre com vanishing gradient. Usada em camadas ocultas com dados normalizados. |
Leaky ReLU |
\(\text{LeakyReLU}(x) = \max(\alpha x, x),\ \alpha \approx 0{,}01\) |
|
Variante do ReLU com pequeno gradiente quando \(x < 0\) — evita o “neurônio morto”. |
Softmax |
\(\text{Softmax}(x_i) = \frac{e^{x_i}}{\sum_j e^{x_j}}\) |
|
Transforma vetor em distribuição de probabilidade (soma 1). Saída de classificadores multiclasse. |
Visualização das Funções de Ativação e suas Derivadas
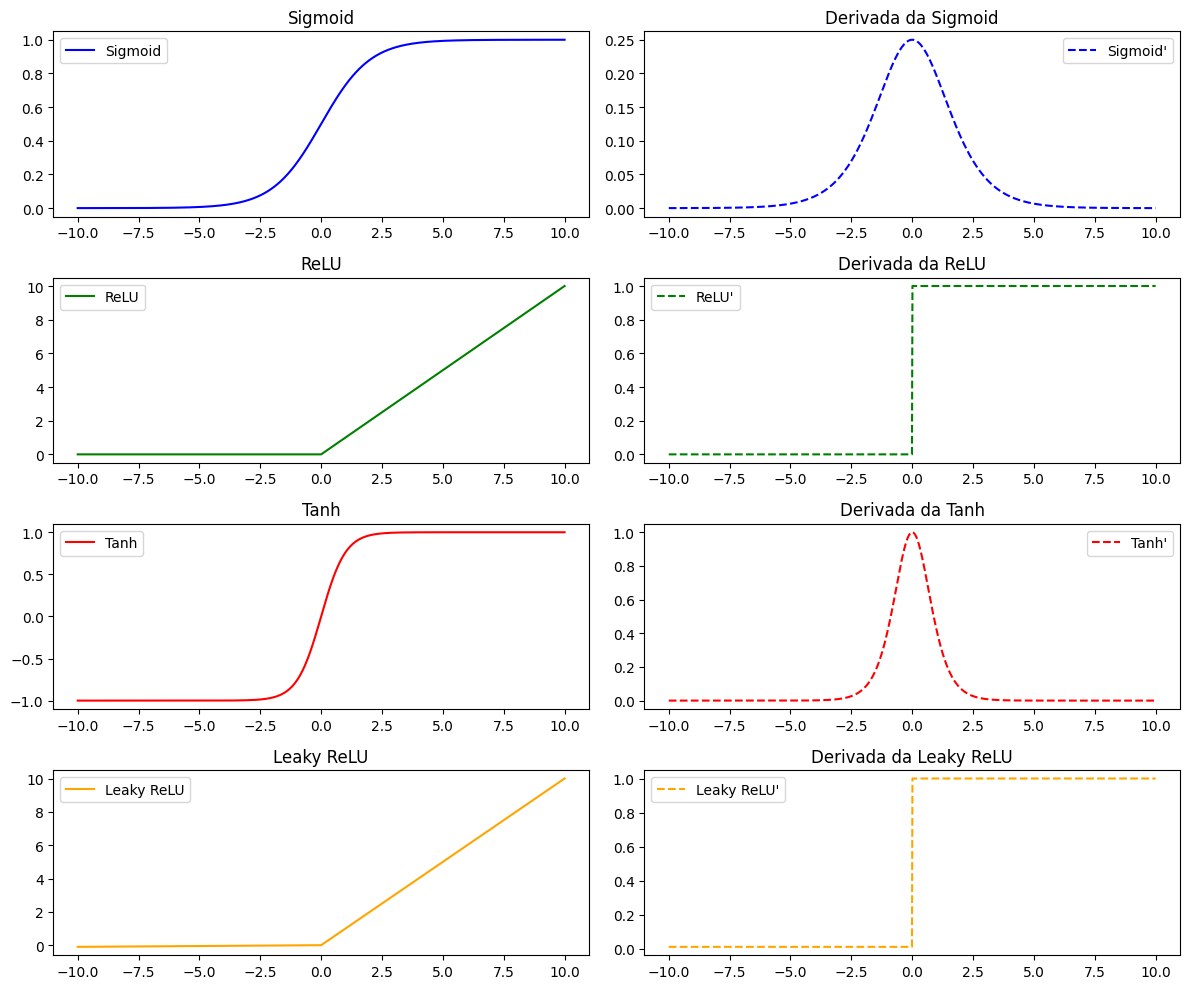
Na figura, a Leaky ReLU foi plotada com \(\alpha = 0{,}1\) apenas para tornar a inclinação visível para \(x < 0\); em prática usa-se \(\alpha \approx 0{,}01\) (valor da tabela). A Softmax aparece em dois painéis em vez de “função + derivada”: o primeiro converte um vetor de logits em probabilidades (note que \(\sum p_i = 1\)), e o segundo mostra como duas componentes redistribuem probabilidade quando uma delas varia.
Implementação em Python. Aplicando as cinco funções a um vetor pequeno com valores negativos, zero e positivos, dá para comparar lado a lado o efeito de cada uma:
import numpy as np
# Vetor de entrada (logits ou pré-ativação)
z = np.array([-2.0, -0.5, 0.0, 0.5, 2.0])
# Funções de ativação (mesmas fórmulas da tabela)
def sigmoid(z): return 1 / (1 + np.exp(-z))
def relu(z): return np.maximum(0, z)
def tanh(z): return np.tanh(z)
def leaky_relu(z, alpha=0.01):
return np.maximum(alpha * z, z)
def softmax(z):
return np.exp(z) / np.sum(np.exp(z))
# Aplicação em z
print(f"z = {z}")
print(f"sigmoid = {np.round(sigmoid(z), 4)}")
print(f"ReLU = {relu(z)}")
print(f"tanh = {np.round(tanh(z), 4)}")
print(f"LeakyReLU = {leaky_relu(z)}")
sm = softmax(z)
print(f"softmax = {np.round(sm, 4)} (soma = {sm.sum():.4f})")
Saída esperada:
z = [-2. -0.5 0. 0.5 2. ]
sigmoid = [0.1192 0.3775 0.5 0.6225 0.8808]
ReLU = [0. 0. 0. 0.5 2. ]
tanh = [-0.964 -0.4621 0. 0.4621 0.964 ]
LeakyReLU = [-0.02 -0.005 0. 0.5 2. ]
softmax = [0.0126 0.0563 0.0928 0.1529 0.6855] (soma = 1.0000)
Note
E no estado da arte? As arquiteturas modernas raramente usam sigmoid em camadas ocultas — sofre com vanishing gradient. Em CNNs, a ReLU (e variantes como Leaky ReLU) seguem dominantes. Em Transformers (ViT, GPT, Llama), a escolha padrão é a GELU (\(x \cdot \Phi(x)\)) ou a SiLU / Swish (\(x \cdot \sigma(x)\)) — aproximações suaves da ReLU que treinam melhor em redes muito profundas.
Propagação (Forward Propagation)#
A propagação direta (do inglês forward propagation) é o processo em que os dados de entrada percorrem a rede, camada por camada, até produzir uma saída. Em cada neurônio dessa trajetória, repete-se a operação que vimos para o neurônio isolado — soma ponderada das entradas com os pesos, adição do bias e aplicação da função de ativação — usando como entrada as ativações produzidas pela camada anterior.

A figura acima ilustra o fluxo: o vetor de entrada \(\mathbf{x}\) atravessa as camadas da rede até produzir o vetor de saída \(\mathbf{y}\). Os rótulos de peso seguem a convenção \(w^{(\ell)}_{ji}\) — primeiro índice \(j\) é o neurônio de destino, segundo \(i\) é a origem — e as caixas abaixo de cada camada destacam a operação correspondente: a pré-ativação matricial seguida da ativação. Em notação compacta, para cada camada \(\ell\) a propagação direta é
em que \(\mathbf{a}^{(\ell-1)}\) é a saída da camada anterior — ou as próprias entradas \(\mathbf{x}\) no caso da primeira camada oculta. O processo se repete até a última camada, cuja saída — a predição da rede — é comparada com a resposta esperada para o cálculo do erro.
Esse fluxo de dados, sempre da entrada para a saída, é o que dá nome à propagação direta: a informação só caminha “para frente” durante a inferência. O caminho inverso, em que o erro propaga “para trás” para ajustar pesos e bias, é a retropropagação, detalhada mais adiante.
Implementação em Python. Para concretizar o caso geral mostrado na figura, vamos reduzi-lo a um exemplo mínimo: uma rede com 3 entradas, uma camada oculta de 4 neurônios (com ReLU) e saída linear (1 neurônio sem ativação) — configuração comum em problemas de regressão. As shapes de \(\mathbf{W}^{(\ell)}\) seguem a convenção (neurônios da camada \(\ell\), entradas da camada \(\ell-1\)), coerente com \(\mathbf{z}^{(\ell)} = \mathbf{W}^{(\ell)} \mathbf{a}^{(\ell-1)} + \mathbf{b}^{(\ell)}\):
import numpy as np
# Entrada (1 exemplo, 3 features)
x = np.array([0.5, 1.2, -0.7])
# Camada 1 (oculta): 3 entradas → 4 neurônios. W^(1) tem shape (4, 3).
W1 = np.array([
[ 0.4, -0.3, 0.8],
[-0.2, 0.5, 0.1],
[ 0.1, 0.2, -0.4],
[ 0.3, -0.1, 0.6],
])
b1 = np.array([0.1, -0.2, 0.0, 0.05])
# Camada 2 (saída): 4 entradas → 1 neurônio. W^(2) tem shape (1, 4).
W2 = np.array([[0.5, -0.4, 0.3, 0.2]])
b2 = np.array([0.1])
def relu(z):
return np.maximum(0, z)
# Forward propagation
# Camada 1: z^(1) = W^(1) a^(0) + b^(1) ; a^(1) = ReLU(z^(1))
z1 = W1 @ x + b1
a1 = relu(z1)
# Camada 2: z^(2) = W^(2) a^(1) + b^(2) ; a^(2) = z^(2) (sem ativação na saída)
z2 = W2 @ a1 + b2
a2 = z2
print(f"z^(1) = {z1}")
print(f"a^(1) = {a1}")
print(f"y = {a2}")
Saída esperada:
z^(1) = [-0.62 0.23 0.57 -0.34]
a^(1) = [0. 0.23 0.57 0. ]
y = [0.179]
Cálculo do Erro: Medindo o Desempenho#
Para que a rede aprenda, é preciso primeiro medir o quanto ela erra. Esse papel cabe à função de perda (em inglês loss function, também chamada de função de custo): ela recebe a predição da rede \(\hat{y}\) e a resposta esperada \(y\) e devolve um número que quantifica a discrepância entre as duas. O objetivo do treinamento é encontrar pesos e bias que tornem esse número o menor possível.
A escolha da função de perda depende do tipo de problema. Em regressão, quando se prediz valores contínuos, a opção mais comum é o Erro Quadrático Médio (MSE), que penaliza quadraticamente o desvio entre predição e valor real:
Em classificação, quando a rede produz uma distribuição de probabilidade sobre as classes, a escolha padrão é a entropia cruzada (cross-entropy):
em que \(y_k\) é a probabilidade verdadeira da classe \(k\) — tipicamente uma codificação one-hot do rótulo correto — e \(\hat{y}_k\) é a probabilidade predita pela rede. Em um conjunto com \(N\) exemplos, a perda total é a média das perdas individuais.
É esse valor de \(L\) que serve de sinal orientador para o ajuste dos pesos e do bias por meio do gradiente descendente e da retropropagação, detalhados mais adiante.
Implementação em Python. O trecho a seguir calcula as duas perdas em exemplos pequenos — quatro predições contra os valores reais (MSE) e uma distribuição predita contra um rótulo one-hot (cross-entropy):
import numpy as np
# --- MSE (problema de regressão) ---
# y são os valores verdadeiros, ŷ são as predições da rede
y_true = np.array([3.0, -0.5, 2.0, 7.0])
y_pred = np.array([2.5, 0.0, 2.0, 8.0])
# L_MSE = (1/N) Σ (ŷ_i - y_i)^2
N = len(y_true)
mse = (1/N) * np.sum((y_pred - y_true) ** 2)
print(f"MSE = {mse:.4f}")
# --- Cross-entropy (classificação multiclasse, K = 3) ---
# y é o rótulo correto em formato one-hot; ŷ é a distribuição predita
y_true_onehot = np.array([0.0, 1.0, 0.0]) # classe correta = 1
y_pred_proba = np.array([0.2, 0.7, 0.1]) # distribuição predita
# L_CE = -Σ_k y_k log(ŷ_k)
ce = -np.sum(y_true_onehot * np.log(y_pred_proba))
print(f"CE = {ce:.4f}")
Saída esperada:
MSE = 0.3750
CE = 0.3567
Incorporando a Função de Ativação#
A figura abaixo mostra visualmente funções de ativação sendo incorporadas em nossa pequena rede artificial:

Aplicando, por exemplo, a função de ativação sigmoide — definida por
— tanto à saída da camada oculta quanto à saída final, a rede passa a capturar relações não-lineares entre as variáveis de entrada e a saída. Mantendo os mesmos pesos, bias e entrada do exemplo anterior, a camada oculta agora produz
e a camada de saída, com a sigmoide aplicada a \(z = \mathbf{W}^{(2)} \mathbf{h} + b^{(2)}\), fornece
A saída agora não é mais uma combinação linear direta da entrada — e é exatamente esse desvio da linearidade que dá às redes neurais a capacidade de aprender padrões complexos.
Código Python (com sigmoide nas duas camadas):
import numpy as np
# Função sigmoide
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# Entrada
x = np.array([[1.0], [2.0]])
# Parâmetros da primeira camada
W1 = np.array([[0.2, -0.1],
[0.0, 0.3]])
b1 = np.array([[0.1], [-0.2]])
# Parâmetros da segunda camada
W2 = np.array([[0.3, 0.5]])
b2 = np.array([[0.5]])
# Forward pass com ativação sigmoide em ambas as camadas
h_linear = W1 @ x + b1
h = sigmoid(h_linear)
z = W2 @ h + b2
y = sigmoid(z)
print(f"Saída linear da camada oculta (antes da ativação):\n{h_linear}")
print(f"Saída da camada oculta (após sigmoide):\n{h}")
print(f"Valor z (entrada da saída): {z.item():.4f}")
print(f"Saída final y (após sigmoide): {y.item():.6f}")
Saída esperada:
Saída linear da camada oculta (antes da ativação):
[[0.1]
[0.4]]
Saída da camada oculta (após sigmoide):
[[0.52497919]
[0.59868766]]
Valor z (entrada da saída): 0.9568
Saída final y (após sigmoide): 0.722488
Calculando o Erro#
Continuando o exemplo, suponha que a saída esperada seja \(y = 0{,}5\) enquanto a rede prediz \(\hat{y} \approx 0{,}7225\). Aplicando o MSE definido na subseção anterior, com \(N = 1\):
Esse valor sinaliza um descompasso entre a predição da rede e o alvo, e é justamente esse sinal que o gradiente descendente (visto adiante) vai usar para ajustar pesos e bias na próxima iteração.
Código Python:
# Valor real esperado
y_real = 0.5
# Saída predita pela rede
y_predito = y.item()
# Cálculo do erro quadrático médio
mse = (y_predito - y_real) ** 2
print(f"Erro Quadrático Médio (MSE): {mse:.6f}")
Saída esperada:
Erro Quadrático Médio (MSE): 0.049501
Note
MSE ou Entropia Cruzada? Aqui usamos MSE porque o exemplo trata de uma saída contínua (tipo regressão). Nas tarefas típicas de visão computacional — classificação de imagens, detecção, segmentação — a loss padrão é a Entropia Cruzada (Cross-Entropy), que penaliza mais fortemente predições confiantes mas erradas. A fórmula aparece na seção anterior (Cálculo do Erro: Medindo o Desempenho).
Exercício: Implementando um Neurônio Artificial#
Implemente, em Python + NumPy, a propagação direta de um único neurônio artificial com duas entradas — a unidade básica revisada na seção O Neurônio Artificial: A Unidade Básica.
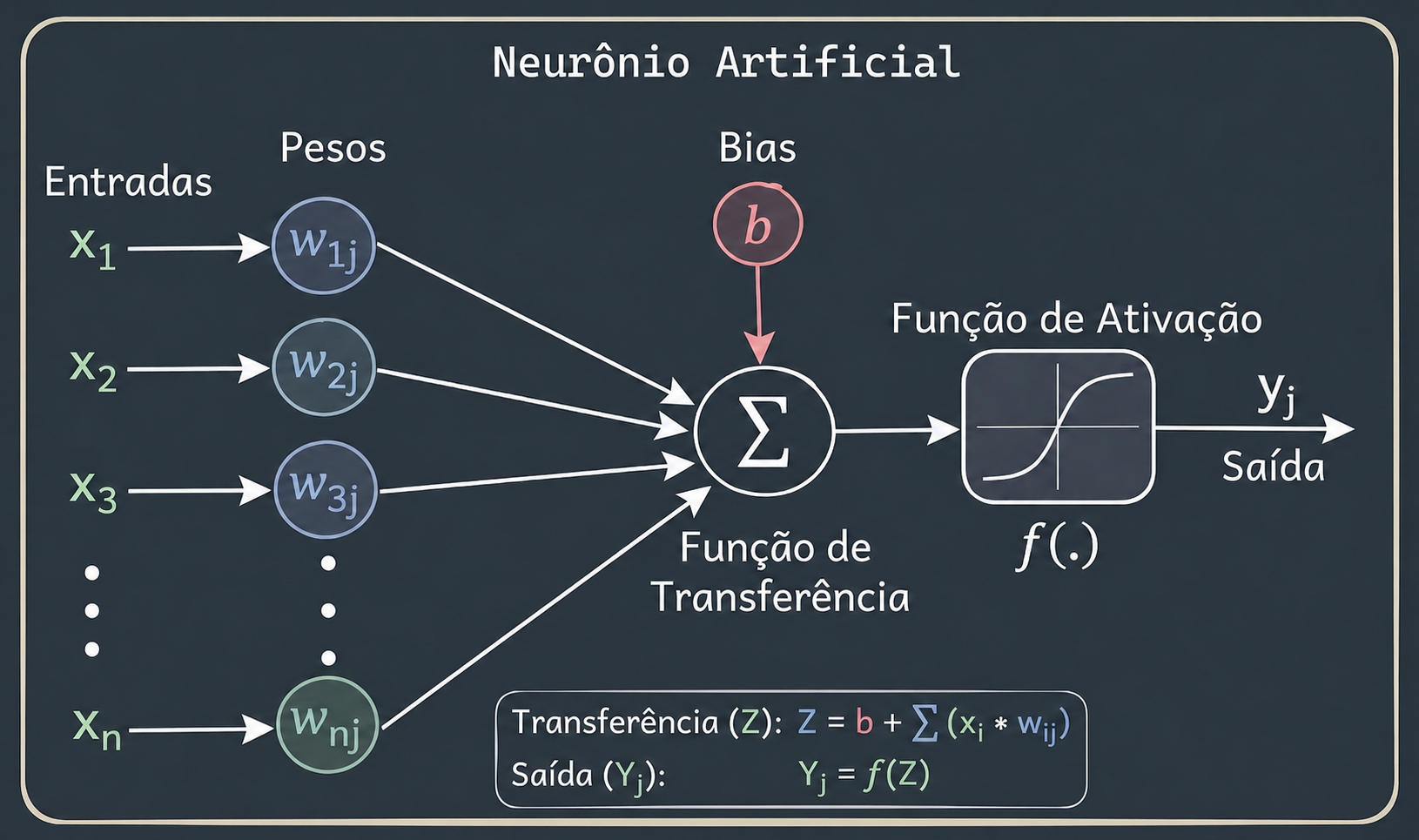
A propagação direta tem dois passos — a soma ponderada das entradas com os pesos somada ao bias, e a aplicação da função de ativação:
em que \(f\) é uma função de ativação à escolha.
Esqueleto a completar. Use o esqueleto abaixo como ponto de partida — implemente os corpos das funções marcadas com # TODO:
import numpy as np
# ----- Funções de ativação -----
# Cada função recebe z (escalar ou ndarray) e devolve y = f(z).
def sigmoid(z):
# TODO: sigmoid(z) = 1 / (1 + exp(-z))
pass
def relu(z):
# TODO: ReLU(z) = max(0, z) — use np.maximum
pass
def tanh(z):
# TODO: usar np.tanh(z)
pass
def leaky_relu(z, alpha=0.01):
# TODO: LeakyReLU(z) = max(alpha * z, z)
pass
# ----- Forward pass de um neurônio -----
def forward(x, w, b, f):
# Recebe entrada x (ndarray), pesos w (ndarray), bias b (escalar)
# e função de ativação f. Devolve (z, y) com z = w·x + b e y = f(z).
# TODO
pass
# ----- Função de perda -----
def mse(y, y_true):
# TODO: (y - y_true) ** 2
pass
# ----- Bloco de teste -----
x = np.array([1.0, 2.0])
w = np.array([0.5, -0.3])
b = 0.2
y_true = 0.5
activations = {
"sigmoid": sigmoid,
"relu": relu,
"tanh": tanh,
"leaky_relu": leaky_relu,
}
for name, f in activations.items():
z, y = forward(x, w, b, f)
e = mse(y, y_true)
print(f"Ativação: {name:<11} | z = {z:.3f} | y = {y:.4f} | erro = {e:.6f}")
Saída esperada (com \(\mathbf{x} = [1{,}\, 2]\), \(\mathbf{w} = [0{,}5{,}\, -0{,}3]\), \(b = 0{,}2\), \(y_{\text{true}} = 0{,}5\)):
Ativação: sigmoid | z = 0.100 | y = 0.5250 | erro = 0.000625
Ativação: relu | z = 0.100 | y = 0.1000 | erro = 0.160000
Ativação: tanh | z = 0.100 | y = 0.0997 | erro = 0.160241
Ativação: leaky_relu | z = 0.100 | y = 0.1000 | erro = 0.160000
Objetivo. Antes de saltar para uma rede com múltiplas camadas, ganhar intuição sobre como cada peso e o bias deslocam \(z\), e como cada função de ativação molda a relação entre \(z\) e \(y\).
Observação. Este exercício cobre apenas a propagação direta — os pesos e o bias são fornecidos manualmente. O ajuste automático desses parâmetros pelo gradiente descendente e pela retropropagação será introduzido nas próximas seções.
Tip
Desafio extra: versão gráfica
Quando terminar a versão em modo texto, embrulhe sua função forward(...) em uma interface interativa para experimentar valores no navegador. Duas opções:
ipywidgets— sliders e dropdowns dentro do próprio notebook (recomendado se você está no Colab ou Jupyter); o widget aparece junto com o código.gradio— gera um app web standalone, útil pra compartilhar a demo.
A função forward que você escreveu não muda — basta conectar as entradas da UI aos parâmetros da função.
Backpropagation em um neurônio#
Relembrando: o gradiente como bússola
Antes de derivar a retropropagação, vale fixar a intuição central. Em uma perda \(L(w)\), o gradiente \(\nabla L(w) = \partial L/\partial w\) aponta para a direção de maior subida local — onde a perda mais rapidamente cresce. Para minimizar a perda, basta caminhar no sentido oposto:
onde \(\eta\) é a taxa de aprendizado. Cada iteração desliza \(w\) um passo “morro abaixo”; perto do mínimo, o gradiente fica pequeno e os passos encolhem naturalmente. É exatamente esse ciclo que vamos repetir a seguir para os pesos \(w_1, w_2\) e o bias \(b\) do neurônio.
O exemplo abaixo ilustra essa mecânica em uma perda simples \(L(w) = (w - 3)^2\), com mínimo conhecido em \(w^\ast = 3\). Antes de codar, calculamos a derivada — pela regra da cadeia aplicada à potência:
É essa expressão que aparece no código como dL(w). Partindo de \(w_0 = 0\) com \(\eta = 0{,}2\), o parâmetro converge ao mínimo em poucas iterações:
import numpy as np # arrays
import matplotlib.pyplot as plt # gráficos
# Perda simples com mínimo em w* = 3
def L(w): return (w - 3) ** 2 # função de perda
def dL(w): return 2 * (w - 3) # gradiente (derivada em 1D)
w, eta = 0.0, 0.2 # ponto inicial e taxa de aprendizado
hist = [(w, L(w))] # histórico (w, L) a cada passo
for _ in range(15): # 15 iterações de descida
w -= eta * dL(w) # passo oposto ao gradiente
hist.append((w, L(w))) # guarda o novo ponto
ws, Ls = zip(*hist) # separa em arrays para plotar
# Gráficos: curva de perda + trajetória, e perda vs iteração
fig, axs = plt.subplots(1, 2, figsize=(11, 4))
g = np.linspace(-1, 7, 200)
axs[0].plot(g, L(g), color="#4a90e2", lw=2)
axs[0].plot(ws, Ls, "o-", color="#e74c3c", ms=7, label="descida")
axs[0].plot(3, 0, "*", color="#27ae60", ms=18, label=r"mínimo $w^\ast=3$")
axs[0].set(xlabel=r"$w$", ylabel=r"$L(w)$", title="O parâmetro desce a curva")
axs[1].plot(Ls, "o-", color="#e74c3c", lw=1.5)
axs[1].set(xlabel="iteração", ylabel=r"$L$", title="Perda cai a cada iteração")
for ax in axs: ax.grid(alpha=0.3)
axs[0].legend(); plt.tight_layout(); plt.show()
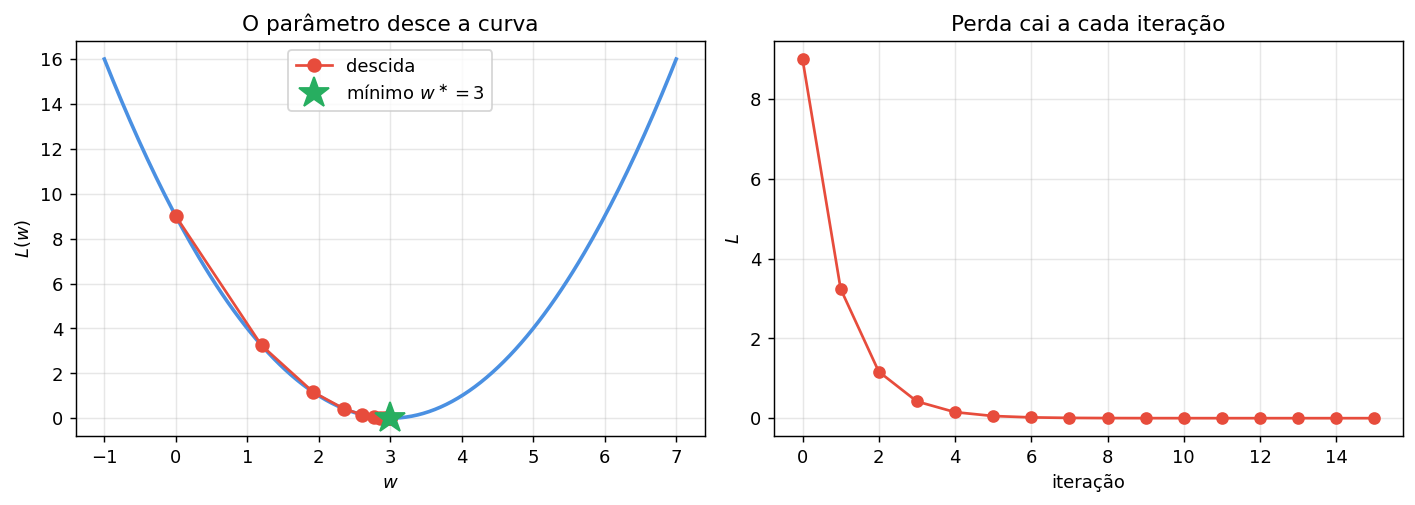
A figura mostra o esqueleto de um treinamento: a cada passo, \(w\) se desloca proporcionalmente a \(-\eta\,\nabla L(w)\), e a perda diminui monotonicamente. A retropropagação a seguir generaliza essa ideia para um neurônio com vários parâmetros — o cálculo dos gradientes via regra da cadeia é a única novidade.
Tip
Versão animada A figura abaixo mostra a mesma trajetória animada, com a reta tangente acompanhando o ponto a cada iteração — fica visível como a tangente vai ficando horizontal ao se aproximar do mínimo (gradiente \(\to 0\), passos encolhem sozinhos):
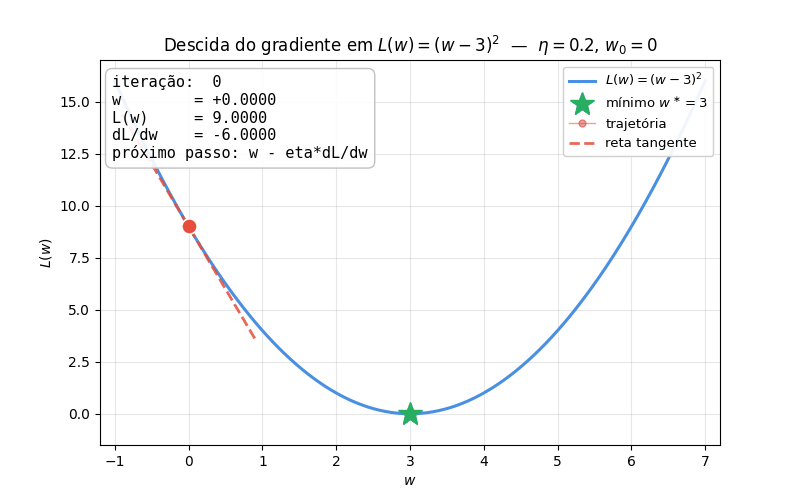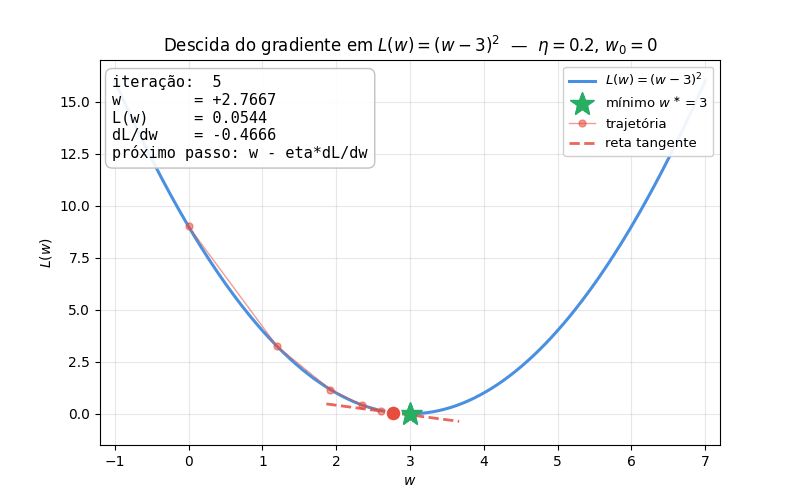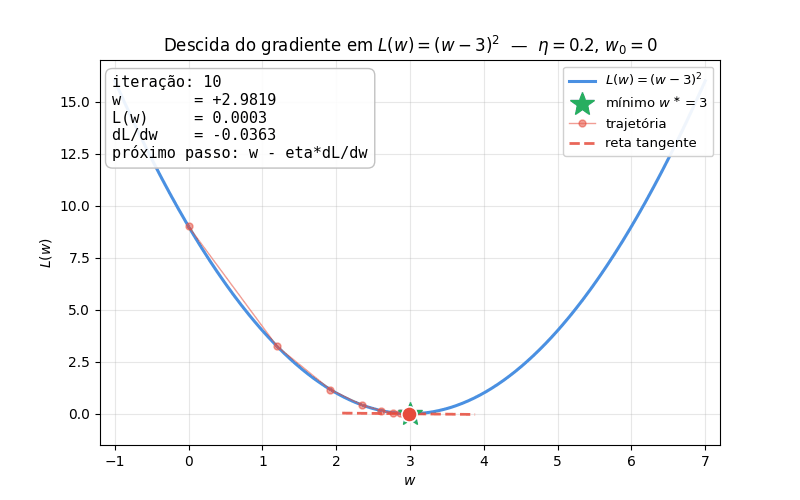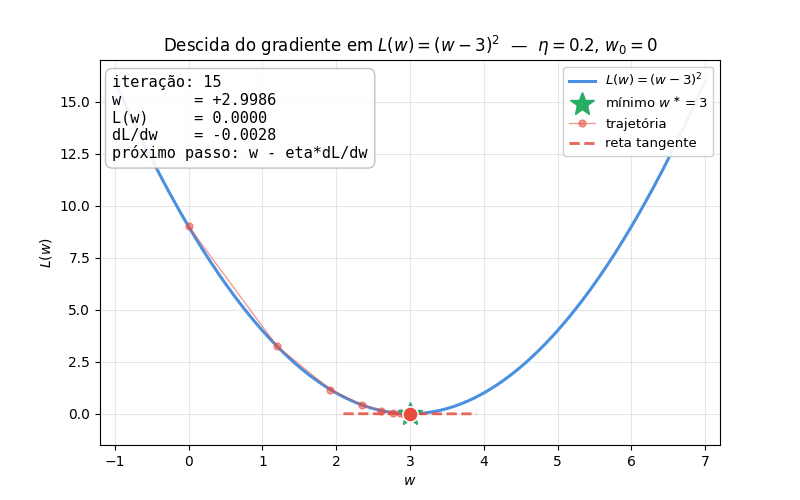
O script que gera o GIF está disponível para download: gradient_descent_animation.py. Edite as variáveis ETA, W0 e N_STEPS no topo do arquivo e rode python gradient_descent_animation.py para experimentar com diferentes taxas de aprendizado e pontos iniciais.
Mínimo local vs mínimo global
Na figura acima a perda \(L(w) = (w-3)^2\) é uma parábola: tem um único mínimo, e qualquer ponto de partida converge para ele. Esse caso é dito convexo. Em redes neurais reais, porém, a perda raramente é convexa — ela depende de milhões de parâmetros e tem uma paisagem cheia de vales, picos e platôs. A figura abaixo mostra uma versão 1D dessa paisagem, com retas tangentes desenhadas em quatro pontos. A inclinação de cada tangente é exatamente o gradiente \(\nabla L(\theta) = dL/d\theta\) — o número que o algoritmo calcula a cada passo:
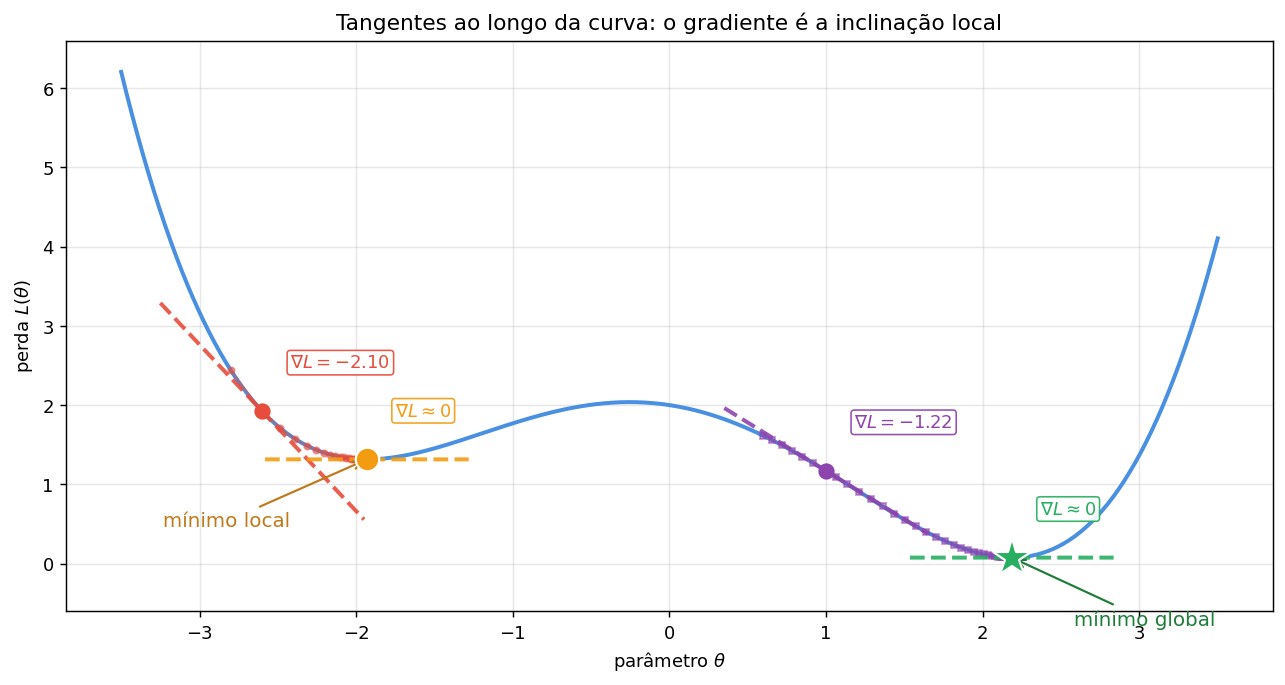
Nessa paisagem coexistem dois mínimos:
Mínimo global — o ponto de menor perda em todo o domínio. É o que gostaríamos de encontrar.
Mínimo local — um ponto onde o gradiente também se anula (\(\nabla L = 0\)) e qualquer pequeno passo aumenta a perda, mas que não é o menor valor possível. O gradiente descendente, por enxergar apenas a inclinação imediata, fica preso ali se for inicializado em sua bacia.
Repare como as duas tangentes diagonais (vermelha e roxa) apontam “morro abaixo” — gradiente negativo significa que basta caminhar para a direita para diminuir a perda. Já nas tangentes horizontais (\(\nabla L \approx 0\)), o algoritmo para de se mover: foi o que aconteceu nos dois mínimos. Por isso o gradiente descendente é incapaz de distinguir um mínimo local de um global — ele só enxerga a inclinação imediata.
Existem ainda os pontos de sela, onde \(\nabla L = 0\) mas a curva sobe em uma direção e desce em outra — em alta dimensão eles são bem mais comuns que mínimos locais. Nada disso impede que o treinamento funcione na prática: otimizadores modernos usam ingredientes como momentum e taxas de aprendizado adaptativas (Adam, RMSProp) para escapar de regiões ruins, e inicializações aleatórias ajudam a explorar bacias diferentes. A próxima seção mostra a derivação no caso convexo simples; o cuidado com não-convexidade volta quando treinarmos a rede do MNIST.
A taxa de aprendizado \(\eta\)
A direção do passo é fixada pelo gradiente, mas o tamanho do passo é controlado pela taxa de aprendizado \(\eta\). A regra é direta:
Ou seja, dobrar \(\eta\) dobra o passo — para o bem ou para o mal. A figura abaixo mostra o efeito de três escolhas de \(\eta\) sobre a parábola \(L(w)=(w-3)^2\), partindo sempre de \(w_0=0\):
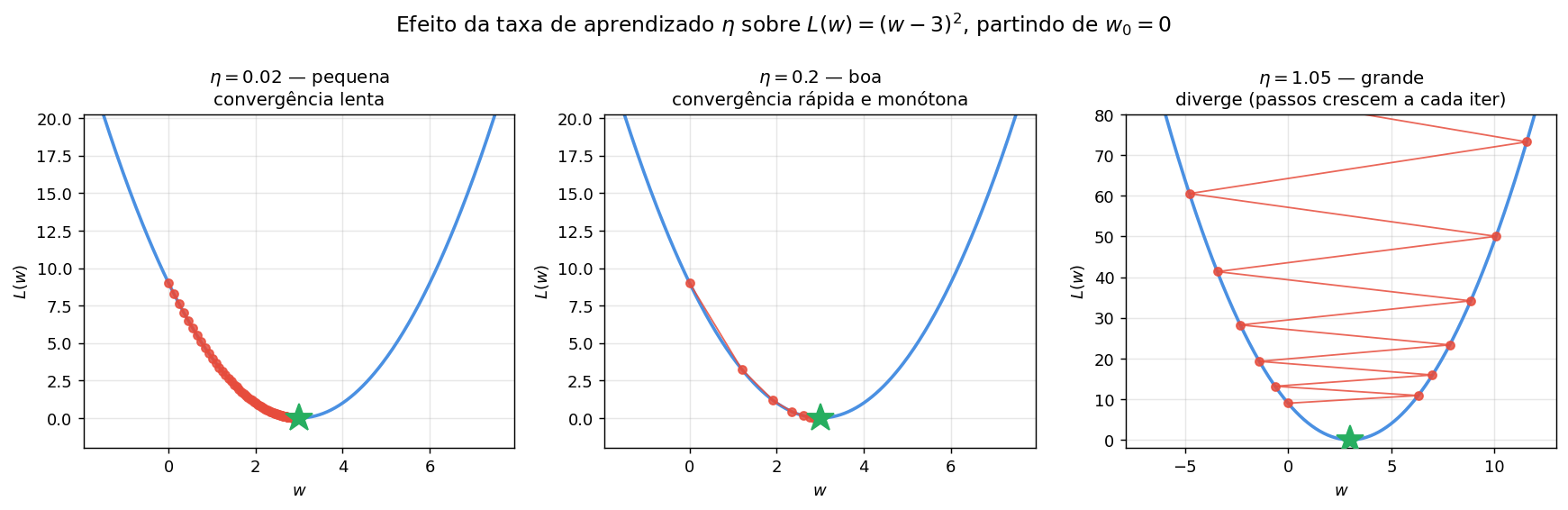
\(\eta\) pequeno demais (esquerda) — os passos são tão curtos que o algoritmo demora dezenas de iterações para chegar perto do mínimo. Treina, mas desperdiça computação.
\(\eta\) apropriado (centro) — passos grandes longe do mínimo, encolhendo naturalmente à medida que o gradiente diminui. Convergência rápida e monótona.
\(\eta\) grande demais (direita) — cada passo ultrapassa o mínimo e aterrissa no lado oposto da parábola, em um ponto mais alto que o anterior. Os passos crescem a cada iteração e a perda diverge.
Como escolher na prática? Para redes neurais reais não há fórmula mágica: começa-se com valores típicos (\(10^{-3}\) a \(10^{-4}\) para Adam; \(10^{-2}\) a \(10^{-1}\) para SGD), ajusta-se observando a curva de perda, e usa-se learning rate scheduling (decair \(\eta\) ao longo do treinamento) ou otimizadores adaptativos como Adam e RMSProp, que ajustam \(\eta\) por parâmetro automaticamente. É justamente o Adam() que aparece no exemplo do MNIST mais adiante.
Antes de generalizar para uma rede inteira, vamos derivar a retropropagação no caso mais simples possível: um único neurônio com uma entrada, treinado para resolver uma regressão linear. Todos os passos cabem em papel e caneta, e a mecânica do gradiente descendente fica transparente.
Cenário: prever a nota a partir das horas de estudo
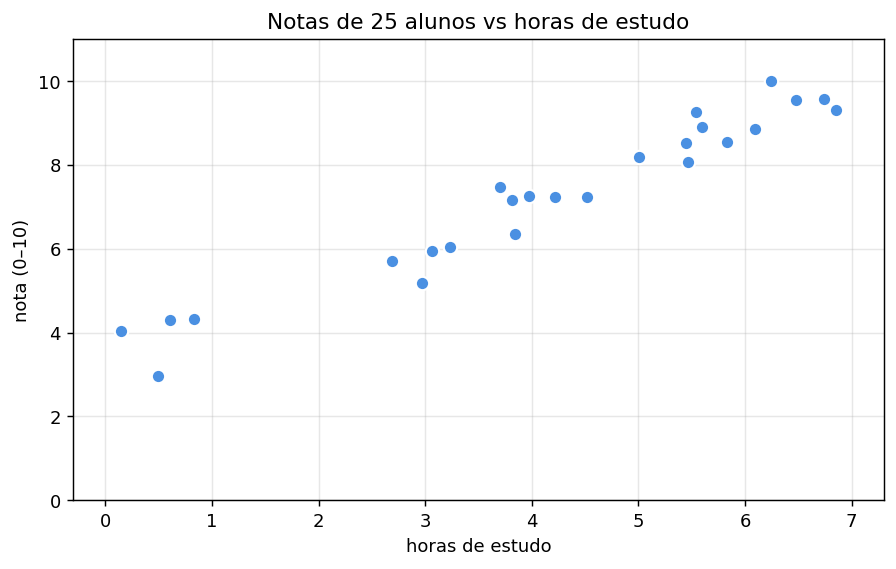
Imagine que coletamos dados de 25 alunos, registrando para cada um as horas de estudo no dia anterior à prova (\(x\)) e a nota obtida (\(y\), na escala 0–10). Visualmente, há uma tendência linear: quem estuda mais tira nota maior, com alguma dispersão natural.
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0)
N = 25
x_data = np.random.uniform(0, 7, N) # horas de estudo
y_data = 1.0 * x_data + 3.0 + np.random.normal(0, 0.5, N) # nota com ruído
y_data = np.clip(y_data, 0, 10) # limita à escala 0–10
plt.figure(figsize=(7, 4.5))
plt.scatter(x_data, y_data, color="#4a90e2", s=55, edgecolor="white", lw=1.2)
plt.xlabel("horas de estudo"); plt.ylabel("nota (0–10)")
plt.title("Notas de 25 alunos vs horas de estudo")
plt.grid(alpha=0.3); plt.tight_layout(); plt.show()
Queremos aprender essa tendência com um único neurônio sem função de ativação (identidade), o que equivale a uma regressão linear:
Os parâmetros do neurônio são os coeficientes da reta. Essa equação é exatamente a mesma equação da reta \(y = a x + b\) que se aprende na escola — só renomeada no vocabulário de redes neurais:
Reta (matemática escolar) |
Neurônio |
Significado geométrico |
|---|---|---|
coeficiente angular (\(a\)) |
peso \(w\) |
inclinação — quanto \(y\) aumenta a cada unidade de \(x\) |
coeficiente linear (\(b\)) |
bias \(b\) |
intercepto — valor de \(y\) quando \(x = 0\) |
Note que o símbolo \(b\) é literalmente o mesmo nas duas notações: o bias do neurônio é o intercepto da reta, e o peso é o coeficiente angular. No nosso cenário, \(w\) é “o quanto a nota sobe a cada hora extra de estudo” e \(b\) é “a nota esperada para alguém que não estudou”. Treinar o neurônio é, na prática, encontrar a melhor reta que passa pelos pontos — exatamente o que faz uma regressão linear clássica.
Setup (uma iteração de exemplo)
Para acompanhar a mecânica passo a passo, considere um aluno hipotético com \(x = 2\) horas de estudo e nota \(y_{\text{real}} = 5\), e parâmetros iniciais \(w = 1{,}0\), \(b = 0{,}0\) — ou seja, a reta inicial é \(y = x\).
Símbolo |
Valor |
|---|---|
Entrada |
\(x = 2\) |
Saída esperada |
\(y_{\text{real}} = 5\) |
Peso inicial |
\(w = 1{,}0\) |
Bias inicial |
\(b = 0{,}0\) |
Ativação |
identidade \(f(z) = z\) |
Perda |
\(L = (y_{\text{pred}} - y_{\text{real}})^2\) |
Taxa de aprendizado |
\(\eta = 0{,}05\) |
Forward pass
A reta inicial \(y = x\) prevê 2 quando o aluno tira 5 — perda alta. O backward dirá em que direção ajustar \(w\) e \(b\).
Backward pass: regra da cadeia
Para atualizar \(w\) e \(b\), precisamos do gradiente da perda em relação a esses parâmetros — ou seja, o quanto \(L\) muda quando mexemos um pouquinho em cada um.
O detalhe é que \(w\) e \(b\) não influenciam \(L\) diretamente: o efeito passa por uma cadeia de operações:
A regra da cadeia decompõe o gradiente de \(L\) em relação a \(w\) no produto das derivadas locais ao longo dessa cadeia:
Vamos calcular cada fator na ordem em que aparece na equação acima (da esquerda para a direita), partindo da perda e caminhando de volta até \(w\) — daí o nome backward:
Derivada local |
O que mede |
Fórmula |
Valor no exemplo |
|---|---|---|---|
\(\partial L/\partial y_{\text{pred}}\) |
inclinação da perda em torno da predição atual |
\(2(y_{\text{pred}} - y_{\text{real}})\) |
\(2(2{,}0 - 5{,}0) = -6{,}0\) |
\(\partial y_{\text{pred}}/\partial z\) |
quanto a saída acompanha o pré-ativador (aqui, identidade) |
\(1\) |
\(1\) |
\(\partial z/\partial w\) |
quanto \(z = w x + b\) varia com \(w\) |
\(x\) |
\(2\) |
Como \(z\) e \(y_{\text{pred}}\) são lineares nos seus argumentos, \(\partial z/\partial w\) e \(\partial y_{\text{pred}}/\partial z\) são constantes (\(x\) e \(1\)) — o efeito de uma variação unitária é exato. Já \(\partial L/\partial y_{\text{pred}}\) depende do ponto atual: é a inclinação da parábola da perda em \(y_{\text{pred}}=2{,}0\) e mudará a cada iteração.
Calculando \(\partial L/\partial w\) passo a passo
Substituindo os valores do exemplo (\(x=2{,}0\), \(y_{\text{real}}=5\), \(y_{\text{pred}}=2{,}0\)) em cada fator:
Fator 1. Da perda quadrática \(L = (y_{\text{pred}} - y_{\text{real}})^2\):
Fator 2. Como a ativação é a identidade (\(y_{\text{pred}} = z\)), uma variação em \(z\) aparece intacta na saída:
Fator 3. Em \(z = wx + b\), o termo \(b\) não depende de \(w\), então só sobra \(x\):
Combinando os três:
Calculando \(\partial L/\partial b\) passo a passo
A cadeia para \(b\) tem os dois primeiros fatores idênticos aos de \(w\) (\(-6{,}0\) e \(1\)). Esse reaproveitamento é a essência do backpropagation: o sinal de erro \(\partial L/\partial y_{\text{pred}}\) é calculado uma vez e propagado para todos os parâmetros do neurônio. Falta só o último fator:
Fator 3’. Em \(z = wx + b\), agora é o termo \(wx\) que não depende de \(b\):
Combinando:
Lendo o sinal e a magnitude. Os dois gradientes são negativos: a perda diminui se aumentarmos \(w\) ou \(b\) — coerente com \(y_{\text{pred}}=2\) estar aquém do alvo \(y_{\text{real}}=5\). A magnitude também conta: \(|\partial L/\partial w| = 12\) é o dobro de \(|\partial L/\partial b| = 6\), porque cada unidade adicionada em \(w\) é multiplicada por \(x=2\) antes de chegar em \(L\) — mexer em \(w\) tem o dobro do impacto.
Atualização dos parâmetros
Recalculando o forward com a nova reta:
A perda caiu de 9,0 para 2,25 em uma iteração: a reta ficou mais inclinada (de \(w=1\) para \(w=1{,}6\)) e elevada (de \(b=0\) para \(b=0{,}3\)), aproximando-se do ponto \((2, 5)\).
Implementação em Python (uma iteração).
import numpy as np
# Aluno hipotético
x = 2.0 # horas de estudo
y_real = 5.0 # nota
w = 1.0 # peso inicial
b = 0.0 # bias inicial
eta = 0.05 # taxa de aprendizado
# Forward (ativação identidade)
y_pred = w * x + b
loss = (y_pred - y_real) ** 2
# Backward (regra da cadeia)
dL_dypred = 2 * (y_pred - y_real)
dL_dw = dL_dypred * x
dL_db = dL_dypred
# Atualização
w -= eta * dL_dw
b -= eta * dL_db
print(f"Forward: y_pred = {y_pred:.2f}, L = {loss:.2f}")
print(f"Grads: dL/dw = {dL_dw:.2f}, dL/db = {dL_db:.2f}")
print(f"Atualiz.: w = {w:.2f}, b = {b:.2f}")
Saída esperada:
Forward: y_pred = 2.00, L = 9.00
Grads: dL/dw = -12.00, dL/db = -6.00
Atualiz.: w = 1.60, b = 0.30
Treinamento sobre todo o dataset. Em vez de aprender com um único aluno, fazemos o neurônio passar por todos os 25 alunos a cada época, usando o gradiente médio. Após algumas centenas de épocas, a reta converge para o melhor ajuste:
import numpy as np
import matplotlib.pyplot as plt
# Mesmo dataset do gráfico anterior
np.random.seed(0) # reprodutibilidade
N = 25 # número de alunos
x_data = np.random.uniform(0, 7, N) # horas de estudo
y_data = np.clip(1.0 * x_data + 3.0 + np.random.normal(0, 0.5, N), 0, 10) # nota com ruído, escala 0–10
# Treinamento (batch gradient descent)
w, b, eta, epochs = 0.0, 0.0, 0.01, 1000 # parâmetros iniciais e hiperparâmetros
loss_hist = [] # histórico de perda para plotar a curva
for _ in range(epochs):
y_pred = w * x_data + b # forward vetorizado em todos os pontos
loss = np.mean((y_pred - y_data) ** 2) # perda média sobre o batch (MSE)
loss_hist.append(loss) # registra a perda da época
dL_dypred = 2 * (y_pred - y_data) / N # gradiente da perda por amostra (já com a média)
dL_dw = np.sum(dL_dypred * x_data) # ∂L/∂w somando contribuição de cada ponto
dL_db = np.sum(dL_dypred) # ∂L/∂b idem para o bias
w -= eta * dL_dw # passo de gradiente em w
b -= eta * dL_db # passo de gradiente em b
print(f"Pesos finais: w = {w:.4f}, b = {b:.4f}")
# Visualização: reta aprendida + curva de perda
fig, axs = plt.subplots(1, 2, figsize=(12, 4.5))
g = np.linspace(0, 7, 100)
axs[0].scatter(x_data, y_data, color="#4a90e2", s=55, edgecolor="white", lw=1.2, label="alunos")
axs[0].plot(g, 0*g, "--", color="#999", lw=1.5, label=r"reta inicial ($w=0, b=0$)")
axs[0].plot(g, w*g + b, "-", color="#e74c3c", lw=2.2,
label=fr"reta aprendida ($w\approx{w:.2f}, b\approx{b:.2f}$)")
axs[0].set(xlabel="horas de estudo", ylabel="nota (0–10)", title="Reta ajustada pelo neurônio")
axs[0].grid(alpha=0.3); axs[0].legend(loc="lower right")
axs[1].plot(loss_hist, color="#e74c3c", lw=1.6)
axs[1].set(xlabel="época", ylabel=r"perda $L$ (MSE)",
title="Perda durante o treinamento", yscale="log")
axs[1].grid(alpha=0.3)
plt.tight_layout(); plt.show()
Saída esperada:
Pesos finais: w = 0.9672, b = 3.1877
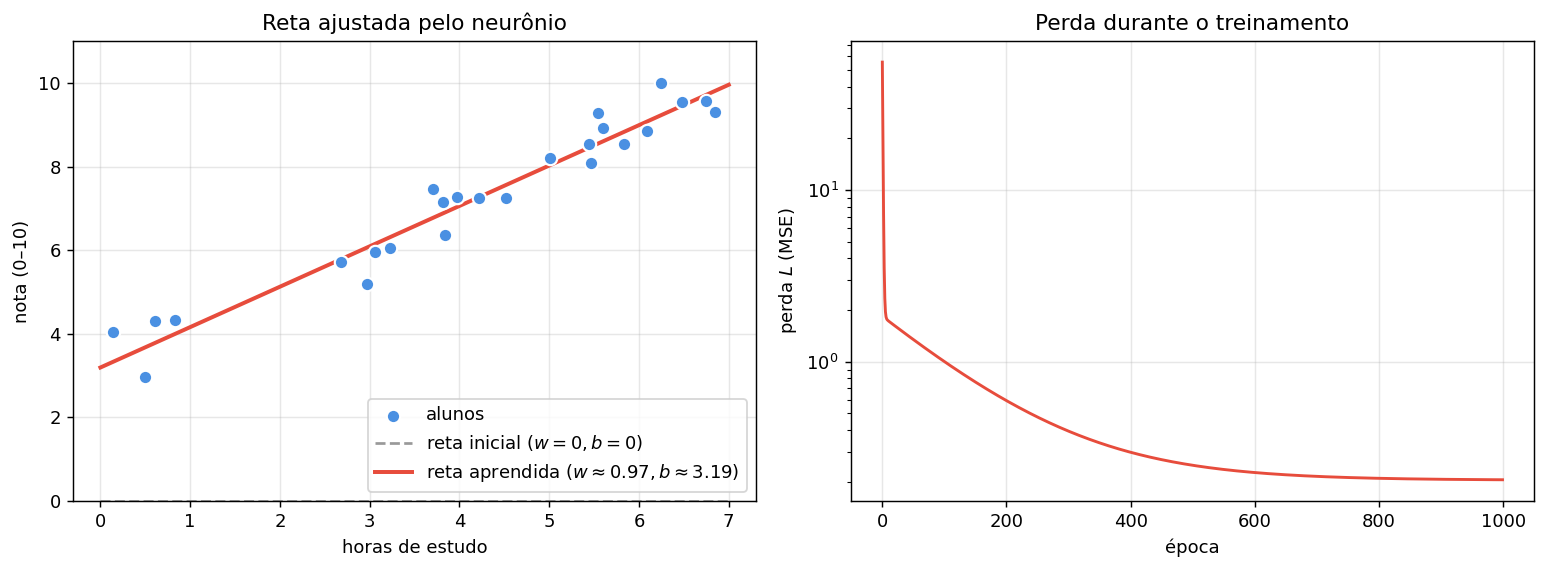
A reta vermelha ajusta bem a nuvem de pontos: o neurônio “aprendeu”, via gradiente, que cada hora extra de estudo aumenta a nota em \(\approx 1\) ponto (inclinação) e que mesmo um aluno com 0 horas tende à nota \(\approx 3\) (intercepto). A curva de perda à direita confirma a convergência: cai monotonicamente até estabilizar perto do mínimo.
Regressão Linear com um Único Neurônio usando o Keras#
Na seção anterior implementamos manualmente o ciclo forward → perda → backward → update, com a regra da cadeia escrita à mão. Frameworks como o Keras (sobre o TensorFlow) automatizam esse pipeline: você declara a arquitetura e a perda, e o framework calcula os gradientes via autograd e aplica o otimizador. Vamos refazer a mesma regressão linear — agora em poucas linhas.
A equação \(y_{\text{pred}} = w x + b\) corresponde exatamente a uma camada densa com uma única unidade e sem função de ativação (Dense(1), sem activation).
Geração dos dados
Geramos 100 pontos seguindo a reta verdadeira \(y = 2x + 1\) com ruído gaussiano:
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
x = np.linspace(0, 10, 100) # 100 pontos no intervalo [0, 10]
y = 2 * x + 1 + np.random.normal(0, 2, size=x.shape) # ruído gaussiano std=2
Modelo com Keras
from tensorflow.keras import Input, Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
model = Sequential([Input(shape=(1,)), Dense(1)]) # 1 neurônio, sem ativação
model.compile(optimizer=SGD(learning_rate=0.001), loss='mse')
y_pred_init = model.predict(x, verbose=0).flatten() # predição com pesos iniciais
history = model.fit(x, y, epochs=20, verbose=0) # 20 épocas de SGD
y_pred = model.predict(x, verbose=0).flatten() # predição depois do treino
Em poucas linhas o Keras replica o que fizemos manualmente: SGD com \(\eta = 0{,}001\), perda MSE, 20 épocas. Por baixo dos panos, cada época percorre todos os 100 pontos calculando \(\partial L/\partial w\) e \(\partial L/\partial b\) via autograd e atualizando os parâmetros.
Antes × depois do treinamento
fig, axs = plt.subplots(1, 2, figsize=(13, 4.5), sharey=True)
for ax, y_hat, titulo in [(axs[0], y_pred_init, "Antes do treinamento"),
(axs[1], y_pred, "Depois do treinamento")]:
ax.scatter(x, y, color="#4a90e2", s=30, label="dados (com ruído)")
ax.plot(x, 2*x + 1, "--", color="#999", lw=1.5, label="reta verdadeira $y=2x+1$")
ax.plot(x, y_hat, "-", color="#e74c3c", lw=2.2, label="reta do modelo")
ax.set(xlabel="x", ylabel="y", title=titulo)
ax.grid(alpha=0.3); ax.legend(loc="upper left")
plt.tight_layout(); plt.show()
Antes do treinamento a “reta do modelo” é arbitrária (pesos aleatórios); depois das 20 épocas ela se aproxima da reta verdadeira \(y = 2x + 1\).
Curva de perda
plt.figure(figsize=(7, 4))
plt.plot(history.history['loss'], color="#e74c3c", lw=1.6)
plt.xlabel("época"); plt.ylabel("MSE")
plt.title("Perda durante o treinamento"); plt.yscale("log")
plt.grid(alpha=0.3); plt.tight_layout(); plt.show()
A perda cai monotonicamente — a mesma curva do batch gradient descent manual, agora produzida automaticamente pelo Keras.
Note
Por que não plotamos “acurácia”? Acurácia é métrica de classificação (proporção de acertos) e não se aplica a regressão, onde não existe acerto/erro binário. Para avaliar regressão, use MSE, RMSE, MAE ou R².
Parâmetros aprendidos
w, b = model.layers[0].get_weights()
print(f"Inclinação (w): {w[0][0]:.4f}")
print(f"Intercepto (b): {b[0]:.4f}")
Saída esperada:
Inclinação (w): 1.9876
Intercepto (b): 1.0342
Os valores aprendidos estão muito próximos da reta verdadeira \(w = 2\), \(b = 1\) — o neurônio recuperou, via gradiente, os parâmetros que geraram os dados (com pequena margem devida ao ruído).
Redes Neurais com Múltiplas Camadas#
Até aqui derivamos a retropropagação para um único neurônio. Agora subimos um nível: primeiro olhamos a anatomia de uma rede com várias camadas, depois estendemos a mesma matemática para o caso geral, e fechamos com um exemplo concreto — classificar dígitos do MNIST.
A imagem abaixo ilustra a topologia clássica de um MLP (Multi-Layer Perceptron):
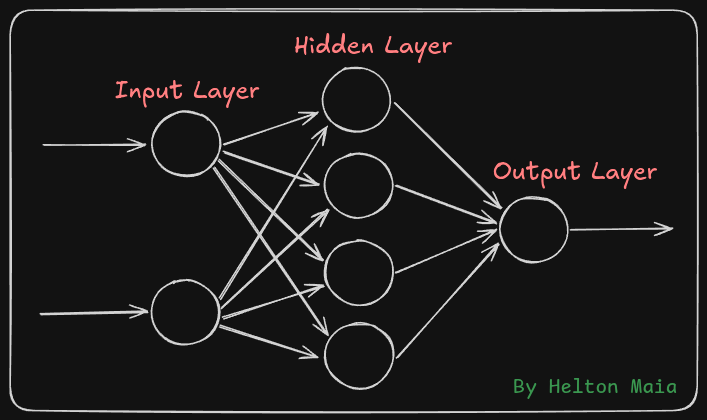
Toda rede feedforward totalmente conectada (fully connected) tem três tipos de camada:
Camada de entrada — recebe os dados brutos (ex.: pixels de uma imagem). Não faz computação; apenas distribui os valores.
Camadas ocultas — onde acontece o trabalho pesado. Cada neurônio combina linearmente as saídas da camada anterior e aplica uma função de ativação não-linear (ReLU, Sigmoid, Tanh, …). Empilhar várias delas permite à rede aprender representações hierárquicas: a primeira camada captura padrões simples, a segunda combina-os em padrões mais abstratos, e assim por diante.
Camada de saída — produz a resposta final. Sua dimensão e ativação dependem da tarefa: 1 neurônio sem ativação para regressão, \(K\) neurônios com softmax para classificar em \(K\) classes, e assim por diante.
Por que empilhar? Uma rede com uma única camada oculta já é, em teoria, um aproximador universal — pode representar qualquer função contínua se tiver neurônios o suficiente. Na prática, redes mais profundas (mais camadas, cada uma com poucos neurônios) costumam aprender com menos parâmetros e melhor generalização do que redes “rasas” e largas. É essa observação empírica que dá origem ao termo deep learning.
Backpropagation generalizado para múltiplas camadas#
A mesma lógica do neurônio único — forward → loss → backward (regra da cadeia) → update — funciona para uma rede inteira. Só muda que escalares viram vetores e matrizes.
As três equações da retropropagação
Para uma rede com \(N\) camadas, com pré-ativação \(\mathbf{z}^{(\ell)} = \mathbf{W}^{(\ell)} \mathbf{a}^{(\ell-1)} + \mathbf{b}^{(\ell)}\) e ativação \(\mathbf{a}^{(\ell)} = f(\mathbf{z}^{(\ell)})\):
A primeira equação calcula o erro \(\boldsymbol{\delta}\) na saída — para o MSE, \(\partial L/\partial \mathbf{a}^{(N)} = 2(\hat{\mathbf{y}} - \mathbf{y}_{\text{real}})\). A segunda propaga \(\boldsymbol{\delta}\) para a camada anterior — note que \(\mathbf{W}^{(\ell+1)\top}\) é a transposta da matriz usada no forward, decorrência direta da convenção \(\mathbf{z} = \mathbf{W}\mathbf{a} + \mathbf{b}\) adotada anteriormente. A terceira dá os gradientes de cada parâmetro a partir de \(\boldsymbol{\delta}\).
Exemplo numérico
Considere uma rede 2 → 2 → 1 com sigmoide em ambas as camadas, MSE como perda e \(\eta = 0{,}005\):
O forward pass dá \(\mathbf{z}^{(1)} = [0{,}1,\ 0{,}4]^\top\), \(\mathbf{a}^{(1)} \approx [0{,}5249,\ 0{,}5987]^\top\), \(z^{(2)} \approx 0{,}9568\), \(y_{\text{pred}} \approx 0{,}7225\) e \(L \approx 0{,}0495\). O código a seguir executa uma iteração completa (forward + backward + atualização):
import numpy as np
def sigmoid(z): return 1 / (1 + np.exp(-z))
def sigmoid_deriv(z): s = sigmoid(z); return s * (1 - s)
x = np.array([[1.0], [2.0]])
y_real = 0.5
W1 = np.array([[0.2, -0.1],
[0.0, 0.3]])
b1 = np.array([[0.1], [-0.2]])
W2 = np.array([[0.3, 0.5]])
b2 = np.array([[0.5]])
# --- Forward ---
z1 = W1 @ x + b1; a1 = sigmoid(z1)
z2 = W2 @ a1 + b2; y_pred = sigmoid(z2)
loss = ((y_pred - y_real) ** 2).item()
# --- Backward ---
delta2 = 2 * (y_pred - y_real) * sigmoid_deriv(z2) # δ^(L)
dL_dW2 = delta2 @ a1.T # ∂L/∂W^(2)
dL_db2 = delta2 # ∂L/∂b^(2)
delta1 = (W2.T @ delta2) * sigmoid_deriv(z1) # δ^(1) (propagação do erro)
dL_dW1 = delta1 @ x.T # ∂L/∂W^(1)
dL_db1 = delta1 # ∂L/∂b^(1)
# --- Atualização ---
eta = 0.005
W1 -= eta * dL_dW1; b1 -= eta * dL_db1
W2 -= eta * dL_dW2; b2 -= eta * dL_db2
print(f"y_pred = {y_pred.item():.4f}, L = {loss:.6f}")
Saída esperada:
y_pred = 0.7225, L = 0.049501
Treinamento por épocas. O loop a seguir repete o ciclo até a saída convergir para \(y_{\text{real}} = 0{,}5\):
import numpy as np
def sigmoid(z): return 1 / (1 + np.exp(-z))
def sigmoid_deriv(z): s = sigmoid(z); return s * (1 - s)
x = np.array([[1.0], [2.0]])
y_real = 0.5
W1 = np.array([[0.2, -0.1],
[0.0, 0.3]])
b1 = np.array([[0.1], [-0.2]])
W2 = np.array([[0.3, 0.5]])
b2 = np.array([[0.5]])
eta = 0.005
epochs = 10000
for epoch in range(1, epochs + 1):
# Forward
z1 = W1 @ x + b1; a1 = sigmoid(z1)
z2 = W2 @ a1 + b2; y_pred = sigmoid(z2)
loss = ((y_pred - y_real) ** 2).item()
# Backward
delta2 = 2 * (y_pred - y_real) * sigmoid_deriv(z2)
delta1 = (W2.T @ delta2) * sigmoid_deriv(z1)
# Update
W2 -= eta * (delta2 @ a1.T); b2 -= eta * delta2
W1 -= eta * (delta1 @ x.T); b1 -= eta * delta1
if epoch in (1, 1000, 5000, 10000):
print(f"Época {epoch:5d} | y_pred = {y_pred.item():.6f} | L = {loss:.6f}")
Saída esperada (resumida):
Época 1 | y_pred = 0.722488 | L = 0.049501
Época 1000 | y_pred = 0.596218 | L = 0.009258
Época 5000 | y_pred = 0.502106 | L = 0.000004
Época 10000 | y_pred = 0.500018 | L = 0.000000
A perda cai monotonicamente e \(y_{\text{pred}}\) converge para \(y_{\text{real}} = 0{,}5\). Repare na direção do cálculo: o erro \(\boldsymbol{\delta}\) nasce na última camada e é propagado para trás, da saída em direção à entrada — daí o nome retropropagação.
Note
Na prática, o backprop é automático
O código acima implementa manualmente cada passo, com fins didáticos. Em frameworks modernos como PyTorch e TensorFlow / Keras, basta declarar a rede e chamar loss.backward() (PyTorch) ou model.fit() (Keras) — o framework constrói o grafo computacional e calcula todos os gradientes via autograd. Isso é o tema da seção Implementando Redes Neurais com Keras e TensorFlow, mais adiante neste capítulo.
Exemplo concreto: classificar dígitos do MNIST#
O MNIST é o “hello world” da visão computacional: 70 000 imagens 28 × 28 em tons de cinza, com dígitos manuscritos de 0 a 9. A figura abaixo mostra um exemplo de cada uma das 10 classes — repare como o mesmo dígito varia bastante entre escritores (inclinação, espessura, formato), o que torna a tarefa não-trivial mesmo sendo o “hello world” da área.

Amostras geradas a partir do conjunto MNIST de Y. LeCun, C. Cortes e C. J. C. Burges (yann.lecun.com/exdb/mnist), distribuído sob licença CC BY-SA 3.0.
Uma arquitetura clássica para resolvê-lo tem o seguinte fluxo:
%%{init: {"flowchart": {"htmlLabels": true, "curve": "basis"}, "themeVariables": {"fontSize": "14px"}} }%%
flowchart LR
IMG["<b>Imagem 28×28</b><br/><i>pixels ∈ [0, 1]</i>"]
FLAT["<b>Flatten</b><br/>784 valores"]
H1["<b>Dense 128</b><br/>ReLU"]
H2["<b>Dense 64</b><br/>ReLU"]
OUT["<b>Dense 10</b><br/>Softmax"]
PRED["<b>Classe prevista</b><br/>0 – 9"]
IMG --> FLAT --> H1 --> H2 --> OUT --> PRED
A imagem 28 × 28 é “achatada” em um vetor de 784 valores, passa por duas camadas ocultas com ReLU (128 e 64 neurônios) e termina em uma camada de saída com 10 neurônios e softmax, que produz uma probabilidade para cada dígito. O treinamento ajusta os pesos via retropropagação mais um otimizador (gradiente descendente, Adam, …) para minimizar a perda — exatamente o ciclo forward → loss → backward → update que derivamos passo a passo. A próxima seção mostra como tudo isso vira poucas linhas de Keras.
Implementando Redes Neurais com Keras e TensorFlow#
Com a API Keras, integrada ao TensorFlow, é possível montar e treinar redes neurais de forma simples e eficiente. Veja abaixo um exemplo usando o clássico conjunto de dados MNIST, que contém imagens de dígitos manuscritos (0 a 9).
Importações, Dados e Normalização
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Input, Flatten, Dense
from tensorflow.keras.optimizers import Adam
# Carrega o dataset MNIST
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Normaliza os dados para o intervalo [0, 1]
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
Arquitetura da Rede Neural
model = Sequential([
Input(shape=(28, 28)),
Flatten(),
Dense(128, activation='relu'),
Dense(64, activation='relu'),
Dense(10, activation='softmax')
])
Explicando cada camada:
Input(shape=(28, 28)): define o formato das imagens de entrada (28x28 pixels).Flatten(): transforma a imagem 2D em um vetor 1D com 784 valores (28 × 28), necessário para conectar à camada densa.Dense(128, activation='relu'): primeira camada oculta com 128 neurônios. A função ReLU (Rectified Linear Unit) permite que apenas valores positivos sejam ativados, acelerando o aprendizado.Dense(64, activation='relu'): segunda camada oculta com 64 neurônios, permitindo a aprendizagem de representações mais complexas.Dense(10, activation='softmax'): camada de saída com 10 neurônios, um para cada classe. A função softmax transforma os valores em probabilidades, que somam 1.
Compilando o Modelo
model.compile(optimizer=Adam(),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
optimizer='adam': define o algoritmo usado para atualizar os pesos.O Adam combina gradiente descendente com momentum e adaptação da taxa de aprendizado.
loss='sparse_categorical_crossentropy': mede o erro entre a saída da rede e a resposta correta.Usamos essa função porque os rótulos são inteiros (0 a 9), e não vetores one-hot.
metrics=['accuracy']: define acurácia como métrica de desempenho, isto é, a proporção de acertos da rede.
Treinamento do Modelo
model.fit(x_train, y_train, epochs=5)
O método
fit()realiza o treinamento da rede:A rede passa por 5 épocas (iterações completas sobre o conjunto de treino).
Os pesos são ajustados com base no erro observado.
O backpropagation é aplicado a cada lote de dados, ajustando os pesos para melhorar as previsões.
Avaliação do Modelo
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f"Precisão no teste: {test_acc:.2%}")
evaluate()calcula a perda e a acurácia nos dados de teste (não vistos durante o treino).Serve como uma estimativa de generalização do modelo para dados reais.
Visualização de Amostras e Inferência
Visualizando dados de treino:
plt.figure(figsize=(10, 2))
for i in range(10):
plt.subplot(1, 10, i + 1)
plt.imshow(x_train[i], cmap='gray')
plt.title(f"Label: {y_train[i]}")
plt.axis('off')
plt.suptitle("Amostras do Conjunto de Treino")
plt.show()
Inferência com imagens de teste:
# Faz inferência com as 10 primeiras imagens de teste
predictions = model.predict(x_test[:10])
plt.figure(figsize=(10, 2))
for i in range(10):
plt.subplot(1, 10, i + 1)
plt.imshow(x_test[i], cmap='gray')
pred_label = np.argmax(predictions[i])
true_label = y_test[i]
plt.title(f"P:{pred_label}\nT:{true_label}", fontsize=8)
plt.axis('off')
plt.suptitle("Inferência: P = Previsto, T = Verdadeiro")
plt.show()
Matriz de Confusão
A matriz de confusão mostra, para cada classe verdadeira, como o modelo classificou as amostras. É uma excelente ferramenta para avaliar o desempenho detalhado do classificador.
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
# Gera previsões para o conjunto de teste
y_pred = model.predict(x_test)
y_pred_labels = np.argmax(y_pred, axis=1)
# Gera a matriz de confusão
cm = confusion_matrix(y_test, y_pred_labels)
# Exibe a matriz graficamente
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=range(10))
disp.plot(cmap=plt.cm.Blues, xticks_rotation=45)
plt.title("Matriz de Confusão - MNIST")
plt.show()
Explicação
confusion_matrix(y_true, y_pred): compara os rótulos verdadeiros com os previstos.Diagonal principal: acertos (previsão == verdadeiro).
Fora da diagonal: erros (confusões entre dígitos).
Com o
ConfusionMatrixDisplay, o gráfico mostra claramente quais dígitos estão sendo confundidos, por exemplo, se o modelo costuma confundir o 4 com o 9.
Tip
Keras 3 e alternativas
A partir de Keras 3 (2023), a API funciona sobre múltiplos backends — TensorFlow, JAX e PyTorch — bastando trocar tensorflow.keras por keras e configurar KERAS_BACKEND. Em paralelo, o PyTorch (Meta) é o framework dominante em pesquisa e tem API mais explícita (você escreve o loop de treino manualmente, usando loss.backward() e optimizer.step()). A escolha entre Keras/TF e PyTorch hoje é mais uma preferência de estilo do que de capacidade — ambos treinam as mesmas redes.
Exercício Prático: Classificação de Imagens com o Dataset Fashion MNIST#
Neste exercício, você vai implementar e treinar sua própria rede neural para classificar imagens de roupas utilizando o conjunto de dados Fashion MNIST, com a API Sequential do Keras (TensorFlow).
O Fashion MNIST contém imagens em tons de cinza com resolução 28x28 pixels, organizadas em 10 categorias de roupas como camisetas, vestidos, tênis, bolsas, entre outros. É um dos datasets mais utilizados para aprendizado e experimentação com redes neurais simples. A figura abaixo mostra um exemplo de cada uma das 10 classes — repare como peças semanticamente próximas (camiseta, pulôver, casaco e camisa) compartilham silhuetas parecidas, o que torna a tarefa mais difícil que o MNIST de dígitos.

Amostras geradas a partir do Fashion-MNIST de Han Xiao, Kashif Rasul e Roland Vollgraf (Zalando Research), distribuído sob licença MIT.
Você deve começar carregando o dataset com tf.keras.datasets.fashion_mnist.load_data() e separando os dados de treino e teste (x_train, y_train, x_test, y_test). Em seguida, normalize as imagens dividindo os valores dos pixels por 255, para que os dados fiquem no intervalo entre 0 e 1.
Visualize algumas imagens de treino para entender melhor o conteúdo do conjunto de dados. Você pode usar o seguinte código para isso:
import matplotlib.pyplot as plt
import numpy as np
from tensorflow.keras.datasets import fashion_mnist
# Carrega o conjunto de dados Fashion MNIST
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
# Rótulos das classes
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
# Normaliza os pixels para o intervalo [0, 1]
x_train, x_test = x_train / 255.0, x_test / 255.0
# Exibe 10 imagens de treino com seus respectivos rótulos
plt.figure(figsize=(10, 2))
for i in range(10):
plt.subplot(1, 10, i + 1)
plt.imshow(x_train[i], cmap='gray')
plt.title(class_names[y_train[i]], fontsize=8)
plt.axis('off')
plt.suptitle("Amostras do Fashion MNIST")
plt.show()
Depois disso, implemente uma rede neural com a API Sequential. Você poderá escolher:
Quantas camadas ocultas usar
Quantos neurônios em cada camada
Quais funções de ativação utilizar (como
relu,sigmoid,tanh)
A camada de saída deve conter 10 neurônios com ativação softmax, correspondentes às 10 categorias de roupas.
Compile o modelo com a função de perda sparse_categorical_crossentropy e a métrica accuracy. Experimente pelo menos dois otimizadores entre os seguintes e compare seus desempenhos:
adamadamw(variante moderna do Adam com decaimento de peso desacoplado — padrão em Transformers)sgdrmspropadagrad
Treine seu modelo com model.fit() por no mínimo 5 épocas. Observe e anote os valores de perda e acurácia durante o treinamento.
Depois do treinamento, avalie o desempenho do modelo no conjunto de teste usando model.evaluate() e imprima a acurácia final. Compare os resultados obtidos com cada otimizador testado.
Para entender melhor onde o modelo acerta ou erra, gere uma matriz de confusão. Você pode usar o código abaixo:
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
# Previsões no conjunto de teste
y_pred = model.predict(x_test)
y_pred_labels = np.argmax(y_pred, axis=1)
# Matriz de confusão
cm = confusion_matrix(y_test, y_pred_labels)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=class_names)
disp.plot(cmap=plt.cm.Blues, xticks_rotation=45)
plt.title("Matriz de Confusão - Fashion MNIST")
plt.show()
Como tarefa adicional, monte um gráfico comparando a acurácia e a função de perda ao longo das épocas para cada otimizador. Isso ajudará a visualizar e justificar qual otimizador teve melhor desempenho em termos de velocidade de aprendizado e precisão final.
Experimente uma RNA no seu navegador#
O TensorFlow Playground é um simulador interativo de redes neurais executado inteiramente no navegador. Você configura arquitetura, função de ativação, learning rate e regularização, e vê em tempo real como a rede aprende fronteiras de decisão em datasets 2D.
Experimentos sugeridos:
Rede rasa × profunda — resolva o dataset espiral (o mais difícil) com 1 camada, depois com 3 camadas. Observe o impacto da profundidade.
Compare ativações — rode o mesmo problema com ReLU, Tanh e Sigmoid. Observe como a Sigmoid sofre vanishing gradient em redes mais profundas.
Regularização — ative L1 e L2 e observe como os pesos respondem: L1 tende a zerar pesos (esparsidade); L2 os mantém pequenos.
Taxa de aprendizado — experimente valores entre
0.001e1.0. Muito baixa = convergência lenta; muito alta = oscila.
Referências e Conteúdo Extra#
Frameworks
TensorFlow / Keras — ecossistema Google; Keras 3 é agnóstico de backend (TF/JAX/PyTorch).
PyTorch — framework dominante em pesquisa (Meta).
Plataformas e datasets
Hugging Face — hub de modelos pré-treinados (LLMs, visão, áudio) e datasets; referência para foundation models.
Kaggle — plataforma do Google com competições, datasets públicos (incluindo o Fashion MNIST), notebooks gratuitos com GPU/TPU e a trilha Kaggle Learn para machine learning e deep learning.
Livros
Dive into Deep Learning (D2L.ai) — livro online interativo, em Python, cobrindo CNNs, Transformers, atenção.
Goodfellow, Bengio, Courville — Deep Learning (MIT Press, 2016) — referência teórica canônica.
Papers e relatórios técnicos
Os modelos citados na seção Estado da Arte em 2026 não publicam, em geral, papers dedicados a cada release — system cards e blog posts costumam fazer esse papel. Quando o relatório técnico está disponível, o link aparece abaixo; para versões mais recentes (2026), consulte a página oficial do modelo, onde o relatório técnico costuma ser publicado junto com o lançamento.
Qwen3 Technical Report — arXiv:2505.09388 — base da família Qwen, antecessora do Qwen 3.6 e do Qwen3-VL.
DeepSeek-V3 Technical Report — arXiv:2412.19437 — arquitetura MoE que serve de base para o V4.
DeepSeek-R1 — arXiv:2501.12948 — modelo de raciocínio aberto.
MiniMax-01 — arXiv:2501.08313 — relatório técnico que introduz a arquitetura da família M.
Gemini 1.5 (Reid et al., 2024) — arXiv:2403.05530 — primeiro Gemini com janela de 1M de tokens.
GPT-4 Technical Report (OpenAI, 2023) — arXiv:2303.08774 — relatório oficial; modelos posteriores (GPT-4o, série o, GPT-5/5.5) passaram a usar system cards.
GPT-3 (Brown et al., 2020) — arXiv:2005.14165 — paper que introduziu in-context learning em escala.
On the Measure of Intelligence (Chollet, 2019) — arXiv:1911.01547 — origem do benchmark ARC-AGI, do qual o ARC-AGI-2 (2025) é a evolução.
Cursos e séries
Neural Networks: Zero to Hero (Andrej Karpathy, YouTube) — série de aulas construindo redes neurais do zero, incluindo backprop manual e um mini-GPT. Altamente recomendada hoje.
fast.ai Practical Deep Learning — curso top-down que prioriza aplicação prática.
Vídeos (intro)