Capítulo 4: Visão Computacional#

Introdução ao Processamento Digital de Imagens#
O processamento digital de imagens é uma área fundamental para a visão computacional, pois permite extrair, analisar e interpretar informações visuais de forma automatizada, habilitando diversas aplicações em áreas como reconhecimento facial, automação industrial, medicina, entre outras. Segundo Gonzales e Woods, em Digital Image Processing, o processamento de imagens facilita a compreensão e manipulação de informações visuais, oferecendo ferramentas e técnicas para transformar e melhorar imagens digitais.
Importação de Bibliotecas#
Para realizar o processamento de imagens em Python, usaremos as bibliotecas OpenCV, NumPy e Matplotlib:
OpenCV é uma biblioteca de visão computacional de código aberto que oferece funções para análise e processamento de imagens e vídeos.
NumPy é uma biblioteca essencial para computação científica, fornecendo suporte a arrays multidimensionais e operações matemáticas de alto desempenho.
Matplotlib permite criar visualizações e gráficos para representar dados e exibir imagens.
Vamos começar importando essas bibliotecas:
import cv2
from google.colab.patches import cv2_imshow # Usado para exibir imagens no Google Colab
import numpy as np
import matplotlib.pyplot as plt
Leitura e Exibição de Imagens com OpenCV e Matplotlib#
As imagens digitais são compostas por uma grade de pixels, onde cada pixel armazena valores de intensidade em um ou mais canais:
Imagens em escala de cinza têm um único canal, que representa a intensidade de luz de cada pixel.
Imagens coloridas têm três canais principais: vermelho, verde e azul (RGB). No OpenCV, as imagens são lidas no formato BGR (azul, verde, vermelho), e a ordem dos canais precisa ser ajustada para exibição correta em outras bibliotecas, como o Matplotlib.
Vamos ver como carregar e exibir uma imagem, considerando o formato dos canais:
{kind=link}
# Carrega a imagem
img = cv2.imread('sun.jpeg')
# Exibe a imagem usando OpenCV (no Colab, com cv2_imshow)
cv2_imshow(img)
# Exibe a imagem usando Matplotlib (convertendo de BGR para RGB)
plt.figure(figsize=(8, 6))
plt.imshow(img[:, :, ::-1]) # Inverte os canais BGR para RGB
plt.axis('off')
plt.show()

Figura - Exibição de imagem com modificada.
Neste exemplo, usamos cv2.imread() para carregar a imagem no formato BGR e, ao exibir com Matplotlib, invertemos os canais para o formato RGB.
Manipulação Básica de Canais#
Podemos manipular os canais individualmente para realizar ajustes de cor. Abaixo, fazemos uma modificação simples no canal vermelho:
# Aumenta a intensidade do canal vermelho em 25 para todos os pixels
img[:, :, 2] += 25 # O canal vermelho é o índice 2 no formato BGR
# Exibe a imagem modificada
cv2_imshow(img)

Figura - Exibição de imagem com Matplotlib, convertendo para o formato RGB.
Neste código, aumentamos a intensidade do canal vermelho (índice 2 no formato BGR) em 25 para todos os pixels, destacando os tons avermelhados da imagem.
Representação de Imagens#
As imagens digitais podem ser representadas de diferentes maneiras, dependendo do contexto e do propósito. Nesta seção, exploraremos como as imagens em cores e em escala de cinza são organizadas e representadas, além de como manipular seus canais e realizar conversões entre espaços de cores usando OpenCV.
Canais de Cor (RGB, BGR, Escala de Cinza)#
Imagens em escala de cinza contêm um único canal, onde cada pixel armazena uma intensidade de luz variando de 0 (preto) a 255 (branco), para imagens de 8 bits.
Imagens coloridas são compostas por múltiplos canais de cor. A representação mais comum é a RGB (Red, Green, Blue), onde cada cor é combinada a partir de três canais: vermelho, verde e azul. No entanto, o OpenCV usa o formato BGR (Blue, Green, Red), então as imagens coloridas carregadas em OpenCV têm os canais nesta ordem.
Abaixo, mostramos como carregar uma imagem colorida e uma imagem em escala de cinza:
{kind=link}
# Carrega a imagem colorida
color_img = cv2.imread('drone.jpeg')
# Carrega a imagem em escala de cinza
gray_img = cv2.imread('drone.jpeg', cv2.IMREAD_GRAYSCALE)
# Exibe a imagem colorida e a em escala de cinza
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.imshow(color_img[:, :, ::-1]) # Convertendo BGR para RGB
plt.title("Imagem Colorida")
plt.axis('off')
plt.subplot(1, 2, 2)
plt.imshow(gray_img, cmap='gray')
plt.title("Imagem em Escala de Cinza")
plt.axis('off')
plt.show()

Figura - Imagem RGB vs Escala de Cinza.
Separação e Visualização de Canais Individuais#
A separação de canais permite analisar cada componente de cor individualmente. No OpenCV, podemos separar os canais usando índices diretamente ou a função cv2.split(). Além de visualizar cada canal em escala de cinza, também podemos exibir cada um em sua cor original (vermelho, verde e azul).
# Separa os canais BGR da imagem colorida usando cv2.split()
blue_channel, green_channel, red_channel = cv2.split(color_img)
# Separa manualmente (opcional)
#blue_channel = color_img[:, :, 0]
#green_channel = color_img[:, :, 1]
#red_channel = color_img[:, :, 2]
# Exibe cada canal individualmente em escala de cinza
plt.figure(figsize=(12, 4))
plt.subplot(1, 3, 1)
plt.imshow(blue_channel, cmap='gray')
plt.title("Canal Azul (Escala de Cinza)")
plt.axis('off')
plt.subplot(1, 3, 2)
plt.imshow(green_channel, cmap='gray')
plt.title("Canal Verde (Escala de Cinza)")
plt.axis('off')
plt.subplot(1, 3, 3)
plt.imshow(red_channel, cmap='gray')
plt.title("Canal Vermelho (Escala de Cinza)")
plt.axis('off')
plt.show()
# Exibe cada canal individualmente em suas cores
# Criando imagens onde apenas o canal específico é mantido
blue_img = np.zeros_like(color_img)
green_img = np.zeros_like(color_img)
red_img = np.zeros_like(color_img)
# Atribuindo o canal específico para a cor correspondente
blue_img[:, :, 0] = blue_channel # Canal azul
green_img[:, :, 1] = green_channel # Canal verde
red_img[:, :, 2] = red_channel # Canal vermelho
# Plotando os canais nas cores originais
plt.figure(figsize=(12, 4))
plt.subplot(1, 3, 1)
plt.imshow(blue_img[:, :, ::-1]) # Convertendo BGR para RGB
plt.title("Canal Azul")
plt.axis('off')
plt.subplot(1, 3, 2)
plt.imshow(green_img[:, :, ::-1]) # Convertendo BGR para RGB
plt.title("Canal Verde")
plt.axis('off')
plt.subplot(1, 3, 3)
plt.imshow(red_img[:, :, ::-1]) # Convertendo BGR para RGB
plt.title("Canal Vermelho")
plt.axis('off')
plt.show()


Figura - Imagem RGB em seus canais.
Neste exemplo, cada canal é exibido em escala de cinza e em sua cor original. Na visualização em escala de cinza, a intensidade de cada pixel representa a contribuição daquele canal para a cor final na imagem. Já na exibição em cores, cada imagem mostra o canal individual destacado na cor correspondente.
Conversão entre Espaços de Cores (RGB, HSV, Escala de Cinza)#
Além do formato RGB/BGR, as imagens podem ser representadas em outros espaços de cores, como HSV (Hue, Saturation, Value), que é muito útil para manipulação de cores e segmentação.
RGB para Escala de Cinza: Podemos converter uma imagem RGB para escala de cinza para simplificar o processamento de imagem, removendo a informação de cor.
RGB para HSV: No espaço de cor HSV, as cores são separadas por tonalidade (Hue), saturação (Saturation) e valor (Value), o que pode ser vantajoso para destacar cores específicas ou aplicar filtros.
# Converte a imagem para escala de cinza
gray_img = cv2.cvtColor(color_img, cv2.COLOR_BGR2GRAY)
# Converte a imagem para o espaço de cor HSV
hsv_img = cv2.cvtColor(color_img, cv2.COLOR_BGR2HSV)
# Exibe as imagens convertidas
plt.figure(figsize=(12, 6))
# Imagem em escala de cinza
plt.subplot(1, 2, 1)
plt.imshow(gray_img, cmap='gray')
plt.title("Escala de Cinza")
plt.axis('off')
# Imagem em HSV (mostrada como RGB para visualização correta)
plt.subplot(1, 2, 2)
plt.imshow(cv2.cvtColor(hsv_img, cv2.COLOR_HSV2RGB))
plt.title("Espaço de Cor HSV")
plt.axis('off')
plt.show()
Explicação sobre o Espaço HSV:
Hue (Ton): Representa a cor, variando de 0 a 179 em OpenCV.
Saturation (Saturação): Representa a intensidade da cor, de 0 (sem cor) a 255 (cor intensa).
Value (Valor): Representa o brilho da cor, de 0 (preto) a 255 (brilhante).
Converter uma imagem para o espaço HSV permite que manipulemos diretamente o tom e a saturação, facilitando operações como filtragem por cor ou ajuste de brilho e contraste.
Histogramas de Imagens#
O histograma de uma imagem é uma representação gráfica que mostra a distribuição da intensidade de pixels. Ele é uma ferramenta fundamental para analisar e entender o conteúdo visual de uma imagem, sendo utilizado em várias tarefas de processamento de imagens e visão computacional, como ajuste de contraste, segmentação e equalização de imagem.
Definição e Importância dos Histogramas#
Um histograma de imagem exibe a frequência de cada valor de intensidade de pixel. Em uma imagem em escala de cinza, o histograma mostra quantos pixels possuem cada intensidade (de 0 a 255, para imagens de 8 bits). Em imagens coloridas, podemos calcular histogramas para cada canal de cor (BGR ou RGB), obtendo uma visão da distribuição de intensidades em cada componente de cor.
Os histogramas são importantes porque ajudam a entender características da imagem, como brilho, contraste e quantidade de informações em diferentes níveis de intensidade. Por exemplo:
Imagens com baixo contraste apresentam histogramas concentrados em uma faixa estreita de intensidades.
Imagens muito escuras ou muito claras terão histogramas deslocados para os extremos (valores baixos ou altos).
Imagens balanceadas terão histogramas distribuídos por uma faixa mais ampla de valores.
Cálculo de Histogramas em Escala de Cinza e em Canais de Cor#
No OpenCV, podemos calcular histogramas com a função cv2.calcHist(), que calcula a frequência de cada intensidade para uma imagem ou para um canal específico.
Para uma imagem em escala de cinza, obtemos um histograma com 256 valores, representando a distribuição de intensidades de 0 a 255.
Para uma imagem colorida, podemos calcular o histograma de cada canal individualmente.
# Carrega a imagem em escala de cinza e em cores
gray_img = cv2.imread('drone.jpeg', cv2.IMREAD_GRAYSCALE)
color_img = cv2.imread('drone.jpeg')
# Calcula o histograma para a imagem em escala de cinza
gray_hist = cv2.calcHist([gray_img], [0], None, [256], [0, 256])
# Calcula o histograma para cada canal BGR da imagem colorida
blue_hist = cv2.calcHist([color_img], [0], None, [256], [0, 256])
green_hist = cv2.calcHist([color_img], [1], None, [256], [0, 256])
red_hist = cv2.calcHist([color_img], [2], None, [256], [0, 256])
Explicação dos parâmetros:
[color_img]: A imagem de entrada para o cálculo do histograma. Colocamos entre colchetes porquecv2.calcHistespera uma lista de imagens, mesmo que seja apenas uma.[0]: O índice do canal de cor para o qual o histograma será calculado. No OpenCV, as imagens coloridas em formato BGR possuem os canais na ordem:Canal 0 = Azul (B)
Canal 1 = Verde (G)
Canal 2 = Vermelho (R)
Aqui,
[0]indica que queremos o histograma para o canal azul da imagem.None: A máscara para o cálculo do histograma. Se quiséssemos calcular o histograma para apenas uma região específica da imagem, poderíamos fornecer uma máscara binária. UsandoNone, calculamos o histograma para a imagem inteira.[256]: O número de bins (ou classes) no histograma, que define o nível de detalhamento. Um valor de[256]significa que cada intensidade de 0 a 255 será contada individualmente, resultando em um histograma detalhado para cada nível de intensidade.[0, 256]: O intervalo de intensidades a ser considerado no histograma.[0, 256]cobre o intervalo completo para uma imagem de 8 bits, que possui intensidades de 0 a 255.
Plotagem e Interpretação dos Histogramas#
Vamos exibir o histograma da imagem em escala de cinza e de cada canal da imagem colorida usando Matplotlib.
# Exibe o histograma da imagem em escala de cinza
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.plot(gray_hist, color='black')
plt.title("Histograma - Escala de Cinza")
plt.xlabel("Intensidade de Pixel")
plt.ylabel("Frequência")
# Exibe o histograma dos canais de cor (BGR)
plt.subplot(1, 2, 2)
plt.plot(blue_hist, color='blue', label='Azul')
plt.plot(green_hist, color='green', label='Verde')
plt.plot(red_hist, color='red', label='Vermelho')
plt.title("Histograma - Canais de Cor")
plt.xlabel("Intensidade de Pixel")
plt.ylabel("Frequência")
plt.legend()
plt.tight_layout()
plt.show()
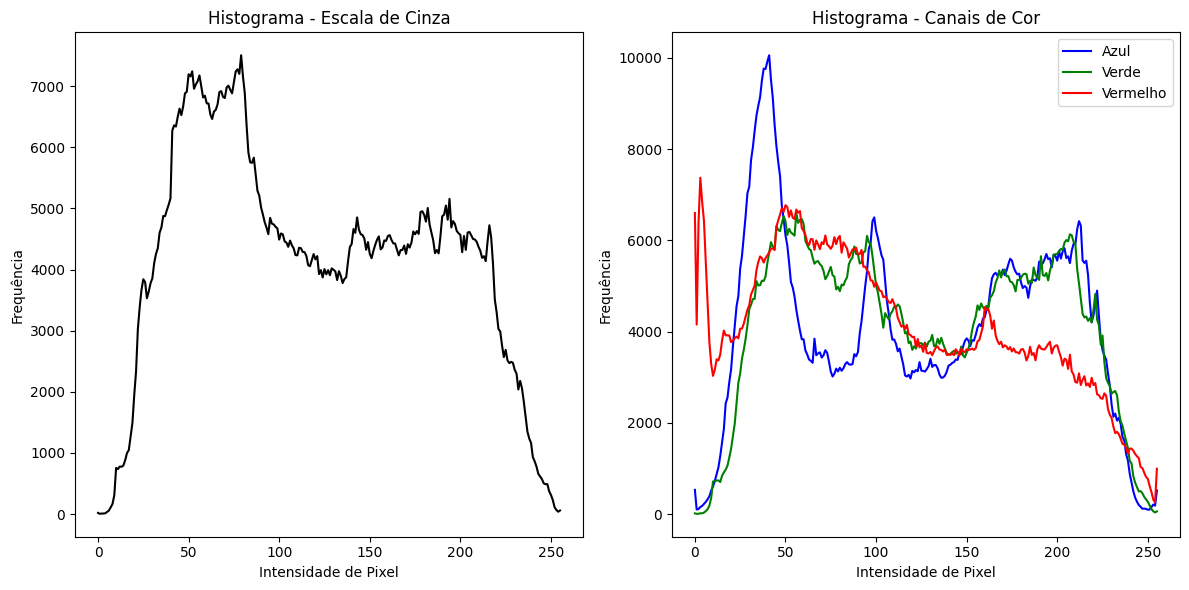
Figura - Histogramas da Imagem.
Interpretação dos Histogramas:
Histograma da Imagem em Escala de Cinza
O gráfico mostra a distribuição de intensidades de pixel de 0 (preto) a 255 (branco).
Um pico em uma faixa de intensidade indica uma alta frequência de pixels naquela intensidade.
Se o histograma está concentrado em valores baixos, a imagem tende a ser mais escura; se está concentrado em valores altos, a imagem tende a ser mais clara.
Histograma dos Canais de Cor
Cada linha do gráfico representa a distribuição de intensidades de um canal de cor (azul, verde, vermelho).
A distribuição dos canais pode dar uma ideia da tonalidade predominante da imagem. Por exemplo, se o canal vermelho tem valores mais altos, a imagem tende a ter tons avermelhados.
Imagens com bom equilíbrio de cores terão uma distribuição mais uniforme entre os três canais.
Os histogramas são essenciais para realizar ajustes e transformar imagens. Ao longo do processamento de imagens, podemos utilizar histogramas para aprimorar contraste (como na equalização de histogramas) ou para segmentar imagens com base em faixas de intensidade.
Exercício: Análise de Histogramas de Imagem - Escala de Cinza e Canais de Cor#
Neste exercício, você irá:
Acessar uma imagem da internet.
Carregar e exibir a imagem.
Separar os canais de cor (BGR) e calcular os histogramas.
Comparar os histogramas dos canais de cor com o histograma em escala de cinza.
Interpretar a distribuição de intensidade de pixels em cada canal e em escala de cinza.
Etapas:
Acessar e Carregar a Imagem da Web
Utilize a biblioteca
requestspara baixar a imagem e o OpenCV para carregá-la. Vamos usar uma imagem da ECT disponível neste link descrito no code.Complete o código abaixo para carregar a imagem:
import cv2 import numpy as np import requests from matplotlib import pyplot as plt # URL da imagem url = 'https://www.ect.ufrn.br/wp-content/uploads/2020/02/ect-ufrn-1.png' # Baixa a imagem e converte para um formato que o OpenCV possa ler response = requests.get(url, stream=True).raw image = np.asarray(bytearray(response.read()), dtype="uint8") color_img = cv2.imdecode(image, cv2.IMREAD_COLOR) # Converte para escala de cinza gray_img = ...
Exibir a Imagem e Seus Canais
Complete o código para mostrar a imagem original em cores e a imagem em escala de cinza.
plt.figure(figsize=(10, 5)) # Imagem em cores plt.subplot(1, 2, 1) plt.imshow(cv2.cvtColor(color_img, cv2.COLOR_BGR2RGB)) plt.title('Imagem em Cores') # Imagem em escala de cinza plt.subplot(1, 2, 2) plt.imshow(..., cmap='gray') plt.title('Imagem em Escala de Cinza') plt.tight_layout() plt.show()
Calcular os Histogramas
Calcule o histograma para a imagem em escala de cinza.
Calcule o histograma para cada canal de cor (azul, verde e vermelho) da imagem colorida.
Complete o código abaixo para os cálculos:
# Histograma da imagem em escala de cinza gray_hist = cv2.calcHist([...]) # Histogramas dos canais BGR blue_hist = cv2.calcHist([...]) green_hist = cv2.calcHist([...]) red_hist = cv2.calcHist([...])
Plotar e Comparar os Histogramas
Plote o histograma em escala de cinza e os histogramas dos canais de cor para comparar a distribuição de intensidade. Complete o código:
plt.figure(figsize=(12, 6)) # Histograma em escala de cinza plt.subplot(1, 2, 1) plt.plot(..., color='black') plt.title('Histograma - Escala de Cinza') plt.xlabel('Intensidade de Pixel') plt.ylabel('Frequência') # Histogramas dos canais de cor plt.subplot(1, 2, 2) plt.plot(..., color='blue', label='Azul') plt.plot(..., color='green', label='Verde') plt.plot(..., color='red', label='Vermelho') plt.title('Histograma - Canais de Cor') plt.xlabel('Intensidade de Pixel') plt.ylabel('Frequência') plt.legend() plt.tight_layout() plt.show()
Análise e Interpretação
Com base nos histogramas:
Observe a distribuição dos valores de intensidade nos canais de cor e compare com a escala de cinza.
Responda às perguntas:
O histograma em escala de cinza mostra uma boa distribuição de brilho e contraste? Justifique.
Resposta:
Há um canal predominante (azul, verde ou vermelho) na imagem? Explique sua observação.
Resposta:
Equalização de Histograma#
A equalização de histograma é uma técnica de processamento de imagem usada para melhorar o contraste de uma imagem, especialmente em cenas onde predominam áreas muito escuras ou muito claras. O objetivo dessa técnica é redistribuir as intensidades dos pixels para que áreas de baixa variação de brilho sejam ajustadas, proporcionando uma visualização mais detalhada e equilibrada.
A ideia por trás da equalização de histograma é transformar o histograma da imagem em uma forma mais uniforme. Isso significa redistribuir os valores de intensidade de pixel para que a imagem final tenha uma variação de tons mais equilibrada, tornando áreas escuras e claras mais visíveis e detalhadas.
Etapas para a Equalização de Histograma
Calcular o Histograma da Imagem Original: O histograma é um gráfico que mostra a frequência de cada intensidade de pixel na imagem. Imagens com baixo contraste terão histogramas concentrados em uma faixa estreita de valores.
Calcular a Função de Distribuição Cumulativa (CDF): A CDF (Função de Distribuição Cumulativa) é essencial para equalizar a imagem. A CDF em um ponto específico representa a soma de todas as frequências de intensidade até aquele ponto, normalizada para que a intensidade máxima seja 255 (para uma imagem de 8 bits). A CDF é usada para mapear os valores de intensidade dos pixels originais para novos valores de intensidade, aumentando o contraste da imagem.
Matematicamente, a CDF de uma intensidade \( k \) pode ser calculada como:
\( CDF(k) = \sum_{j=0}^{k} P(j) \)
onde \( P(j) \) é a probabilidade de ocorrência da intensidade \( j \) (ou a frequência relativa no histograma).
Mapear os Valores dos Pixels da Imagem Original Usando a CDF: Para cada pixel na imagem original, o valor de intensidade é substituído pelo valor correspondente da CDF. Esse mapeamento resulta em uma imagem final com contraste aprimorado e uma distribuição de intensidade mais uniforme.
Exemplo de Código para Imagem em Escala de Cinza
Aqui está um exemplo de código em Python usando OpenCV para aplicar a equalização de histograma em uma imagem em escala de cinza:
import cv2
import matplotlib.pyplot as plt
# Carregar a imagem em escala de cinza
img_original = cv2.imread('sun.jpeg', cv2.IMREAD_GRAYSCALE)
# Calcular o histograma da imagem original
hist_original = cv2.calcHist([img_original], [0], None, [256], [0, 256])
# Aplicar equalização de histograma
img_equalizada = cv2.equalizeHist(img_original)
# Calcular o histograma da imagem equalizada
hist_equalizada = cv2.calcHist([img_equalizada], [0], None, [256], [0, 256])
# Exibir as imagens e seus histogramas
plt.figure(figsize=(12, 6))
plt.subplot(2, 2, 1)
plt.imshow(img_original, cmap='gray')
plt.title('Imagem Original')
plt.axis('off')
plt.subplot(2, 2, 2)
plt.plot(hist_original, color='black')
plt.title('Histograma - Imagem Original')
plt.xlabel('Intensidade do Pixel')
plt.ylabel('Frequência')
plt.subplot(2, 2, 3)
plt.imshow(img_equalizada, cmap='gray')
plt.title('Imagem Equalizada')
plt.axis('off')
plt.subplot(2, 2, 4)
plt.plot(hist_equalizada, color='black')
plt.title('Histograma - Imagem Equalizada')
plt.xlabel('Intensidade do Pixel')
plt.ylabel('Frequência')
plt.tight_layout()
plt.show()
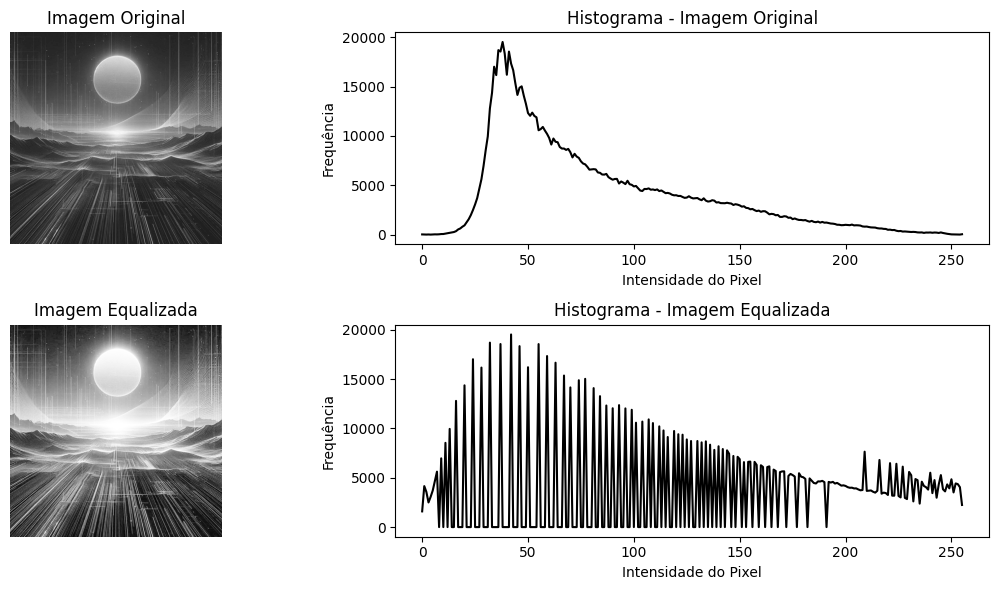
Na imagem original, o histograma pode estar concentrado em uma faixa estreita de valores, indicando baixo contraste (áreas escuras ou claras demais).
Na imagem equalizada, o histograma se torna mais uniforme, mostrando uma distribuição mais ampla das intensidades de pixel. Esse novo mapeamento de intensidades proporciona um contraste mais equilibrado, tornando os detalhes em áreas escuras e claras mais visíveis.
Equalização Adaptativa com CLAHE
Para imagens coloridas ou em situações onde a equalização global pode introduzir ruído, o método CLAHE (Contrast Limited Adaptive Histogram Equalization) é mais indicado. Em vez de aplicar a equalização a toda a imagem, o CLAHE divide a imagem em pequenas regiões (blocos) e equaliza cada bloco de forma independente, limitando o aumento de contraste em áreas uniformes para evitar artefatos.
O CLAHE também pode ser aplicado em uma imagem colorida, mas exige um ajuste. Como o CLAHE é projetado para imagens em escala de cinza, aplicá-lo diretamente a cada canal de cor (B, G, R) pode distorcer as cores. A abordagem ideal é aplicar o CLAHE apenas no canal de luminância, separando-o dos canais de cor. Para isso, convertemos a imagem para um espaço de cor como o LAB ou YUV, onde a luminância está separada das cores.
Exemplo de Código com CLAHE para Imagem Colorida
import cv2
import matplotlib.pyplot as plt
# Carregar a imagem colorida
img_colorida = cv2.imread('sun.jpeg')
# Converter a imagem de BGR para LAB
img_lab = cv2.cvtColor(img_colorida, cv2.COLOR_BGR2LAB)
# Separar os canais LAB
l, a, b = cv2.split(img_lab)
# Aplicar CLAHE no canal L (luminância)
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
l_equalizado = clahe.apply(l)
# Combinar os canais novamente
img_lab_equalizada = cv2.merge((l_equalizado, a, b))
# Converter a imagem de volta para BGR
img_colorida_equalizada = cv2.cvtColor(img_lab_equalizada, cv2.COLOR_LAB2BGR)
# Exibir a imagem original e a imagem com CLAHE
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(cv2.cvtColor(img_colorida, cv2.COLOR_BGR2RGB))
plt.title('Imagem Original')
plt.axis('off')
plt.subplot(1, 2, 2)
plt.imshow(cv2.cvtColor(img_colorida_equalizada, cv2.COLOR_BGR2RGB))
plt.title('Imagem com CLAHE')
plt.axis('off')
plt.tight_layout()
plt.show()

A equalização adaptativa com CLAHE preserva melhor os detalhes e não distorce as cores. No espaço LAB, a equalização do contraste ocorre apenas no canal de luminância (L), mantendo os canais de cor (A e B) inalterados.
O resultado é uma imagem colorida com contraste aprimorado e preservação das cores naturais, evitando o ruído ou saturação excessiva em áreas de cor uniforme.
A equalização de histograma, particularmente com CLAHE, é uma técnica poderosa para melhorar o contraste em imagens com baixa variação de intensidade, tornando-as mais claras e detalhadas sem introduzir ruído excessivo.
Exercício Prático: Equalização de Histograma#
Neste exercício, você irá explorar a equalização de histograma para melhorar o contraste de duas imagens usando Python e OpenCV. Siga as instruções abaixo:
Buscar Imagens
Escolha e baixe duas imagens da internet:
Uma imagem em preto e branco ou com tons de cinza, como uma foto de um objeto, paisagem ou animal com áreas de sombra ou luminosidade acentuadas.
Uma imagem colorida, preferencialmente de uma cena onde haja contrastes de luz e sombras, como uma paisagem urbana noturna ou um ambiente com baixa iluminação.
Aplicar Equalização de Histograma
Imagem em Escala de Cinza:
Carregue a imagem em escala de cinza usando
cv2.imreadcom o parâmetrocv2.IMREAD_GRAYSCALE.Aplique a equalização de histograma com a função
cv2.equalizeHist.Gere e exiba o histograma da imagem original e da imagem equalizada para visualizar a diferença na distribuição de intensidade dos pixels.
Imagem Colorida (CLAHE):
Carregue a imagem colorida.
Converta a imagem para o espaço de cor LAB para aplicar o CLAHE apenas no canal de luminância (L).
Aplique o CLAHE no canal L e, em seguida, reconstrua a imagem final a partir dos canais L, A e B.
Exiba a imagem original e a imagem com equalização CLAHE para comparar.
Análise dos Resultados
Observe a diferença nos histogramas antes e depois da equalização para a imagem em escala de cinza.
Na imagem colorida, verifique como o CLAHE preserva as cores naturais enquanto aumenta o contraste.
Transformações Geométricas com OpenCV#
Redimensionamento de Imagens#
Com o OpenCV, o redimensionamento de imagens pode ser realizado usando a função cv2.resize.
import cv2
import matplotlib.pyplot as plt
# Carregar a imagem
imagem = cv2.imread('exemplo.jpg')
imagem_rgb = cv2.cvtColor(imagem, cv2.COLOR_BGR2RGB) # Converter de BGR para RGB para exibir no Matplotlib
# Redimensionar a imagem
nova_imagem = cv2.resize(imagem, (200, 200)) # Redimensionar para 200x200 pixels
# Exibir
nova_imagem_rgb = cv2.cvtColor(nova_imagem, cv2.COLOR_BGR2RGB) # Converter de BGR para RGB
plt.subplot(1, 2, 1)
plt.title("Original")
plt.imshow(imagem_rgb)
plt.subplot(1, 2, 2)
plt.title("Redimensionada")
plt.imshow(nova_imagem_rgb)
plt.show()
Rotação de Imagens#
A rotação básica de uma imagem pode ser feita com cv2.getRotationMatrix2D e cv2.warpAffine.
# Rotação de 45 graus com o centro da imagem como ponto de rotação
altura, largura = imagem.shape[:2]
centro = (largura // 2, altura // 2)
# Criar a matriz de rotação
matriz_rotacao = cv2.getRotationMatrix2D(centro, 45, 1.0)
# Aplicar a rotação
imagem_rotacionada = cv2.warpAffine(imagem, matriz_rotacao, (largura, altura))
# Exibir
imagem_rotacionada_rgb = cv2.cvtColor(imagem_rotacionada, cv2.COLOR_BGR2RGB)
plt.subplot(1, 2, 1)
plt.title("Original")
plt.imshow(imagem_rgb)
plt.subplot(1, 2, 2)
plt.title("Rotacionada (45°)")
plt.imshow(imagem_rotacionada_rgb)
plt.show()
Espelhamento de Imagens#
Usando cv2.flip, você pode criar reflexos horizontais, verticais ou ambos.
# Espelhar horizontalmente
imagem_espelhada = cv2.flip(imagem, 1)
# Exibir
imagem_espelhada_rgb = cv2.cvtColor(imagem_espelhada, cv2.COLOR_BGR2RGB)
plt.subplot(1, 2, 1)
plt.title("Original")
plt.imshow(imagem_rgb)
plt.subplot(1, 2, 2)
plt.title("Espelhada Horizontalmente")
plt.imshow(imagem_espelhada_rgb)
plt.show()
Translação de Imagens#
A translação é feita definindo uma matriz de translação e aplicando-a com cv2.warpAffine.
# Criar a matriz de translação: move 50 pixels para a direita e 30 pixels para baixo
matriz_translacao = np.float32([[1, 0, 50], [0, 1, 30]])
# Aplicar a translação
imagem_transladada = cv2.warpAffine(imagem, matriz_translacao, (largura, altura))
# Exibir
imagem_transladada_rgb = cv2.cvtColor(imagem_transladada, cv2.COLOR_BGR2RGB)
plt.subplot(1, 2, 1)
plt.title("Original")
plt.imshow(imagem_rgb)
plt.subplot(1, 2, 2)
plt.title("Transladada")
plt.imshow(imagem_transladada_rgb)
plt.show()
Cropping de Imagens#
Cortar partes específicas da imagem pode ser feito acessando fatias do array de pixels.
# Recortar uma região específica da imagem
corte = imagem[100:300, 200:400] # [altura_inicial:altura_final, largura_inicial:largura_final]
# Exibir
corte_rgb = cv2.cvtColor(corte, cv2.COLOR_BGR2RGB)
plt.subplot(1, 2, 1)
plt.title("Original")
plt.imshow(imagem_rgb)
plt.subplot(1, 2, 2)
plt.title("Corte")
plt.imshow(corte_rgb)
plt.show()
Combinação: Translação + Rotação#
Podemos combinar translação e rotação em uma única matriz de transformação.
# Combinar rotação e translação
matriz_combinada = cv2.getRotationMatrix2D(centro, 30, 1.0) # Rotação de 30 graus
matriz_combinada[0, 2] += 50 # Translação no eixo X
matriz_combinada[1, 2] += 30 # Translação no eixo Y
# Aplicar a transformação
imagem_combinada = cv2.warpAffine(imagem, matriz_combinada, (largura, altura))
# Exibir
imagem_combinada_rgb = cv2.cvtColor(imagem_combinada, cv2.COLOR_BGR2RGB)
plt.subplot(1, 2, 1)
plt.title("Original")
plt.imshow(imagem_rgb)
plt.subplot(1, 2, 2)
plt.title("Combinada (Rotação + Translação)")
plt.imshow(imagem_combinada_rgb)
plt.show()
Convolução de Imagens#
A convolução é uma operação matemática fundamental no processamento de imagens, utilizada para diversas aplicações, como suavização, detecção de bordas e remoção de ruídos. Essencialmente, a convolução combina duas funções: a imagem de entrada e um kernel ou filtro. O resultado dessa operação é uma nova imagem, que pode destacar características específicas ou transformar a imagem original de acordo com o filtro aplicado.
A Matemática por Trás da Convolução
Matematicamente, a convolução de duas funções contínuas \( f(x) \) e \( g(x) \) é denotada como \( f * g \) e definida como a integral do produto de \( f(x) \) com uma versão invertida e deslocada de \( g(x) \):
No processamento de imagens digitais, no entanto, trabalhamos com valores discretos. A convolução discreta é representada por um somatório que opera sobre a matriz de pixels da imagem (\( f \)) e os valores do kernel (\( g \)):
Aqui:
\( C(i, j) \): é o valor do pixel na posição \((i, j)\) da imagem resultante.
\( f(i, j) \): é o valor do pixel na posição \((i, j)\) da imagem original.
\( g(m, n) \): é o valor do elemento na posição \((m, n)\) do kernel.
\( m, n \): percorrem os índices do kernel.
O kernel, uma matriz menor, desliza sobre a imagem de entrada, e em cada posição o somatório calcula uma combinação ponderada dos valores dos pixels vizinhos, definidos pelos coeficientes do kernel.
A Importância dos Kernels
Os kernels são o coração da convolução. Eles são matrizes pequenas, normalmente de tamanho ímpar, cujos valores determinam o efeito da operação de convolução na imagem. Diferentes kernels podem ser projetados para extrair características específicas de uma imagem, como bordas, detalhes ou até mesmo ruídos.
Detecção de Bordas com Kernels
Dois kernels clássicos para detecção de bordas são projetados para enfatizar mudanças na intensidade de pixel em direções específicas: vertical ou horizontal.
Kernel para Detecção de Bordas Verticais: Este kernel realça mudanças na intensidade horizontal (direção esquerda para direita) e é eficaz na detecção de bordas verticais:
Os valores negativos e positivos são atribuídos às colunas adjacentes, destacando bordas onde há uma transição de intensidade significativa entre regiões à esquerda e à direita.
Kernel para Detecção de Bordas Horizontais: Este kernel, uma versão transposta do anterior, realça mudanças na intensidade vertical (direção de cima para baixo) e é eficaz na detecção de bordas horizontais:
Os valores negativos e positivos são atribuídos às linhas adjacentes, destacando bordas onde há uma transição de intensidade significativa entre regiões superiores e inferiores.
Entendendo a Convolução: Suavização de Imagem
Este exemplo demonstra como a convolução, uma operação fundamental em processamento de imagens, pode ser utilizada para suavizar uma imagem. Utilizaremos um filtro de média 3x3 para este fim.
Representação da Imagem
Imagine uma imagem em tons de cinza representada por uma matriz 5x5, onde cada elemento corresponde a um pixel e seu valor numérico representa o brilho:
Imagem (Matriz A):
10 20 30 40 50
20 30 40 50 60
30 40 50 60 70
40 50 60 70 80
50 60 70 80 90
O Filtro de Média
Para suavizar a imagem, aplicaremos um filtro de média 3x3, também conhecido como kernel:
Kernel (Matriz B):
1/9 1/9 1/9
1/9 1/9 1/9
1/9 1/9 1/9
Este kernel calcula a média dos valores dos pixels vizinhos, incluindo o pixel central.
Passo a Passo da Convolução
Posicionamento do Kernel: O kernel é posicionado sobre a imagem, iniciando no canto superior esquerdo. Ele sobrepõe uma área de 3x3 pixels.
1/9 1/9 1/9 10 20 30 | 40 50
1/9 1/9 1/9 * 20 30 40 | 50 60
1/9 1/9 1/9 30 40 50 | 60 70
---------
40 50 60 70 80
50 60 70 80 90
Multiplicação e Soma: Cada elemento do kernel é multiplicado pelo valor do pixel correspondente na imagem. Os resultados são somados.
(1/9 * 10) + (1/9 * 20) + (1/9 * 30) + ... + (1/9 * 50)= 30
Atribuição do Valor: O resultado da soma (30, neste caso) é atribuído ao pixel central da área de convolução na nova matriz (a imagem resultante).
Repetição: O kernel é deslocado um pixel para a direita e os passos 1 a 3 são repetidos até que o kernel percorra toda a imagem.
Após a convolução completa usando mode='valid', a imagem resultante C será:
30 35 40
35 40 45
40 45 50
Observações:
Bordas: Note que a imagem resultante é menor que a original. Isso ocorre porque o kernel não pode ser aplicado nas bordas sem extrapolar os limites da imagem. O exemplo apresentado utiliza
mode='valid', o que significa que a convolução é realizada apenas onde o kernel se sobrepõe completamente à imagem original, resultando em uma imagem menor.mode='same'e Padding: Uma alternativa seria utilizarmode='same', que adiciona zeros ao redor da imagem original (padding) para que a imagem resultante tenha o mesmo tamanho da original. Essa técnica de padding permite que o kernel seja aplicado em todas as partes da imagem, incluindo as bordas.
Visualizando a Convolução
O código a seguir demonstra a convolução utilizando Python:
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import convolve2d
# Define a matriz da imagem.
A = np.array([[10, 20, 30, 40, 50],
[20, 30, 40, 50, 60],
[30, 40, 50, 60, 70],
[40, 50, 60, 70, 80],
[50, 60, 70, 80, 90]])
# Define o kernel de média
B = np.array([[1/9, 1/9, 1/9],
[1/9, 1/9, 1/9],
[1/9, 1/9, 1/9]])
# Realiza a convolução usando a função convolve do scipy
C = convolve2d(A, B, mode='valid')
# Exibe as matrizes como imagens
plt.figure(figsize=(10, 4))
plt.subplot(1, 3, 1)
plt.imshow(A, cmap='gray')
plt.title(f'Imagem Original ({A.shape[0]}x{A.shape[1]})')
plt.axis('off')
plt.subplot(1, 3, 2)
plt.imshow(B, cmap='gray')
plt.title(f'Kernel ({B.shape[0]}x{B.shape[1]})')
plt.axis('off')
plt.subplot(1, 3, 3)
plt.imshow(C, cmap='gray')
plt.title(f'Imagem Convolucionada ({C.shape[0]}x{C.shape[1]})')
plt.axis('off')
plt.tight_layout()
plt.show()
Este código utiliza a função convolve2d da biblioteca scipy para realizar a convolução da matriz da imagem com o kernel de média. Ele exibe a imagem original, o kernel e a imagem resultante da convolução.

Exemplos Práticos
Agora, vejamos um exemplo mais prático a partir de uma imagem real de uma ponte em escala de cinza. Seguindo o código a seguir, você pode substituir por uma imagem de sua preferência.
{kind=link}
import cv2
import numpy as np
from matplotlib import pyplot as plt
# Carrega a imagem em escala de cinza
img = cv2.imread('bridge.jpeg', cv2.IMREAD_GRAYSCALE)
# Define a porcentagem de ruído sal e pimenta
noise_percentage = 0.4
# Cria uma cópia da imagem
noisy_img = np.copy(img)
# Gera ruído sal e pimenta
for i in range(img.shape[0]):
for j in range(img.shape[1]):
random_number = np.random.rand()
if random_number < noise_percentage:
noisy_img[i, j] = 255 if random_number < noise_percentage / 2 else 0
# Remove o ruído com um filtro mediana
filtered_img = cv2.medianBlur(noisy_img, 5)
# Configura os subplots
plt.figure(figsize=(15, 5))
# Subplot 1: Imagem original
plt.subplot(1, 3, 1)
plt.imshow(img, cmap='gray')
plt.title('Imagem Original')
plt.axis('off')
# Subplot 2: Imagem com ruído
plt.subplot(1, 3, 2)
plt.imshow(noisy_img, cmap='gray')
plt.title('Imagem com Ruído')
plt.axis('off')
# Subplot 3: Imagem filtrada
plt.subplot(1, 3, 3)
plt.imshow(filtered_img, cmap='gray')
plt.title('Imagem Filtrada')
plt.axis('off')
# Ajusta o layout para evitar sobreposição
plt.tight_layout()
# Mostra o resultado
plt.show()

Neste exemplo, começamos carregando uma imagem em escala de cinza. Em seguida, adicionamos ruído gaussiano à imagem, simulando pixels aleatórios de “sal e pimenta”. Depois, aplicamos um filtro mediano para remover o ruído. O filtro mediano substitui o valor de cada pixel pela mediana dos valores dos pixels em sua vizinhança, reduzindo efetivamente o ruído enquanto preserva os detalhes da imagem.
Neste exemplo, usaremos um kernel Sobel para detectar bordas verticais em uma imagem.
import cv2
import numpy as np
from matplotlib import pyplot as plt
# Carrega a imagem em escala de cinza
img = cv2.imread('bridge.jpeg', cv2.IMREAD_GRAYSCALE)
# Define o kernel Sobel para detecção de bordas verticais
kernel = np.array([[-1, 0, 1],
[-2, 0, 2],
[-1, 0, 1]])
# Aplica a convolução da imagem com o kernel
conv_img = cv2.filter2D(img, -1, kernel)
# Cria uma figura com duas subplots lado a lado
plt.figure(figsize=(10, 5))
# Mostra a imagem original
plt.subplot(1, 2, 1)
plt.imshow(img, cmap='gray')
plt.title('Imagem Original')
plt.axis('off') # Remove os eixos
# Mostra a imagem convoluída
plt.subplot(1, 2, 2)
plt.imshow(conv_img, cmap='gray')
plt.title('Imagem Convoluída (Detecção de Bordas)')
plt.axis('off') # Remove os eixos
# Ajusta o layout para evitar sobreposição
plt.tight_layout()
# Mostra a figura
plt.show()
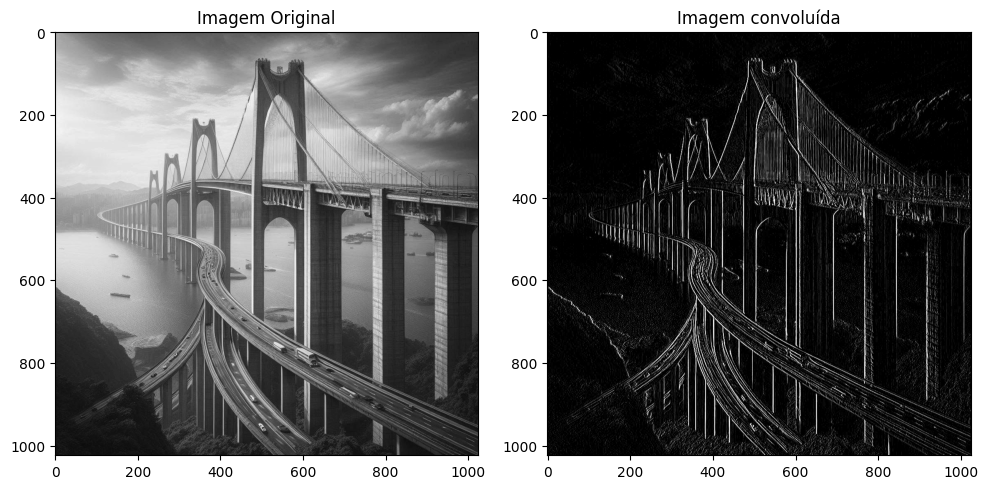
No código acima, primeiro carregamos a imagem em escala de cinza. Em seguida, aplicamos a convolução usando o kernel Sobel, que é projetado para detectar bordas verticais. A imagem resultante destaca as bordas verticais na imagem original, tornando-as mais visíveis.
A convolução é uma ferramenta poderosa no processamento de imagens, permitindo extrair e destacar características específicas. Esses exemplos ilustram apenas uma pequena parte de suas aplicações, e a compreensão e domínio da convolução são cruciais para qualquer pessoa interessada em visão computacional e IA.
Exercício: Exploração de Filtros Convolucionais#
Neste exercício, você deverá aplicar diferentes filtros convolucionais para explorar como cada um deles realça ou transforma características específicas de uma imagem. As tarefas incluem:
Separação de Bordas: Detectar bordas verticais, horizontais e diagonais em uma imagem.
Realce de Bordas Arredondadas: Aplicar filtros para destacar regiões de bordas curvas ou transições suaves.
Borramento Progressivo: Aplicar um filtro de suavização repetidamente, até que a imagem fique altamente desfocada.
Instruções
Carregue uma imagem (em tons de cinza) de sua escolha ou use a imagem
bridge.jpegfornecida no exemplo.Aplique os filtros convolucionais abaixo:
Bordas Verticais: Use o kernel Sobel vertical.
Bordas Horizontais: Use o kernel Sobel horizontal.
Bordas Diagonais: Use um kernel que realça transições diagonais.
Bordas Arredondadas: Combine um filtro Laplaciano com um filtro Gaussiano para identificar transições suaves e curvas.
Borramento Progressivo: Aplique um filtro Gaussiano repetidamente e salve as imagens resultantes após 10, 100 e 1000 iterações.
Exemplos de Kernels
Os seguintes kernels podem ser utilizados para as operações:
Kernel Sobel Vertical:
(1)#\[\begin{bmatrix} -1 & 0 & 1 \\ -2 & 0 & 2 \\ -1 & 0 & 1 \end{bmatrix}\]Kernel Sobel Horizontal:
(2)#\[\begin{bmatrix} -1 & -2 & -1 \\ 0 & 0 & 0 \\ 1 & 2 & 1 \end{bmatrix}\]Kernel Diagonal Principal:
(3)#\[\begin{bmatrix} 2 & -1 & -1 \\ -1 & 2 & -1 \\ -1 & -1 & 2 \end{bmatrix}\]Kernel Diagonal Secundária:
(4)#\[\begin{bmatrix} -1 & -1 & 2 \\ -1 & 2 & -1 \\ 2 & -1 & -1 \end{bmatrix}\]Kernel Laplaciano para Bordas Arredondadas:
(5)#\[\begin{bmatrix} 0 & -1 & 0 \\ -1 & 4 & -1 \\ 0 & -1 & 0 \end{bmatrix}\]Kernel de Suavização (Média 3x3):
(6)#\[\begin{bmatrix} 1/9 & 1/9 & 1/9 \\ 1/9 & 1/9 & 1/9 \\ 1/9 & 1/9 & 1/9 \end{bmatrix}\]
Exemplo de resultado:

Redes Neurais Convolucionais#
O ano de 2012 marcou um ponto de virada no campo da visão computacional com a publicação do revolucionário artigo “ImageNet Classification with Deep Convolutional Neural Networks”. Nele, Alex Krizhevsky, Ilya Sutskever e Geoffrey Hinton apresentaram ao mundo a arquitetura AlexNet, uma CNN profunda que superou significativamente os métodos tradicionais na tarefa de classificação de imagens em larga escala. Essa conquista, utilizando o conjunto de dados ImageNet, impulsionou o interesse e a pesquisa em CNNs, consolidando-as como o estado da arte em diversas tarefas de visão computacional.

As Redes Neurais Convolucionais (CNNs) emergiram como uma força motriz por trás dessa revolução, impulsionando avanços extraordinários em áreas como reconhecimento de imagens, segmentação e muito mais. Inspiradas na estrutura e função do sistema visual humano, essas redes neurais artificiais demonstram uma capacidade notável de interpretar e extrair significado de dados visuais.
Aplicações Transformadoras em Visão Computacional#
A versatilidade e o poder das CNNs impulsionaram sua adoção em uma ampla gama de aplicações de visão computacional, incluindo:
Reconhecimento de Objetos: CNNs demonstram uma precisão excepcional na identificação e classificação de objetos em imagens, mesmo em cenários complexos com múltiplos objetos e fundos confusos.
Detecção de Objetos: Além do reconhecimento, as CNNs podem localizar e delinear objetos em uma imagem, fornecendo informações valiosas sobre suas posições e tamanhos.
Segmentação de Imagens: As CNNs podem segmentar imagens com precisão em diferentes regiões semânticas, rotulando cada pixel com a classe correspondente, como céu, edifícios, carros e pessoas.
Reconhecimento Facial: CNNs são amplamente utilizadas para identificar e reconhecer rostos em imagens e vídeos, com aplicações em segurança, autenticação e mídia social.
Análise de Imagens Médicas: CNNs auxiliam médicos no diagnóstico de doenças, identificando padrões em radiografias, tomografias e outras imagens médicas.
Arquitetura em Camadas: Da Percepção à Abstração#
Uma CNN típica é composta por uma série de camadas interconectadas, cada uma desempenhando um papel crucial na extração de características e no processo de aprendizagem. Essa estrutura em camadas permite que a rede aprenda representações hierárquicas de dados visuais, progredindo de padrões simples a características altamente complexas.
Camadas Convolucionais: Encontrando os Padrões
No cerne de uma CNN residem as camadas convolucionais, responsáveis por identificar e extrair características visuais significativas de uma imagem de entrada. Essas camadas empregam filtros especializados, conhecidos como kernels, que deslizam pela imagem, realizando operações matemáticas para detectar padrões como bordas, cantos e texturas. À medida que a informação se propaga pelas camadas convolucionais, a rede desenvolve a capacidade de reconhecer padrões cada vez mais abstratos e complexos.
A seguir, uma ilustração do que seria uma CNN.
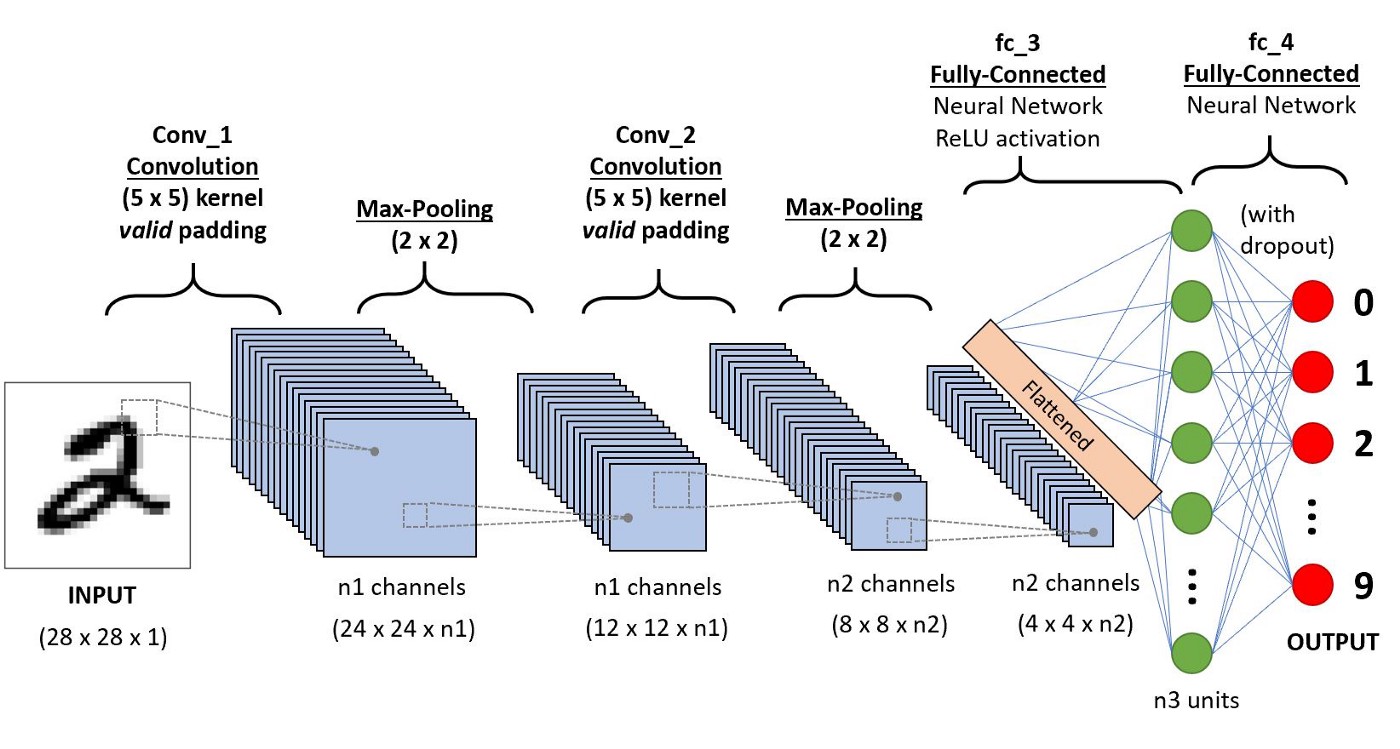
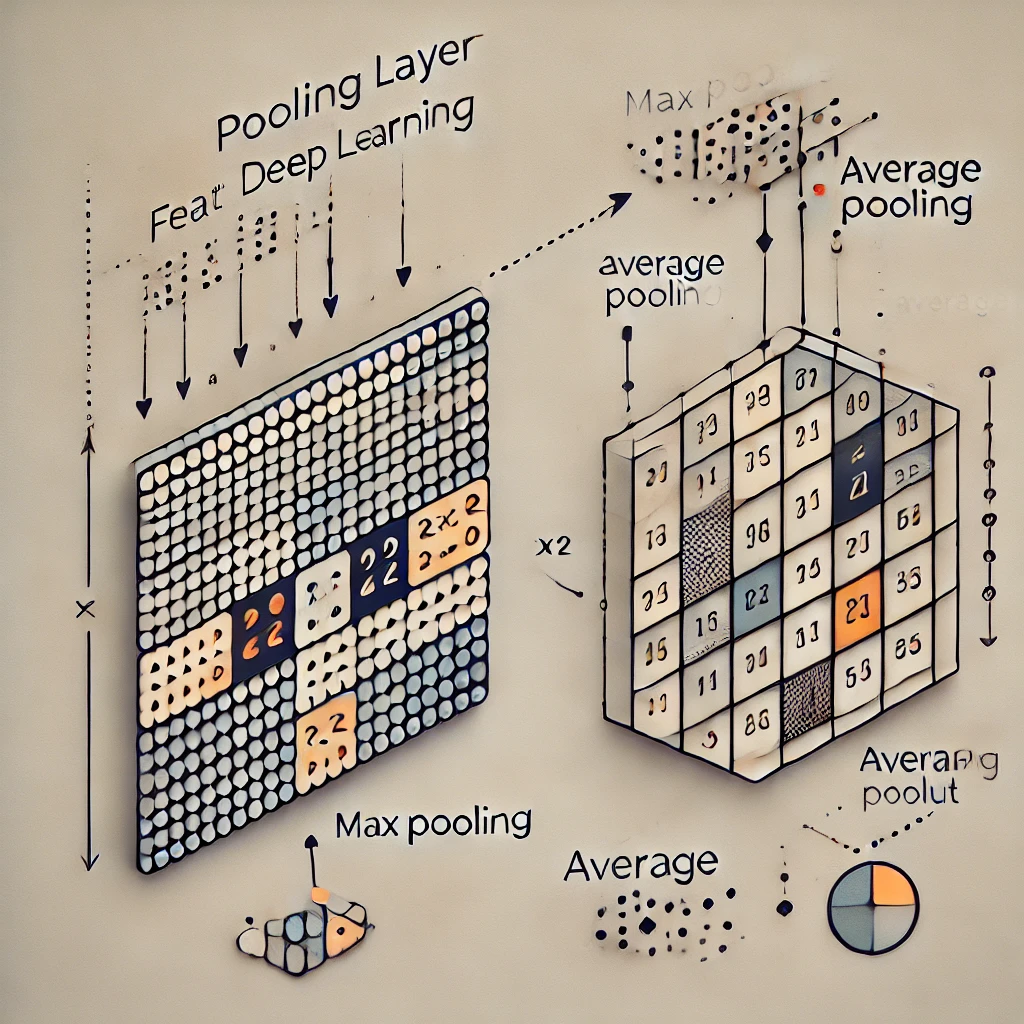
Camadas de Pooling: Simplificando a Informação Visual
Após as camadas convolucionais, as camadas de pooling entram em ação, reduzindo a dimensionalidade dos mapas de características gerados. Essas camadas agregam informações espaciais, preservando características importantes enquanto descartam variações mínimas. Esse processo de downsampling não só torna a representação da imagem mais compacta, mas também aumenta a robustez da rede a pequenas variações na posição e na escala do objeto. Existem diferentes tipos de pooling, sendo os mais comuns o Max Pooling e o Average Pooling.
Exemplo: Figura Ilustrativa
Max Pooling: O Max Pooling extrai o valor máximo dentro de uma janela definida pelo kernel, como ilustrado na figura abaixo. Este método é eficaz para destacar as características mais proeminentes.
Kernel 2x2:
1 3 -> Max Pooling -> 3
2 3
Exemplo: Figura Ilustrativa
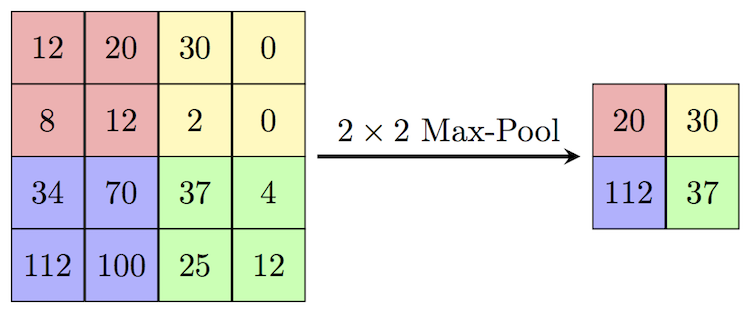
Average Pooling: O Average Pooling calcula a média dos valores dentro da janela do kernel. Este método suaviza as características e reduz a sensibilidade a pequenas variações.
Kernel 2x2:
1 3 -> Average Pooling -> 2
2 3
Flattening: Transformando Matrizes em Vetores
Antes que as características extraídas pelas camadas convolucionais e de pooling sejam passadas para a camada totalmente conectada, elas precisam ser “achatadas” em um vetor unidimensional. Esse processo, chamado de flattening, organiza os valores dos mapas de características em uma única coluna, como no exemplo a seguir:
Matriz 2x2: Vetor Coluna:
1 2 1
3 4 2
3
4
Camadas Totalmente Conectadas: Integrando e Classificando
As camadas totalmente conectadas, também conhecidas como camadas densas, representam o estágio final no pipeline de uma CNN. Essas camadas recebem o vetor de características achatado e o utilizam para realizar a tarefa de classificação ou regressão. Em uma camada totalmente conectada, cada neurônio está conectado a todos os neurônios da camada anterior. Essa conexão completa permite que a rede aprenda relações complexas entre as características extraídas pelas camadas anteriores e faça previsões finais.
Classificador de Roupas com Camadas Convolucionais e de Pooling#
Após estudarmos o dataset MNIST, agora é o momento de avançar para uma aplicação prática mais robusta. Vamos explorar o impacto das redes convolucionais na classificação de imagens, utilizando o dataset Fashion MNIST, que contém imagens de roupas em 10 categorias. Por meio do uso de camadas convolucionais e de pooling, é possível melhorar significativamente a acurácia do modelo em comparação a arquiteturas mais simples.
Estrutura do Modelo com CNNs
O modelo é composto por uma série de camadas projetadas para capturar padrões locais e abstrações visuais de maneira hierárquica:
Camadas Convolucionais: Extraem características importantes das imagens, como bordas e texturas.
Camadas de Pooling: Reduzem a dimensionalidade, mantendo as características mais relevantes.
Camadas Densas: Integram as informações extraídas para realizar a classificação final.
A arquitetura típica pode incluir múltiplas camadas convolucionais e de pooling, seguidas por camadas densas e funções de ativação apropriadas. Um exemplo prático dessa estrutura é:
model = keras.Sequential([
keras.layers.Conv2D(filters=32, kernel_size=(3, 3), padding='same', input_shape=(28, 28, 1), activation='relu'),
keras.layers.MaxPooling2D(pool_size=(2, 2)),
keras.layers.Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'),
keras.layers.MaxPooling2D(pool_size=(2, 2)),
keras.layers.Flatten(),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dropout(0.2),
keras.layers.Dense(10, activation='softmax')
])
Processo de Construção e Treinamento
Pré-processamento dos Dados:
O dataset Fashion MNIST é carregado e dividido em conjuntos de treino e teste.
As imagens são normalizadas para o intervalo de 0 a 1, garantindo que os valores dos pixels estejam adequados para o treinamento de redes neurais.
Compilação do Modelo:
O modelo é configurado com o otimizador Adam, a função de perda sparse_categorical_crossentropy, e a métrica de acurácia para monitoramento.
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
Treinamento do Modelo:
O modelo é treinado por 10 épocas, utilizando 20% dos dados de treinamento para validação.
Durante o treinamento, são gerados logs que registram a evolução da acurácia e da perda.
history = model.fit(train_images[..., np.newaxis], train_labels, epochs=10, validation_split=0.2)
Análise dos Resultados
Interpretação dos Resultados
Com o uso de redes convolucionais, esperamos observar:
Melhoria na Acurácia: O modelo deve superar os resultados obtidos anteriormente com redes densas simples, especialmente na validação.
Redução de Overfitting: Camadas como Dropout e Pooling ajudam a generalizar melhor os dados, reduzindo a discrepância entre as acurácias de treinamento e validação.
Se o desempenho não atingir o esperado, considerem-se ajustes, como o aumento de filtros nas camadas convolucionais, a introdução de mais camadas ou o uso de técnicas de regularização.
Classificador de Roupas: Comparação Entre Modelos com e sem Camadas Convolucionais#
Após explorarmos o dataset MNIST, avançamos para uma aplicação prática mais desafiadora usando o dataset Fashion MNIST, que contém imagens de roupas em 10 categorias. Nesta etapa, analisamos o impacto das redes convolucionais (CNNs) em comparação a arquiteturas mais simples baseadas em camadas densas (Fully Connected Networks, ou FCNs).
As CNNs introduzem camadas convolucionais e de pooling para capturar padrões visuais hierárquicos nas imagens. Ao contrário das redes densas, que tratam todos os pixels como independentes, as CNNs exploram a proximidade espacial entre os pixels para extrair características locais, como bordas, texturas e formas. Isso reduz drasticamente o número de parâmetros e melhora a capacidade do modelo de generalizar para novos dados.
Arquitetura 1: Modelo Simples com Camadas Densas#
O primeiro modelo é baseado apenas em camadas densas e funciona como um baseline. Todas as imagens de 28x28 pixels são achatadas em vetores unidimensionais antes de entrarem na rede.
model_fcn = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dropout(0.2),
keras.layers.Dense(10, activation='softmax')
])
model_fcn.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
history_fcn = model_fcn.fit(train_images, train_labels, epochs=10, validation_split=0.2)
Pontos Fortes e Fracos:
Vantagens: Simples e rápido para treinar.
Desvantagens: A performance é limitada, pois não aproveita as relações espaciais entre os pixels. Além disso, a rede é propensa ao overfitting devido ao alto número de parâmetros.
Arquitetura 2: Modelo com Camadas Convolucionais e de Pooling#
O segundo modelo utiliza camadas convolucionais para explorar padrões locais nas imagens e camadas de pooling para reduzir a dimensionalidade, preservando as características mais importantes.
model_cnn = keras.Sequential([
keras.layers.Conv2D(filters=32, kernel_size=(3, 3), padding='same', input_shape=(28, 28, 1), activation='relu'),
keras.layers.MaxPooling2D(pool_size=(2, 2)),
keras.layers.Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'),
keras.layers.MaxPooling2D(pool_size=(2, 2)),
keras.layers.Flatten(),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dropout(0.2),
keras.layers.Dense(10, activation='softmax')
])
model_cnn.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
history_cnn = model_cnn.fit(train_images[..., np.newaxis], train_labels, epochs=10, validation_split=0.2)
Pontos Fortes:
Captura relações espaciais locais.
Reduz o risco de overfitting com menos parâmetros em comparação a FCNs.
Geralmente, apresenta maior acurácia tanto no treinamento quanto na validação.
Comparação de Resultados#
Após treinar ambos os modelos, podemos comparar suas performances:
Modelo |
Acurácia de Treino |
Acurácia de Validação |
Número de Parâmetros |
|---|---|---|---|
Apenas Camadas Densas |
~85% |
~82% |
Alto |
Com Camadas Convolucionais |
~92% |
~90% |
Baixo |
Análise dos Resultados:
Melhoria na Acurácia: O modelo CNN supera o modelo baseado apenas em camadas densas, especialmente na validação, devido à sua capacidade de extrair características hierárquicas.
Menor Overfitting: As camadas de pooling e a redução de parâmetros ajudam o modelo a generalizar melhor para dados não vistos.
Eficiência de Parâmetros: As CNNs, mesmo com várias camadas convolucionais, utilizam significativamente menos parâmetros em comparação a redes densas de tamanho similar.
Obs: Os resultados podem variar, devido a inicialização aleatória dos pesos da rede.
A introdução de camadas convolucionais e de pooling transforma a maneira como os modelos aprendem padrões em imagens. Enquanto redes densas tratam todos os pixels como independentes, as CNNs exploram relações espaciais, resultando em melhorias substanciais na performance e eficiência. Esse avanço destaca a importância de arquiteturas mais especializadas para tarefas complexas de visão computacional.
Aqui está a implementação completa dos modelos com suas respectivas arquiteturas e processos de treinamento.
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
# Carregar o dataset Fashion MNIST
(train_images, train_labels), (test_images, test_labels) = keras.datasets.fashion_mnist.load_data()
# Normalizar os dados
train_images = train_images / 255.0
test_images = test_images / 255.0
# Labels das categorias
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
# Modelo 1: Apenas camadas densas
model_fcn = keras.Sequential([
layers.Flatten(input_shape=(28, 28)),
layers.Dense(128, activation='relu'),
layers.Dropout(0.2),
layers.Dense(10, activation='softmax')
])
model_fcn.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
print("Treinando o modelo com apenas camadas densas...")
history_fcn = model_fcn.fit(train_images, train_labels, epochs=10, validation_split=0.2)
# Adicionar um canal extra apenas para o modelo CNN
train_images_cnn = tf.expand_dims(train_images, axis=-1)
test_images_cnn = tf.expand_dims(test_images, axis=-1)
# Modelo 2: Com camadas convolucionais e pooling
model_cnn = keras.Sequential([
layers.Conv2D(filters=32, kernel_size=(3, 3), padding='same', activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dropout(0.2),
layers.Dense(10, activation='softmax')
])
model_cnn.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
print("\nTreinando o modelo com camadas convolucionais...")
history_cnn = model_cnn.fit(train_images_cnn, train_labels, epochs=10, validation_split=0.2)
# Avaliação dos modelos
print("\nAvaliando o modelo com apenas camadas densas...")
test_loss_fcn, test_acc_fcn = model_fcn.evaluate(test_images, test_labels)
print(f"Teste Acurácia (Dense): {test_acc_fcn:.4f}")
print("\nAvaliando o modelo com camadas convolucionais...")
test_loss_cnn, test_acc_cnn = model_cnn.evaluate(test_images_cnn, test_labels)
print(f"Teste Acurácia (CNN): {test_acc_cnn:.4f}")
# Predições
pred_fcn = np.argmax(model_fcn.predict(test_images), axis=1)
pred_cnn = np.argmax(model_cnn.predict(test_images_cnn), axis=1)
# Matrizes de confusão
conf_matrix_fcn = confusion_matrix(test_labels, pred_fcn)
conf_matrix_cnn = confusion_matrix(test_labels, pred_cnn)
# Exibir matrizes de confusão lado a lado
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# Matriz para o modelo Dense
disp_fcn = ConfusionMatrixDisplay(confusion_matrix=conf_matrix_fcn, display_labels=class_names)
disp_fcn.plot(cmap=plt.cm.Blues, ax=axes[0], xticks_rotation='vertical')
axes[0].set_title("Matriz de Confusão: Dense")
# Matriz para o modelo CNN
disp_cnn = ConfusionMatrixDisplay(confusion_matrix=conf_matrix_cnn, display_labels=class_names)
disp_cnn.plot(cmap=plt.cm.Blues, ax=axes[1], xticks_rotation='vertical')
axes[1].set_title("Matriz de Confusão: CNN")
plt.tight_layout()
plt.show()
# Função para plotar os históricos de treinamento
def plot_training_history(histories, labels):
plt.figure(figsize=(14, 5))
# Plot da acurácia
plt.subplot(1, 2, 1)
for history, label in zip(histories, labels):
plt.plot(history.history['accuracy'], label=f'{label} Treino')
plt.plot(history.history['val_accuracy'], linestyle='--', label=f'{label} Validação')
plt.title('Acurácia Durante o Treinamento')
plt.xlabel('Época')
plt.ylabel('Acurácia')
plt.legend()
# Plot da perda
plt.subplot(1, 2, 2)
for history, label in zip(histories, labels):
plt.plot(history.history['loss'], label=f'{label} Treino')
plt.plot(history.history['val_loss'], linestyle='--', label=f'{label} Validação')
plt.title('Perda Durante o Treinamento')
plt.xlabel('Época')
plt.ylabel('Perda')
plt.legend()
plt.tight_layout()
plt.show()
# Plotar os resultados de treinamento
plot_training_history([history_fcn, history_cnn], ['Dense', 'CNN'])
Segmentação de Imagens e Detecção de Objetos#
A segmentação de imagens e a detecção de objetos são técnicas essenciais em visão computacional e processamento de imagens. Elas são amplamente utilizadas em diversas aplicações, como análise de imagens médicas, sistemas de condução autônoma e reconhecimento de padrões. Em Python, essas tarefas podem ser realizadas com bibliotecas como OpenCV, scikit-image e frameworks avançados como TensorFlow e PyTorch.
Segmentação de Imagens#
A segmentação de imagens é o processo de dividir uma imagem em partes ou regiões com base em características como cor, intensidade ou textura. O objetivo é simplificar a análise e identificação de padrões.
Tipos de Segmentação#
Segmentação Semântica: Classifica cada pixel em uma categoria sem distinguir objetos individuais da mesma classe. Por exemplo, em uma imagem de uma rua, todos os pixels que pertencem a carros seriam classificados como “carro”, independentemente de serem carros diferentes.
Segmentação de Instâncias: Identifica e diferencia objetos individuais, mesmo que pertençam à mesma classe. Por exemplo, em uma imagem de uma rua, cada carro seria identificado e diferenciado individualmente, permitindo a contagem e análise de cada carro separadamente.
Método Simples de Segmentação: Limiarização (Thresholding)#
A limiarização é uma técnica básica de segmentação. Ela divide a imagem em duas regiões (ou mais) com base na intensidade dos pixels. Por exemplo, em uma imagem em escala de cinza, podemos separar os pixels claros dos escuros utilizando um valor de limiar.
Exemplo Simples: Limiarização de uma Imagem#
Aqui está um exemplo de limiarização em uma imagem simples de moedas. (Link para baixar)
{kind=link}
import cv2
import numpy as np
import matplotlib.pyplot as plt
# Carregar a imagem em escala de cinza
image = cv2.imread('water_coins.jpg', cv2.IMREAD_GRAYSCALE)
# Aplicar limiarização
_, thresh = cv2.threshold(image, 127, 255, cv2.THRESH_BINARY)
# Criar subplots para exibir as imagens
fig, axs = plt.subplots(1, 2, figsize=(10, 5))
# Imagem original
axs[0].imshow(image, cmap='gray')
axs[0].set_title('Imagem Original')
axs[0].axis('off')
# Imagem após a limiarização
axs[1].imshow(thresh, cmap='gray')
axs[1].set_title('Limiarização Simples')
axs[1].axis('off')
# Ajustar layout e exibir
plt.tight_layout()
plt.show()

A linha:
_, thresh = cv2.threshold(image, 127, 255, cv2.THRESH_BINARY)
realiza uma limiarização binária na imagem em escala de cinza (image).
Funcionamento:
Pixels com valor menor que 127 são convertidos para 0 (preto), e pixels com valor igual ou maior que 127 são convertidos para 255 (branco).Parâmetros principais:
127: valor do limiar.255: valor atribuído aos pixels acima do limiar.cv2.THRESH_BINARY: modo binário, que classifica os pixels em preto ou branco.
O resultado é armazenado em thresh, que é a imagem binarizada.
Este método é ideal para imagens com bom contraste entre os objetos e o fundo, como no caso de moedas claras sobre um fundo escuro. No entanto, em casos mais complexos, como objetos sobrepostos, a limiarização simples pode não ser suficiente.
Segmentação Baseada em Marcadores e o Algoritmo Watershed#
Para situações mais complexas, como objetos que se tocam, o algoritmo Watershed é uma ferramenta poderosa. Ele utiliza a analogia da topografia para dividir objetos com base na intensidade dos pixels.
Teoria do Algoritmo Watershed#
Imagine uma imagem em escala de cinza como uma superfície tridimensional:
Regiões brilhantes correspondem a picos.
Regiões escuras correspondem a vales.
O algoritmo funciona como se você estivesse enchendo os vales com água colorida. À medida que a água sobe, barreiras são criadas onde diferentes cores se encontram. Essas barreiras formam os contornos dos objetos segmentados.
Problema do Ruído
Na prática, ruídos e irregularidades podem causar “supersegmentação”. Para resolver isso, usamos o método de Watershed Baseado em Marcadores, no qual:
Definimos áreas de fundo e objetos manualmente.
Utilizamos o algoritmo para encontrar os contornos.
Implementação Prática do Watershed#
Vamos segmentar uma imagem de moedas sobrepostas utilizando Watershed.
Etapa 1: Carregar a Imagem e Aplicar Limiarização com Otsu
import cv2
import numpy as np
from matplotlib import pyplot as plt
# Carregar a imagem
img = cv2.imread('water_coins.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Aplicar limiarização com Otsu
ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
# Exibir as imagens
fig, axs = plt.subplots(1, 2, figsize=(10, 5))
axs[0].imshow(gray, cmap='gray')
axs[0].set_title('Imagem Original')
axs[0].axis('off')
axs[1].imshow(thresh, cmap='gray')
axs[1].set_title('Limiarização com Otsu')
axs[1].axis('off')
plt.tight_layout()
plt.show()

Etapa 2: Remover Ruído e Identificar Áreas
Utilizamos operações morfológicas e transformadas de distância para identificar regiões de fundo, primeiro plano e áreas desconhecidas.
# Abertura morfológica para remoção de ruído
kernel = np.ones((3, 3), np.uint8)
opening = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernel, iterations=2)
# Determinar áreas de fundo
sure_bg = cv2.dilate(opening, kernel, iterations=3)
# Determinar áreas de primeiro plano
dist_transform = cv2.distanceTransform(opening, cv2.DIST_L2, 5)
_, sure_fg = cv2.threshold(dist_transform, 0.7 * dist_transform.max(), 255, 0)
# Identificar áreas desconhecidas
unknown = cv2.subtract(sure_bg, np.uint8(sure_fg))
# Exibir resultados
titles = ['Abertura Morfológica', 'Áreas de Fundo', 'Áreas de Primeiro Plano', 'Áreas Desconhecidas']
images = [opening, sure_bg, sure_fg, unknown]
fig, axs = plt.subplots(1, 4, figsize=(15, 5))
for ax, title, img in zip(axs, titles, images):
ax.imshow(img, cmap='gray')
ax.set_title(title)
ax.axis('off')
plt.tight_layout()
plt.show()

Etapa 3: Criar Marcadores e Aplicar Watershed (code completo)
Os marcadores são usados para rotular as áreas de interesse.
import cv2
import numpy as np
import matplotlib.pyplot as plt
# Carregar a imagem colorida
img = cv2.imread('water_coins.jpg')
# Converter a imagem para escala de cinza
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Aplicar limiarização para obter uma imagem binária
_, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
# Abertura morfológica para remoção de ruído
kernel = np.ones((3, 3), np.uint8)
opening = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernel, iterations=2)
# Determinar áreas de fundo
sure_bg = cv2.dilate(opening, kernel, iterations=3)
# Determinar áreas de primeiro plano
dist_transform = cv2.distanceTransform(opening, cv2.DIST_L2, 5)
_, sure_fg = cv2.threshold(dist_transform, 0.7 * dist_transform.max(), 255, 0)
# Converter sure_fg para CV_8U
sure_fg = np.uint8(sure_fg)
# Identificar áreas desconhecidas
unknown = cv2.subtract(sure_bg, sure_fg)
# Criar marcadores
_, markers = cv2.connectedComponents(sure_fg)
# Converter marcadores para o tipo correto
markers = markers.astype(np.int32)
# Adicionar 1 a todos os marcadores para que o fundo não seja 0, mas 1
markers = markers + 1
# Marcar a região desconhecida com 0
markers[unknown == 255] = 0
# Criar uma cópia da imagem em uint8 e 3 canais
img_watershed = img.astype(np.uint8)
# Aplicar Watershed
markers = cv2.watershed(img_watershed, markers)
# Marcar os contornos em vermelho
img_watershed[markers == -1] = [0, 0, 255]
# Criar uma imagem colorida com cada moeda em uma cor diferente
colored_markers = np.zeros_like(img)
colors = np.random.randint(0, 255, (np.max(markers) + 1, 3), dtype=np.uint8)
for marker in np.unique(markers):
if marker == 0 or marker == -1:
continue
colored_markers[markers == marker] = colors[marker]
# Exibir o resultado da segmentação com Watershed e as moedas coloridas lado a lado
fig, axs = plt.subplots(1, 2, figsize=(15, 5))
axs[0].imshow(cv2.cvtColor(img_watershed, cv2.COLOR_BGR2RGB))
axs[0].set_title('Segmentação com Watershed')
axs[0].axis('off')
axs[1].imshow(cv2.cvtColor(colored_markers, cv2.COLOR_BGR2RGB))
axs[1].set_title('Moedas Coloridas')
axs[1].axis('off')
plt.tight_layout()
plt.show()

O algoritmo Watershed é ideal para casos em que objetos estão sobrepostos ou apresentam bordas complexas. Ele oferece uma abordagem robusta para segmentação, especialmente quando combinado com limiarização, transformada de distância e operações morfológicas.
Exercício de Segmentação de Objetos#
O objetivo deste exercício é aplicar técnicas de segmentação de imagens para identificar e separar objetos em uma imagem. Você utilizará a biblioteca OpenCV em Python para realizar limiarização simples e o algoritmo Watershed.
Para este exercício, você deve escolher uma imagem de seu interesse que contenha múltiplos objetos. Certifique-se de que a imagem tenha um bom contraste entre os objetos e o fundo para facilitar a segmentação.
Etapas do Exercício
Carregar a Imagem
Escolha uma imagem de seu interesse e carregue-a em escala de cinza.
Limiarização Simples
Aplique a limiarização binária na imagem carregada.
Exiba a imagem original e a imagem após a limiarização lado a lado.
Limiarização com Otsu
Aplique a limiarização com o método de Otsu na imagem carregada.
Exiba a imagem original e a imagem após a limiarização com Otsu lado a lado.
Remoção de Ruído e Identificação de Áreas
Utilize operações morfológicas para remover ruído da imagem binarizada.
Determine áreas de fundo, primeiro plano e áreas desconhecidas.
Exiba as imagens resultantes das operações morfológicas e das áreas identificadas.
Aplicação do Algoritmo Watershed
Crie marcadores para as áreas de interesse.
Aplique o algoritmo Watershed para segmentar os objetos.
Exiba a imagem resultante da segmentação com Watershed e uma versão colorida dos objetos segmentados.
Analise os Resultados: Compare as imagens resultantes das diferentes etapas de segmentação e discuta os resultados obtidos.
Métodos Baseados em Redes Neurais#
YOLO11 é a mais recente iteração na série YOLO da Ultralytics para detectores de objetos em tempo real, redefinindo o que é possível com precisão, velocidade e eficiência de ponta.
Histórico do YOLO
A série YOLO (You Only Look Once) foi inicialmente desenvolvida por Joseph Redmon em 2016 e revolucionou o campo da visão computacional ao introduzir um método extremamente rápido e eficiente para detecção de objetos. Desde então, diversas versões aprimoradas foram lançadas, cada uma incorporando melhorias significativas em desempenho, precisão e capacidade de aplicação.
O YOLO11 é um marco nessa evolução, trazendo avanços substanciais na arquitetura e nos métodos de treinamento, tornando-se uma ferramenta versátil para uma ampla gama de tarefas de visão computacional.
Para mais informações, consulte a documentação oficial no site Ultralytics YOLO11.
Suporte a Várias Tarefas
A arquitetura do YOLO11 expande a flexibilidade introduzida no YOLOv8, oferecendo suporte aprimorado para diversas tarefas, incluindo:
Detecção de Objetos
Modelos:
yolo11n.pt,yolo11s.pt,yolo11m.pt,yolo11l.pt,yolo11x.ptRecursos: Inferência, validação, treinamento e exportação com suporte completo.
Segmentação de Instâncias
Modelos:
yolo11n-seg.pt,yolo11s-seg.pt,yolo11m-seg.pt,yolo11l-seg.pt,yolo11x-seg.ptCapacidade: Identifica e segmenta objetos dentro de uma imagem com precisão, suportando todos os modos.
Estimativa de Poses/Keypoints
Modelos:
yolo11n-pose.pt,yolo11s-pose.pt,yolo11m-pose.pt,yolo11l-pose.pt,yolo11x-pose.ptAplicação: Ideal para rastreamento de articulações ou movimentos corporais.
Detecção Orientada (Oriented Detection)
Modelos:
yolo11n-obb.pt,yolo11s-obb.pt,yolo11m-obb.pt,yolo11l-obb.pt,yolo11x-obb.ptUso: Especialmente útil para detectar objetos com orientações específicas (ex.: caixas inclinadas, placas em ângulo).
Classificação de Imagens
Modelos:
yolo11n-cls.pt,yolo11s-cls.pt,yolo11m-cls.pt,yolo11l-cls.pt,yolo11x-cls.ptFinalidade: Classifica imagens inteiras com alta precisão.
Essas capacidades tornam o YOLO uma ferramenta poderosa e adaptável para diversas necessidades em visão computacional.
Detecção de Objetos#
A detecção de objetos é uma tarefa central na visão computacional, cujo objetivo é identificar a localização e a classe de objetos em imagens ou vídeos. Um modelo de detecção de objetos gera como saída um conjunto de caixas delimitadoras que envolvem os objetos, acompanhadas de rótulos de classe e pontuações de confiança.
Esse tipo de modelo é amplamente utilizado em aplicações como vigilância, análise de tráfego e sistemas autônomos. Ele é particularmente útil quando é necessário localizar objetos de interesse em uma cena, mas não há demanda por uma segmentação precisa da forma dos objetos.
Neste exemplo, utilizamos o modelo YOLO (You Only Look Once) com pesos pré-treinados para realizar detecção de objetos e demonstramos como carregar, treinar e fazer previsões com o modelo.
{kind=link}
Carregando o Modelo
model = YOLO("yolo11n.pt")
O modelo é carregado utilizando pesos pré-treinados especificados no arquivo yolo11n.pt. Esses pesos já foram ajustados em um grande conjunto de dados, como o COCO, para tarefas de detecção de objetos.
Treinamento Opcional
model.train(data='coco8.yaml', epochs=3)
O método model.train é usado para treinar o modelo em um conjunto de dados personalizado ou para continuar o treinamento a partir dos pesos existentes. Aqui:
data='coco8.yaml'especifica o caminho para o arquivo de configuração do dataset.epochs=3define o número de épocas (passagens completas pelo dataset).
Este passo é opcional, pois os pesos carregados já possuem um bom desempenho geral. No entanto, você pode ajustá-los para um domínio específico.
Realizando Predições
results = model("bus.jpg")
O método model diretamente aplicado à imagem realiza a detecção de objetos. A saída inclui informações como caixas delimitadoras, classes e confiabilidade das detecções.
Exibindo os Resultados
As imagens original e segmentada são exibidas lado a lado:
A imagem original é carregada e convertida de BGR para RGB para exibição.
A imagem com resultados de segmentação é gerada pelo método
plot()do objeto de resultados.
segmented_img = results[0].plot()
Execução do Código
Certifique-se de ter as dependências instaladas, como ultralytics e matplotlib. Além disso, use imagens adequadas para prever e visualizar os resultados. Este exemplo demonstra como explorar os recursos do YOLO para realizar detecção de objetos de maneira eficiente e intuitiva.
# Instalação, caso precise
# !pip install ultralytics
from ultralytics import YOLO
import matplotlib.pyplot as plt
import cv2
# Carregar o modelo YOLO
model = YOLO("yolo11n.pt")
# Treinando o modelo com o COCO
#model.train(data='coco8.yaml', epochs=3)
# Prever a imagem com o modelo
results = model("bus.jpg")
# Obter a imagem original
img = cv2.imread("bus.jpg") # carregando a imagem original
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # converter de BGR para RGB para exibição no matplotlib
# Obter a imagem com os resultados
result_img = results[0].plot() # retorna a imagem com as caixas delimitadoras
# Converter a imagem de BGR (OpenCV) para RGB (Matplotlib) para exibição correta
result_img_rgb = cv2.cvtColor(result_img, cv2.COLOR_BGR2RGB)
# Exibir as imagens antes e depois da detecção
fig, axs = plt.subplots(1, 2, figsize=(15, 7))
# Exibir a imagem original
axs[0].imshow(img)
axs[0].set_title('Imagem Original')
axs[0].axis('off')
# Exibir a imagem resultante
axs[1].imshow(result_img_rgb)
axs[1].set_title('Resultado da Detecção')
axs[1].axis('off')
plt.tight_layout()
plt.show()

Explicação do log gerado pelo YOLO
O log contém informações importantes sobre o ambiente, a configuração do treinamento, a arquitetura da rede, e o modelo YOLO. Aqui estão as principais seções e o que elas representam:
Inicialização do Ambiente
Log:
New https://pypi.org/project/ultralytics/8.3.42 available...
Ultralytics 8.3.40 🚀 Python-3.10.12 torch-2.5.1+cu121 CUDA:0 (Tesla T4, 15102MiB)
Versão: A biblioteca Ultralytics está na versão 8.3.40 e há uma atualização disponível (8.3.42).
Configuração do ambiente: Python 3.10.12 com PyTorch 2.5.1, suporte a CUDA (Tesla T4).
Utilidade: Certifica que o ambiente está preparado para execução eficiente em GPU.
Configuração de Treinamento
Log:
engine/trainer: task=detect, mode=train, model=yolo11n.pt, data=coco8.yaml, epochs=3, ...
Explicação:
Tarefa: Detecção de objetos (
task=detect).Modelo:
yolo11n.pté um modelo YOLO customizado leve (YOLO Nano).Dataset:
coco8.yaml, configuração simplificada do COCO.Épocas: Treinamento configurado para 3 épocas.
Parâmetros chave:
batch=16: Tamanho do lote durante o treinamento.
imgsz=640: Resolução das imagens de entrada.
amp=True: Usa precisão mista (Automatic Mixed Precision) para acelerar o treinamento.
cos_lr=False: Desativa o agendador de taxa de aprendizado cosseno.
optimizer=auto: Seleção automática do melhor otimizador.
** Estrutura do Modelo**
Log:
from n params module arguments
0 -1 1 464 ultralytics.nn.modules.conv.Conv [3, 16, 3, 2]
...
YOLO11n summary: 319 layers, 2,624,080 parameters, 2,624,064 gradients, 6.6 GFLOPs
Arquitetura:
Consiste em 319 camadas com 2.6M parâmetros treináveis.
Inclui blocos como
Conv,C3k2,SPPF, eUpsample, otimizados para tarefas de detecção.
Complexidade: O modelo exige 6.6 GFLOPs, adequado para dispositivos com recursos limitados.
Detalhes dos blocos:
Conv: Camada convolucional básica.
C3k2: Bloco customizado baseado em ResNet para extração de características.
SPPF: Bloco com pooling para aumentar a recepção de campo.
Treinamento
Log:
Transferred 499/499 items from pretrained weights
AMP: running Automatic Mixed Precision (AMP) checks...
AMP: checks passed ✅
train: Scanning /content/datasets/coco8/labels/train.cache... 4 images, 0 backgrounds, 0 corrupt: ...
Pesos pré-treinados: Foram carregados 499 pesos de um modelo pré-treinado.
AMP: Garantia de que o treinamento utiliza precisão mista.
Dataset: Conjunto de treinamento possui 4 imagens (reduzido para testes).
Validação e Otimização
Log:
val: Scanning /content/datasets/coco8/labels/val.cache... 4 images...
optimizer: AdamW(lr=0.000119, momentum=0.9)...
Dataset de validação: Contém 4 imagens (tamanho similar ao de treino).
Otimização: Otimizador
AdamWescolhido automaticamente, com taxa de aprendizado inicial (lr=0.000119) e momentum (momentum=0.9).Utilidade: Validação avalia o desempenho do modelo após cada época.
Saídas e Ferramentas de Monitoramento
Log:
TensorBoard: Start with 'tensorboard --logdir runs/detect/train2'...
Logging results to runs/detect/train2
TensorBoard: Permite visualizar métricas de treinamento, como perda, precisão, e estrutura do modelo.
Diretório: Resultados e checkpoints são salvos no diretório
runs/detect/train2.
IoU (Intersection over Union)
A IoU (Intersection over Union) é uma métrica amplamente utilizada para avaliar o desempenho de modelos de detecção de objetos. Ela mede a sobreposição entre a área prevista pelo modelo e a área real de um objeto em uma imagem. A IoU é essencial em tarefas como detecção de objetos, segmentação semântica e rastreamento de objetos.
Definição Matemática A IoU é definida como a razão entre a interseção e a união de dois retângulos:
Caixa predita (\(B_p\)): A região delimitada pela predição do modelo.
Caixa real (\(B_r\)): A região delimitada pela anotação ou ground truth.
A fórmula matemática é:
\( \text{IoU} = \frac{\text{Área de Interseção}}{\text{Área de União}} \)
Interseção: A área comum entre \(B_p\) e \(B_r\).
União: A soma das áreas de \(B_p\) e \(B_r\), subtraída da interseção.
Intervalo de Valores
A IoU varia de 0 a 1:
0: Não há sobreposição entre as caixas.
1: Sobreposição perfeita, ou seja, \(B_p = B_r\).
Valores mais altos de IoU indicam predições mais precisas.
Segmentação de Objetos#
# !pip install ultralytics
from ultralytics import YOLO
import matplotlib.pyplot as plt
import cv2
# Carregar o modelo YOLO
model = YOLO("yolo11n-seg.pt")
# Treinando o modelo com o COCO
#model.train(data='coco8.yaml', epochs=3)
# Prever a imagem com o modelo
results = model("bus.jpg")
# Obter a imagem original
img = cv2.imread("bus.jpg") # carregando a imagem original
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # converter de BGR para RGB para exibição no matplotlib
# Obter a imagem com os resultados
result_img = results[0].plot() # retorna a imagem com as caixas delimitadoras
# Converter a imagem de BGR (OpenCV) para RGB (Matplotlib) para exibição correta
result_img_rgb = cv2.cvtColor(result_img, cv2.COLOR_BGR2RGB)
# Exibir as imagens antes e depois da detecção
fig, axs = plt.subplots(1, 2, figsize=(15, 7))
# Exibir a imagem original
axs[0].imshow(img)
axs[0].set_title('Imagem Original')
axs[0].axis('off')
# Exibir a imagem resultante
axs[1].imshow(result_img_rgb)
axs[1].set_title('Resultado da Segmentação')
axs[1].axis('off')
plt.tight_layout()
plt.show()

Pose Estimation#
from ultralytics import YOLO
import cv2
import matplotlib.pyplot as plt
# Carregar o modelo
model = YOLO("yolo11n-pose.pt")
# Fazer a predição na imagem
results = model("bus.jpg")
# Obter a imagem original
img = cv2.imread("bus.jpg") # carregando a imagem original
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # converter de BGR para RGB para exibição no matplotlib
# Obter a imagem original e os resultados
result_img = results[0].plot() # Gera uma imagem anotada com bounding boxes e keypoints
# Converter a imagem de BGR (OpenCV) para RGB (Matplotlib) para exibição correta
result_img_rgb = cv2.cvtColor(result_img, cv2.COLOR_BGR2RGB)
# Exibir as imagens antes e depois da detecção
fig, axs = plt.subplots(1, 2, figsize=(15, 7))
# Exibir a imagem original
axs[0].imshow(img)
axs[0].set_title('Imagem Original')
axs[0].axis('off')
# Exibir a imagem resultante
axs[1].imshow(result_img_rgb)
axs[1].set_title('Resultado da Pose')
axs[1].axis('off')
plt.tight_layout()
plt.show()

Exemplo de Detecção de Objetos em Vídeo#
Neste exemplo, utilizaremos o modelo YOLO para realizar segmentação em um vídeo. O vídeo utilizado contém os melhores momentos do surfista Gabriel Medina.
Faça o download do vídeo: Link do Vídeo.
O vídeo original pode ser encontrado no YouTube: Melhores Momentos Surfe do GABRIEL MEDINA 🏄♂️.
O código a seguir carrega o modelo YOLO treinado e aplica a segmentação quadro a quadro no vídeo fornecido, gerando um vídeo de saída com as anotações.
from ultralytics import YOLO
import cv2
# Carregar o modelo YOLO treinado
model = YOLO("yolo11n.pt")
# Caminhos dos vídeos
input_video_path = "medina.mp4" # Vídeo de entrada
output_video_path = "output.mp4" # Vídeo de saída
# Carregar o vídeo
cap = cv2.VideoCapture(input_video_path)
# Configurar o vídeo de saída com a mesma taxa de quadros e resolução do vídeo de entrada
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter(output_video_path, fourcc, cap.get(cv2.CAP_PROP_FPS),
(int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))))
# Processar cada quadro do vídeo
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# Realizar a segmentação no frame
results = model(frame)
# Extrair o frame com segmentação anotada
annotated_frame = results[0].plot() # `plot()` retorna a imagem com a segmentação aplicada
# Escrever o frame anotado no vídeo de saída
out.write(annotated_frame)
# Liberar os objetos
cap.release()
out.release()
cv2.destroyAllWindows()
print(f"Vídeo com segmentação salvo em: {output_video_path}")
O vídeo processado será salvo como output.mp4, contendo as anotações da segmentação para cada quadro.
Exercício: Repita o exemplo utilizando o modelo YOLO para testar as funcionalidades de segmentação e pose estimation. Para cada teste, calcule o tempo médio e o desvio padrão das inferências realizadas em cada quadro do vídeo. Após coletar os resultados, organize os dados em um gráfico de barras comparando os tempos médios de inferência entre as três abordagens: detecção de objetos, segmentação e pose estimation.
Dataset#
Vamos contruir um dataset. —> Acesse o link
Trabalho: Aplicação de IA e Visão Computacional#
Objetivo#
Aplicar técnicas de IA e Visão Computacional para resolver um problema prático usando segmentação, detecção, classificação de imagens ou estimativa de pose. Utilizar YOLO ou abordagem similar.
Desenvolvimento#
O trabalho envolve desenvolver e avaliar um modelo de Visão Computacional, seguindo estas etapas:
Seleção do Tema e Dataset:
Tema: Escolher entre segmentação, detecção, classificação ou estimativa de pose. Justificar a escolha.
Dataset: Selecionar dataset público (Kaggle ou outro) ou criar um. Justificar a escolha.
Pré-processamento:
Descrever:
Limpeza dos dados
Aumento de dados (data augmentation)
Normalização
Divisão em treinamento, validação e teste
Treinamento:
Arquitetura: Escolher e justificar uma arquitetura de rede.
Processo: Descrever:
Hiperparâmetros
Função de perda
Métricas de avaliação
Apresentar gráficos de treinamento e validação.
Resultados:
Apresentar resultados no conjunto de teste, usando as métricas definidas.
Incluir exemplos visuais.
Analisar os resultados.
Conclusão:
Discutir os resultados, comparando com trabalhos relacionados.
Sugerir melhorias e futuras pesquisas.
Refletir sobre a aplicabilidade prática.
Entrega (Relatório em .pdf)#
O relatório deve conter:
Introdução: Tema, motivação, objetivos e dataset.
Metodologia: Descrição das etapas de desenvolvimento.
Resultados: Apresentação e análise dos resultados.
Conclusão: Discussão, melhorias e futuras pesquisas.
Referências.
Datas#
Seleção do Tema e Dataset: 17/12/24 em sala de aula para o professor avaliar a viabilidade.
Entrega do relatório: 31/12/24 via tarefa cadastrada no SIGAA.
Referências e Conteúdo Extra#
Anotações do Dataset:
Vídeo(s)
Outro(s)