Capítulo 2: Machine Learning#
Fundamentos Matemáticos#
Para entender redes neurais artificiais, é essencial ter uma boa base em álgebra linear e cálculo [Zhang et al., 2023]. Esses conceitos são fundamentais para compreender como os modelos processam e transformam dados. A seguir, abordaremos os principais tópicos com exemplos práticos usando a biblioteca NumPy.
Álgebra Linear#
Álgebra linear lida com estruturas matemáticas como vetores, matrizes e tensores. Essas ferramentas são fundamentais para manipular e entender os dados que alimentam redes neurais.
Escalares: Um escalar é simplesmente um número único. Em redes neurais, eles costumam representar valores como pesos ou vieses — pequenos ajustes usados para ajudar o modelo a aprender.
import numpy as np
# Exemplo de escalar
escalar = 3.5
print(escalar)
3.5
Vetores: Um vetor é uma lista de números. Ele pode ser usado para representar entradas de um modelo, saídas ou até mesmo parâmetros. Imagine um vetor como um conjunto de características, como altura, peso e idade de uma pessoa, usados como entrada para um modelo.
# Exemplo de vetor
vetor = np.array([1.0, 2.0, 3.0])
print(vetor)
[1. 2. 3.]
Matrizes: Quando temos múltiplos vetores organizados, formamos uma matriz — uma grade de duas dimensões. Em redes neurais, matrizes podem armazenar grandes conjuntos de dados ou representar as conexões (pesos) entre as camadas de um modelo.
# Exemplo de matriz
matriz = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(matriz)
[[1 2 3]
[4 5 6]
[7 8 9]]
Tensores: Quando trabalhamos com mais de duas dimensões, estamos lidando com tensores. Redes neurais frequentemente utilizam tensores para representar dados complexos, como imagens coloridas (onde cada pixel tem valores de cor em três canais: vermelho, verde e azul).
# Exemplo de tensor 3D
tensor = np.random.rand(3, 3, 3)
print(tensor)
[[[0.86092583 0.68803215 0.33311945]
[0.77149024 0.42643031 0.90005941]
[0.22764019 0.35644062 0.75584702]]
[[0.96963316 0.17407432 0.3921849 ]
[0.34985739 0.67728245 0.72868431]
[0.91673118 0.59129186 0.74605684]]
[[0.05373217 0.37182579 0.93597411]
[0.32529004 0.25533829 0.6914945 ]
[0.02873603 0.27376316 0.30636661]]]
Essas operações são o alicerce do machine learning (redes neurais), permitindo que os modelos manipulem dados de forma eficiente e processem informações complexas em múltiplas dimensões.
Exercício: Álgebra Linear com NumPy#
O objetivo deste exercício é praticar a manipulação de escalares, vetores, matrizes e tensores usando a biblioteca NumPy. Esses conceitos são fundamentais para entender como os dados são processados em redes neurais artificiais.
Instruções:
Escalares: Crie um escalar e imprima seu valor.
Vetores: Crie um vetor com 3 elementos e imprima seu valor.
Matrizes: Crie uma matriz 3x3 e imprima seu valor.
Tensores: Crie um tensor 3D de dimensões 2x2x2 e imprima seu valor.
Complete o código abaixo para criar e imprimir um escalar, um vetor, uma matriz e um tensor usando a biblioteca NumPy.
import numpy as np
# Escalares
# Crie um escalar e imprima seu valor
escalar = ...
print("Escalar:", escalar)
# Vetores
# Crie um vetor com 3 elementos e imprima seu valor
vetor = ...
print("Vetor:", vetor)
# Matrizes
# Crie uma matriz 3x3 e imprima seu valor
matriz = ...
print("Matriz:\n", matriz)
# Tensores
# Crie um tensor 3D de dimensões 1x3x2 e imprima seu valor
tensor = ...
print("Tensor:\n", tensor)
Saída Esperada
Escalar: 10.5
Vetor: [1.0, 2.0, 3.0, 20.1, 30.1]
Matriz:
[[1, 1, 1], [2, 2, 2], [3, 3, 3]]
Tensor:
[[[0.85809185 0.24814785]
[0.14401491 0.11771045]
Dicas:
Use a função
np.arraypara criar vetores e matrizes.Use a função
np.random.randpara criar tensores com valores aleatórios.
Operações entre Escalares, Vetores e Matrizes#
Produto Interno (Produto Escalar)
O produto interno de dois vetores é uma operação que multiplica seus elementos correspondentes e soma os resultados. Matematicamente, para dois vetores \( \mathbf{a} \) e \( \mathbf{b} \) de dimensão \( n \):
\( \mathbf{a} \cdot \mathbf{b} = \sum_{i=1}^{n} a_i b_i \)
# Produto Interno
import numpy as np
vetor1 = np.array([1, 2, 3])
vetor2 = np.array([4, 5, 6])
produto_interno = np.dot(vetor1, vetor2)
print(produto_interno)
32
Multiplicação Matriz-Vetor
A multiplicação de uma matriz por um vetor resulta em um novo vetor. Matematicamente, para uma matriz \( \mathbf{A} \) de dimensão \( m \times n \) e um vetor \( \mathbf{x} \) de dimensão \( n \):
\( \mathbf{y} = \mathbf{A} \mathbf{x} \)
onde \( \mathbf{y} \) é um vetor de dimensão \( m \).
# Multiplicação Matriz-Vetor
matriz = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
vetor = np.array([1, 2, 3])
resultado = np.dot(matriz, vetor)
print(resultado)
[14 32 50]
Multiplicação Matriz-Matriz
A multiplicação de duas matrizes resulta em uma nova matriz. Matematicamente, para uma matriz \( \mathbf{A} \) de dimensão \( m \times n \) e uma matriz \( \mathbf{B} \) de dimensão \( n \times p \):
\( \mathbf{C} = \mathbf{A} \mathbf{B} \)
onde \( \mathbf{C} \) é uma matriz de dimensão \( m \times p \).
Para que a multiplicação de matrizes seja válida, o número de colunas da primeira matriz deve ser igual ao número de linhas da segunda matriz. Se isso não ocorrer, uma das matrizes pode precisar ser transposta.
# Multiplicação Matriz-Matriz
matriz1 = np.array([[1, 2], [3, 4], [5, 6]])
matriz2 = np.array([[7, 8], [9, 10]])
resultado = np.dot(matriz1, matriz2)
print(resultado)
[[ 25 28]
[ 57 64]
[ 89 100]]
Transposição de Matrizes
A transposição de uma matriz inverte suas linhas e colunas. Matematicamente, a transposta de uma matriz \( \mathbf{A} \) de dimensão \( m \times n \) é uma matriz \( \mathbf{A}^T \) de dimensão \( n \times m \).
# Transposição de Matriz
matriz = np.array([[1, 2, 3], [4, 5, 6]])
matriz_transposta = matriz.T
print(matriz_transposta)
[[1 4]
[2 5]
[3 6]]
Calculando a Norma Euclidiana
A norma euclidiana de um vetor é uma medida de sua magnitude (ou comprimento). Matematicamente, para um vetor \( \mathbf{v} \) de dimensão \( n \):
\( \| \mathbf{v} \| = \sqrt{\sum_{i=1}^{n} v_i^2} \)
# Norma Euclidiana
vetor = np.array([1, 2, 3])
norma_euclidiana = np.linalg.norm(vetor)
print(norma_euclidiana)
3.7416573867739413
Exercício: Operações entre Escalares, Vetores e Matrizes com NumPy#
O objetivo deste exercício é praticar operações fundamentais entre escalares, vetores e matrizes usando a biblioteca NumPy. Esses conceitos são essenciais para entender como os dados são processados em redes neurais artificiais.
Instruções:
Produto Interno (Produto Escalar): Calcule o produto interno de dois vetores.
Multiplicação Matriz-Vetor: Calcule a multiplicação de uma matriz por um vetor.
Multiplicação Matriz-Matriz: Calcule a multiplicação de duas matrizes.
Transposição de Matrizes: Calcule a transposição de uma matriz.
Norma Euclidiana: Calcule a norma euclidiana de um vetor.
Complete o código abaixo para realizar as operações descritas usando a biblioteca NumPy.
import numpy as np
# Produto Interno (Produto Escalar)
vetor1 = np.array([1, 2, 3])
vetor2 = np.array([4, 5, 6])
produto_interno = ...
print("Produto Interno:", produto_interno)
# Multiplicação Matriz-Vetor
matriz = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
vetor = np.array([1, 2, 3])
resultado_mv = ...
print("Multiplicação Matriz-Vetor:\n", resultado_mv)
# Multiplicação Matriz-Matriz
matriz1 = np.array([[1, 2], [3, 4], [5, 6]])
matriz2 = np.array([[7, 8], [9, 10]])
resultado_mm = ...
print("Multiplicação Matriz-Matriz:\n", resultado_mm)
# Transposição de Matrizes
matriz = np.array([[1, 2, 3], [4, 5, 6]])
matriz_transposta = ...
print("Transposição de Matriz:\n", matriz_transposta)
# Norma Euclidiana
vetor = np.array([1, 2, 3])
norma_euclidiana = ...
print("Norma Euclidiana:", norma_euclidiana)
Saída Esperada
Produto Interno: 32
Multiplicação Matriz-Vetor:
[14 32 50]
Multiplicação Matriz-Matriz:
[[ 25 28]
[ 57 64]
[ 89 100]]
Transposição de Matriz:
[[1 4]
[2 5]
[3 6]]
Norma Euclidiana: 3.7416573867739413
Dicas:
Use a função
np.dotpara calcular o produto interno e a multiplicação de matrizes.Use o atributo
.Tpara calcular a transposição de uma matriz.Use a função
np.linalg.normpara calcular a norma euclidiana de um vetor.
Cálculo#
O cálculo é uma ferramenta essencial em machine learning, especialmente para a otimização de modelos. Ele é utilizado para ajustar os parâmetros dos modelos para minimizar a função de custo e melhorar a precisão. Aqui, exploraremos alguns dos conceitos fundamentais de cálculo que são mais relevantes em machine learning: derivadas parciais (gradientes), a regra da cadeia e o conceito de backpropagation.
Derivadas Parciais (Gradientes)#
Em machine learning, os modelos são frequentemente ajustados para minimizar uma função de custo \( J(\theta) \), que mede o erro das previsões do modelo. Para minimizar essa função de custo, utilizamos gradientes, que são vetores de derivadas parciais da função de custo em relação a cada um dos parâmetros do modelo.
Definição de Derivadas Parciais
Se temos uma função \( f(x_1, x_2, \ldots, x_n) \), a derivada parcial de \( f \) em relação a \( x_i \) é denotada por \( \frac{\partial f}{\partial x_i} \) e é definida como:
\( \frac{\partial f}{\partial x_i} = \lim_{\Delta x_i \to 0} \frac{f(x_1, \ldots, x_i + \Delta x_i, \ldots, x_n) - f(x_1, \ldots, x_i, \ldots, x_n)}{\Delta x_i} \)
Gradiente
O gradiente de uma função \( J(\theta) \) com respeito aos seus parâmetros \( \theta \) é um vetor de derivadas parciais:
\( \nabla J(\theta) = \left[ \frac{\partial J}{\partial \theta_1}, \frac{\partial J}{\partial \theta_2}, \ldots, \frac{\partial J}{\partial \theta_n} \right] \)
Vamos reorganizar o material apresentado, mantendo o foco em explicar a regra da cadeia no contexto do cálculo de gradientes em Machine Learning.
Regra da Cadeia#
A regra da cadeia é uma ferramenta do cálculo diferencial utilizada para calcular a derivada de funções compostas. Ela é amplamente aplicada no treinamento de redes neurais, principalmente no cálculo de gradientes durante o processo de retropropagação (ou backpropagation). Esse cálculo é crucial para ajustar os pesos das redes neurais com base no erro cometido nas previsões.
Derivadas de Funções Compostas#
A regra da cadeia nos ajuda a encontrar a derivada de uma função composta. Por exemplo, para duas funções \( f(g(x)) \), a derivada em relação a \( x \) é dada por:
\( \frac{d}{dx} f(g(x)) = f'(g(x)) \cdot g'(x) \)
Aplicação no Treinamento de Redes Neurais#
Em redes neurais, o objetivo é minimizar uma função de perda que mede o erro entre as previsões do modelo e os valores reais. Esse processo envolve calcular os gradientes da função de perda em relação aos pesos da rede, para ajustá-los de modo a reduzir o erro nas iterações seguintes.
No treinamento, a função de perda \( L \) depende dos valores calculados por várias camadas de neurônios. A regra da cadeia é utilizada para propagar o erro de volta por todas essas camadas. Assim, o gradiente da perda em relação aos pesos \( w \) de uma camada é:
\( \frac{\partial L}{\partial w} = \frac{\partial L}{\partial f} \cdot \frac{\partial f}{\partial w} \)
Isso nos permite ajustar os pesos da rede usando algoritmos de otimização, como o gradiente descendente, que movem os pesos na direção oposta ao gradiente para minimizar o erro.
Exemplo Prático#
Vamos ver como a regra da cadeia pode ser aplicada para calcular a derivada de uma função composta. Considere a função \( f(x) = (x^2 + 1)^3 \). Vamos calcular a derivada dessa função em relação a \( x \) aplicando a regra da cadeia.
Passos:
Definimos a função interna \( g(x) = x^2 + 1 \) e a função externa \( f(u) = u^3 \), onde \( u = g(x) \).
Calculamos as derivadas de \( g(x) \) e \( f(u) \).
Aplicamos a regra da cadeia para obter a derivada de \( f(x) \) em relação a \( x \).
Implementação em Python
import numpy as np
# Função interna g(x) = x^2 + 1
def g(x):
return x**2 + 1
# Função externa f(u) = u^3
def f(u):
return u**3
# Derivada de g(x), ou seja, dg/dx = 2x
def dg_dx(x):
return 2 * x
# Derivada de f(u), ou seja, df/du = 3u^2
def df_du(u):
return 3 * u**2
# Aplicação da regra da cadeia para calcular dy/dx
def dy_dx(x):
u = g(x) # Calcula g(x)
return df_du(u) * dg_dx(x) # Aplica a regra da cadeia
# Testando com x = 2
x = 2
print(f"Derivada de f(x) em relação a x quando x = {x}: {dy_dx(x)}")
Saída:
Derivada de f(x) em relação a x quando x = 2: 300.0
Cálculo Manual
Calcule \( u = g(x) \) para \( x = 2 \):
\( u = g(2) = 2^2 + 1 = 5 \)
Calcule \( \frac{du}{dx} \) para \( x = 2 \):
\( \frac{du}{dx} = 2x = 4 \)
Calcule \( \frac{dy}{du} \) para \( u = 5 \):
\( \frac{dy}{du} = 3u^2 = 75 \)
Aplique a regra da cadeia:
\( \frac{dy}{dx} = \frac{dy}{du} \cdot \frac{du}{dx} = 75 \cdot 4 = 300 \)
Portanto, tanto o cálculo manual quanto a implementação em Python resultam no mesmo valor: 300.
Exercício de Cálculo#
Derivar uma Função Composta Usando a Regra da Cadeia
Considere a função \( h(x) = \sin(x^2) \). Calcule a derivada de \( h(x) \) em relação a \( x \).
A regra da cadeia nos diz que:
\( \frac{dh}{dx} = \frac{dh}{du} \cdot \frac{du}{dx} \)
Vamos calcular a derivada de \( h(x) \) em relação a \( x \) para \( x = 1 \) matematicamente:
Calcule \( u = g(x) \) para \( x = 1 \):
\( u = g(1) = 1^2 = 1 \)
Calcule \( \frac{du}{dx} \) para \( x = 1 \):
\( \frac{du}{dx} = 2x = 2 \cdot 1 = 2 \)
Calcule \( \frac{dh}{du} \) para \( u = 1 \):
\( \frac{dh}{du} = \cos(u) = \cos(1) \)
Aplique a regra da cadeia:
\( \frac{dh}{dx} = \frac{dh}{du} \cdot \frac{du}{dx} = \cos(1) \cdot 2 \)
Implemente estes cálculos em Python:
import numpy as np
# Definindo a função interna g(x) = x^2
# Definindo a função externa f(u) = sin(u)
# Definindo a derivada da função interna dg/dx = 2x
# Definindo a derivada da função externa df/du = cos(u)
# Aplicando a regra da cadeia para calcular dh/dx
# Testando a função com x = 1
x = 1
print(f"Derivada de h(x) em relação a x em x = {x}: {dh_dx(x)}")
Verifique a Saída:
Derivada de h(x) em relação a x em x = 1: 1.0806046117362795
Probabilidade e Estatística#
Probabilidade#
Probabilidade é o estudo da incerteza e é essencial em Machine Learning para modelar eventos futuros com base em dados observados. Muitos algoritmos utilizam probabilidade para prever a ocorrência de eventos, classificar dados e inferir padrões a partir de exemplos.
Definições básicas:#
Espaço Amostral (S): Em Machine Learning, o espaço amostral representa o conjunto de todos os possíveis resultados ou categorias de uma variável. Por exemplo, ao classificar imagens de gatos e cães, o espaço amostral seria \( S = \{\text{gato}, \text{cão}\} \).
Evento (A): Um evento pode ser a ocorrência de uma classe específica no modelo, como “A = imagem classificada como gato”.
Fórmula da Probabilidade:#
A probabilidade de um evento \(A\) ocorrer, como a classificação correta de uma imagem, é dada por:
\( P(A) = \frac{\text{Número de resultados favoráveis}}{\text{Número total de resultados possíveis}} \)
Exemplo: Se um modelo acerta 80 classificações corretas em 100 tentativas, a probabilidade de uma classificação correta seria:
\( P(\text{correto}) = \frac{80}{100} = 0.8 \)
# Cálculo básico de probabilidade
resultados_favoraveis = 80
total_resultados = 100
probabilidade = resultados_favoraveis / total_resultados
print(f'Probabilidade de acerto: {probabilidade}')
Probabilidade de acerto: 0.8
Teorema de Bayes#
O Teorema de Bayes nos dá uma maneira de calcular a probabilidade de um evento \( A \) ocorrer, dado que outro evento \( B \) já ocorreu. É expressado como:
\( P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)} \)
Onde:
\( P(A|B) \) é a probabilidade de \( A \) dado \( B \).
\( P(B|A) \) é a probabilidade de \( B \) dado \( A \).
\( P(A) \) é a probabilidade de \( A \) ocorrer independentemente.
\( P(B) \) é a probabilidade de \( B \) ocorrer independentemente.
Este teorema é essencial em várias áreas de aprendizado de máquina, pois permite a atualização de probabilidades com base em novas informações, como no Naive Bayes Classifier.
Aplicação em Algoritmos:#
Naive Bayes Classifier: Um algoritmo de classificação que utiliza a probabilidade condicional para classificar dados. Ele assume que as características são independentes e usa o Teorema de Bayes para calcular a probabilidade de cada classe.
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
# Exemplo com o dataset Iris
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=42)
# Treinando o classificador Naive Bayes
clf = GaussianNB()
clf.fit(X_train, y_train)
# Fazendo previsões
y_pred = clf.predict(X_test)
# Saída do Código:
print(f'Previsões: {y_pred}')
# Avaliando a precisão do modelo
accuracy = accuracy_score(y_test, y_pred)
# Saída do Código:
print(f'Precisão do modelo: {accuracy:.2f}')
Previsões: [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0]
Precisão do modelo: 1.00
Variável Aleatória#
Uma variável aleatória mapeia os resultados de um experimento em valores numéricos e pode ser discreta ou contínua. Em Machine Learning, variáveis aleatórias ajudam a modelar incertezas e lidar com dados ruidosos ou incompletos.
Função de Probabilidade (discreta):#
A probabilidade de uma variável aleatória \(X\) assumir um valor específico \(x\) é:
\( P(X = x) = p(x) \)
Exemplo: Em um modelo de classificação de spam, a probabilidade de um email ser spam (\(X = \text{spam}\)) pode ser calculada com base nas características do email.
import numpy as np
# Probabilidade discreta para classificação binária (exemplo de email ser spam)
# Supomos que 40 emails de 100 são spam
total_emails = 100
spam_emails = 40
P_spam = spam_emails / total_emails
print(f'Probabilidade de um email ser spam: {P_spam}')
Probabilidade de um email ser spam: 0.4
Função Densidade de Probabilidade (contínua):#
A função densidade de probabilidade (PDF) é uma função matemática que descreve a probabilidade relativa de uma variável contínua assumir um determinado valor. Em outras palavras, a PDF nos diz a probabilidade de uma variável contínua estar em um intervalo específico.
Para uma variável contínua \( X \), a PDF \( f(x) \) é definida de tal forma que a probabilidade de \( X \) estar entre dois valores \( a \) e \( b \) é dada pela integral da PDF entre esses valores:
\( P(a \leq X \leq b) = \int_{a}^{b} f(x) \, dx \)
Exemplo de PDF de uma Variável Contínua Normal:#
Uma das PDFs mais comuns é a da distribuição normal (ou gaussiana), que é frequentemente usada em modelos de regressão. A PDF de uma variável normal \( X \) com média \( \mu \) e desvio padrão \( \sigma \) é dada por:
\( f(x) = \frac{1}{\sigma \sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}} \)
Aplicação em Modelos de Regressão:#
Em modelos de regressão, como a regressão linear, a PDF é usada para modelar a distribuição dos erros (resíduos) entre os valores observados e os valores preditos. A suposição comum é que os erros seguem uma distribuição normal com média zero e desvio padrão constante. Isso permite que os modelos de regressão façam inferências estatísticas sobre os parâmetros do modelo e a precisão das previsões.
Exemplo em Python:#
import scipy.stats as stats
import numpy as np
import matplotlib.pyplot as plt
# Exemplo de função densidade de probabilidade (PDF) de uma variável contínua normal
mu = 0 # média
sigma = 1 # desvio padrão
x = np.linspace(-5, 5, 100)
pdf = stats.norm.pdf(x, mu, sigma)
# Plotando a PDF
plt.plot(x, pdf)
plt.title('Função Densidade de Probabilidade (PDF) de uma Variável Contínua Normal')
plt.xlabel('Valor de x')
plt.ylabel('Densidade de Probabilidade')
plt.show()
Saída Esperada:#
O gráfico gerado mostrará a curva da PDF de uma variável normal com média \( \mu = 0 \) e desvio padrão \( \sigma = 1 \). A curva terá um pico no valor da média e decairá simetricamente em ambos os lados, representando a distribuição dos valores da variável contínua.
Estatística Descritiva#
A estatística descritiva é crucial para entender os dados antes de construir modelos de Machine Learning. Ela resume as principais características do conjunto de dados.
Medidas de Tendência Central:#
Média (\(\mu\)): Representa o valor médio dos dados. Em algoritmos de regressão, a média pode ser usada para calcular o erro médio, como no Erro Quadrático Médio (MSE).
\( \mu = \frac{1}{n}\sum_{i=1}^n x_i \)
# Calcular a média
dados = [10, 15, 23, 42, 12, 5, 67]
media = np.mean(dados)
print(f'Média: {media}')
Medidas de Dispersão:#
Variância (\(\sigma^2\)): Mede a dispersão dos dados ao redor da média. Algoritmos como PCA (Análise de Componentes Principais) usam variância para identificar quais características são mais relevantes.
\( \sigma^2 = \frac{1}{n}\sum_{i=1}^n (x_i - \mu)^2 \)
# Calcular a variância
variancia = np.var(dados)
print(f'Variância: {variancia}')
Desvio Padrão (\(\sigma\)): Muito usado para identificar o grau de dispersão nos dados.
# Calcular o desvio padrão
desvio_padrao = np.std(dados)
print(f'Desvio Padrão: {desvio_padrao}')
Inferência Estatística#
Inferência estatística é o processo de fazer generalizações ou previsões sobre uma população maior com base em uma amostra de dados. Em outras palavras, é a prática de usar dados de uma amostra para fazer conclusões sobre a população da qual a amostra foi extraída. Isso é fundamental em muitas áreas, incluindo ciências sociais, medicina, economia e, claro, Machine Learning.
Em Machine Learning, a inferência estatística é usada para:
Validar Modelos: Avaliar o desempenho de um modelo em dados de teste para garantir que ele generaliza bem para novos dados.
Testar Hipóteses: Verificar se as relações encontradas nos dados são estatisticamente significativas e não ocorreram por acaso.
Estimar Parâmetros: Estimar os parâmetros de um modelo (como coeficientes de regressão) e determinar a incerteza associada a essas estimativas.
O intervalo de confiança é uma ferramenta estatística que indica a faixa de valores em que acreditamos que o valor verdadeiro de um parâmetro está, com um certo nível de confiança. Por exemplo, um intervalo de confiança de 95% para a média de uma população significa que temos 95% de confiança de que o valor verdadeiro da média está dentro desse intervalo.
Em modelos de regressão, o intervalo de confiança para os coeficientes ajuda a determinar se uma variável é estatisticamente significativa. Se o intervalo de confiança para um coeficiente não inclui zero, isso sugere que a variável tem um efeito significativo no modelo.
Exemplo Básico de Intervalo de Confiança
Vamos calcular um intervalo de confiança de 95% para a média de uma amostra de dados fictícios.
import numpy as np
from scipy import stats
# Dados fictícios
dados = np.random.randn(100)
media_dados = np.mean(dados)
desvio_padrao_dados = np.std(dados)
# Intervalo de confiança 95%
intervalo = stats.norm.interval(0.95, loc=media_dados, scale=desvio_padrao_dados/np.sqrt(len(dados)))
print(f'Intervalo de Confiança: {intervalo}')
Saída Esperada Aproximada devido ao random
Intervalo de Confiança: (-0.08619762174596416, 0.08619762174596416)
Exercício: Probabilidade e Estatística#
O objetivo deste exercício é praticar conceitos fundamentais de probabilidade e estatística usando Python. Esses conceitos são essenciais para entender e aplicar algoritmos de Machine Learning.
Instruções:
Cálculo de Probabilidade: Calcule a probabilidade de um evento com base no número de resultados favoráveis e no número total de resultados possíveis.
Probabilidade Discreta: Calcule a probabilidade de uma variável aleatória discreta.
Função Densidade de Probabilidade (PDF): Plote a função densidade de probabilidade de uma variável contínua normal.
Medidas de Tendência Central: Calcule a média de um conjunto de dados.
Medidas de Dispersão: Calcule a variância e o desvio padrão de um conjunto de dados.
Distribuição Normal: Plote uma distribuição normal.
Intervalo de Confiança: Calcule o intervalo de confiança para a média de um conjunto de dados.
Complete o código abaixo para realizar as operações descritas usando Python.
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
# Cálculo de Probabilidade
resultados_favoraveis = 80
total_resultados = 100
probabilidade = ...
print(f'Probabilidade de acerto: {probabilidade}')
# Probabilidade Discreta
total_emails = 100
spam_emails = 40
P_spam = ...
print(f'Probabilidade de um email ser spam: {P_spam}')
# Função Densidade de Probabilidade (PDF)
mu = 0 # média
sigma = 1 # desvio padrão
x = np.linspace(-5, 5, 100)
pdf = ...
plt.plot(x, pdf)
plt.title('Função Densidade de Probabilidade (PDF)')
plt.show()
# Medidas de Tendência Central
dados = [10, 15, 23, 42, 12, 5, 67]
media = ...
print(f'Média: {media}')
# - Medidas de Dispersão
variancia = ...
desvio_padrao = ...
print(f'Variância: {variancia}')
print(f'Desvio Padrão: {desvio_padrao}')
# Distribuição Normal
plt.plot(x, stats.norm.pdf(x, mu, sigma))
plt.title('Distribuição Normal')
plt.show()
# - Intervalo de Confiança
dados = np.random.randn(100)
media_dados = np.mean(dados)
desvio_padrao_dados = np.std(dados)
intervalo = ...
print(f'Intervalo de Confiança: {intervalo}')
Saída Esperada
Probabilidade de acerto: 0.8
Probabilidade de um email ser spam: 0.4
Média: 24.857142857142858
Variância: 421.55102040816325
Desvio Padrão: 20.531707683681923
Intervalo de Confiança: (-0.16913820580756977, 0.22402578926619593)
Dicas:
Use operações aritméticas básicas para calcular a probabilidade.
Use a função
np.meanpara calcular a média.Use a função
np.varpara calcular a variância.Use a função
np.stdpara calcular o desvio padrão.Use a função
stats.norm.pdfpara calcular a função densidade de probabilidade.Use a função
stats.norm.intervalpara calcular o intervalo de confiança.
Manipulação e Pré-processamento de Dados#
Limpeza de Dados#
A limpeza de dados é uma fase crucial no pré-processamento de dados, sendo necessária para garantir que os dados sejam consistentes, completos e livres de erros antes de realizar análises ou construir modelos de aprendizado de máquina. A seguir, exploraremos os principais aspectos da limpeza de dados, com exemplos e códigos em Python.
Remoção de Dados Ausentes (Missing Data)
Em datasets reais, a presença de valores ausentes é comum. Esses valores podem estar ausentes por diversas razões, como erros na coleta ou falhas no sensor. Para lidar com eles, podemos usar as seguintes abordagens:
Exclusão de dados ausentes: Eliminar as linhas ou colunas onde os valores ausentes estão presentes.
Substituição de valores ausentes: Também chamada de imputação, envolve preencher os valores ausentes com estimativas, como a média ou a mediana dos dados existentes.
Exemplo prático: Substituição com a média
Vamos analisar um conjunto de dados sobre pacientes, onde alguns valores de idade estão ausentes.
import pandas as pd
import numpy as np
# Criando um DataFrame de exemplo
data = {'Nome': ['Ana', 'Bruno', 'Carlos', 'Daniela'],
'Idade': [25, np.nan, 30, np.nan],
'Peso': [70, 82, 65, 55]}
df = pd.DataFrame(data)
print("Dados originais:\n", df)
# Substituição de valores ausentes pela média sem usar inplace
df['Idade'] = df['Idade'].fillna(df['Idade'].mean())
# Arredondando a coluna Idade para duas casas decimais
df['Idade'] = df['Idade'].round(2)
print("\nApós substituição da média (com 2 casas decimais) na coluna Idade:\n", df)
Saída:
Dados originais:
Nome Idade Peso
0 Ana 25.0 70
1 Bruno NaN 82
2 Carlos 30.0 65
3 Daniela NaN 55
Após substituição da média (com 2 casas decimais) na coluna Idade:
Nome Idade Peso
0 Ana 25.00 70
1 Bruno 27.50 82
2 Carlos 30.00 65
3 Daniela 27.50 55
Neste exemplo, substituímos os valores ausentes na coluna Idade pela média das idades conhecidas. A média foi calculada como \( \frac{25 + 30}{2} = 27.5 \).
Tratamento de Dados Duplicados
Os dados duplicados podem distorcer a análise e devem ser removidos para garantir a integridade do dataset. Duplicatas podem surgir devido a erros na coleta ou processamento dos dados.
Exemplo prático: Remoção de duplicados
# Criando um DataFrame com valores duplicados
data_dup = {'Nome': ['Ana', 'Bruno', 'Carlos', 'Bruno'],
'Idade': [25, 22, 30, 22],
'Peso': [70, 82, 65, 82]}
df_dup = pd.DataFrame(data_dup)
print("\nDados com duplicatas:\n", df_dup)
# Removendo duplicados
df_clean = df_dup.drop_duplicates()
print("\nApós remoção de duplicatas:\n", df_clean)
Saída:
Dados com duplicatas:
Nome Idade Peso
0 Ana 25 70
1 Bruno 22 82
2 Carlos 30 65
3 Bruno 22 82
Após remoção de duplicatas:
Nome Idade Peso
0 Ana 25 70
1 Bruno 22 82
2 Carlos 30 65
Aqui, o registro duplicado de “Bruno” foi removido. O método drop_duplicates() garantiu que apenas uma instância de cada entrada permanecesse no dataset.
Correção de Erros
Erros nos dados podem surgir devido a vários fatores, como entradas incorretas ou falhas em sensores. Um exemplo típico é encontrar valores fora do intervalo esperado, como idades negativas ou excessivamente altas.
Exemplo prático: Identificação e correção de valores fora de um intervalo esperado
Se os valores de idade devem estar entre 0 e 120 anos, valores fora desse intervalo são considerados erros.
# Criando um DataFrame com possíveis erros
data_err = {'Nome': ['Ana', 'Bruno', 'Carlos', 'Daniela'],
'Idade': [25, 22, 150, -5],
'Peso': [70, 82, 65, 55]}
df_err = pd.DataFrame(data_err)
print("\nDados com possíveis erros:\n", df_err)
# Corrigindo valores fora do intervalo esperado
df_err.loc[df_err['Idade'] > 120, 'Idade'] = np.nan # Substituindo por NaN idades > 120
df_err.loc[df_err['Idade'] < 0, 'Idade'] = np.nan # Substituindo por NaN idades < 0
print("\nApós correção de erros na coluna Idade:\n", df_err)
Saída:
Dados com possíveis erros:
Nome Idade Peso
0 Ana 25 70
1 Bruno 22 82
2 Carlos 150 65
3 Daniela -5 55
Após correção de erros na coluna Idade:
Nome Idade Peso
0 Ana 25.0 70
1 Bruno 22.0 82
2 Carlos NaN 65
3 Daniela NaN 55
Os valores inválidos de idade (150 e -5) foram substituídos por NaN para posterior tratamento. Essa abordagem é útil quando não se pode determinar um valor correto e é necessário eliminar ou substituir o erro.
A limpeza de dados é essencial para garantir a qualidade de qualquer análise ou modelo de aprendizado de máquina. Métodos como a substituição de valores ausentes, remoção de duplicatas e correção de erros são fundamentais para transformar dados brutos em dados utilizáveis. O uso de bibliotecas como pandas facilita o processo, tornando possível lidar de forma eficiente com grandes quantidades de dados e garantir sua consistência e precisão.
Normalização e Padronização#
Normalização e padronização são técnicas fundamentais para ajustar os dados em uma escala comum, garantindo que as variáveis sejam tratadas igualmente pelos modelos de aprendizado de máquina. Esses processos evitam que variáveis com magnitudes diferentes dominem a análise ou o treinamento.
Min-Max Scaling
A normalização pelo método de Min-Max transforma os dados para que estejam dentro de um intervalo específico, geralmente entre [0, 1]. A fórmula para normalização Min-Max é:
\( X' = \frac{X - X_{min}}{X_{max} - X_{min}} \)
Onde:
\(X'\) é o valor normalizado,
\(X\) é o valor original,
\(X_{min}\) é o valor mínimo da variável,
\(X_{max}\) é o valor máximo da variável.
Essa técnica é útil em modelos como redes neurais, onde valores muito grandes podem dificultar o treinamento.
Exemplo:
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
data = {'Salario': [50000, 62000, 70000, 56000]}
df = pd.DataFrame(data)
scaler = MinMaxScaler()
df['Salario_normalizado'] = scaler.fit_transform(df[['Salario']])
print(df)
Saida:
Salario Salario_normalizado
0 50000 0.0
1 62000 0.6
2 70000 1.0
3 56000 0.3
Z-score Normalization (Padronização)
A padronização pelo Z-score transforma os dados para que tenham uma média de 0 e desvio padrão 1. A fórmula é:
\( Z = \frac{X - \mu}{\sigma} \)
Onde:
\(Z\) é o valor padronizado,
\(X\) é o valor original,
\(\mu\) é a média dos dados,
\(\sigma\) é o desvio padrão.
Essa técnica é essencial para modelos baseados em distância, como KNN e SVM, garantindo que variáveis em diferentes escalas contribuam de forma equilibrada.
Exemplo:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df['Salario_padronizado'] = scaler.fit_transform(df[['Salario']])
print(df)
Saída:
Salario Salario_normalizado Salario_padronizado
0 50000 0.0 -1.283901
1 62000 0.6 0.337869
2 70000 1.0 1.419048
3 56000 0.3 -0.473016
Ambas as técnicas são úteis em diferentes cenários, sendo a normalização indicada quando há limites fixos nos dados, e a padronização quando se quer remover a dependência de escala e trabalhar com média e variabilidade dos dados.
Tratamento de Outliers#
Outliers são valores que se diferenciam significativamente da maioria dos dados e podem distorcer a análise ou o desempenho dos modelos de aprendizado de máquina. Identificar e tratar outliers é crucial para garantir a qualidade dos resultados.
Técnicas Comuns de Detecção de Outliers:
Boxplot (Diagrama de Caixa): Um método visual que utiliza o conceito de quartis. Valores além de 1.5 vezes o intervalo interquartil (IQR) são considerados outliers.
Z-score: Calcula quantos desvios padrão um valor está distante da média. Valores por exemplo, com um Z-score maior que 1.5 (ou menor que -1.5) podem ser considerados outliers.
Exemplo prático: Detecção de outliers usando Z-score
Neste exemplo, usamos o Z-score para identificar possíveis outliers em uma amostra de dados.
import pandas as pd
import numpy as np
from scipy import stats
# Criando um DataFrame de exemplo
data_outliers = {'Nome': ['Ana', 'Bruno', 'Carlos', 'Daniela', 'Eduardo'],
'Idade': [25, 22, 30, 27, 100],
'Peso': [70, 82, 65, 55, 85]}
df_outliers = pd.DataFrame(data_outliers)
# Calculando o Z-score para a coluna 'Idade'
df_outliers['Z_score_Idade'] = stats.zscore(df_outliers['Idade'])
print("Dados originais com Z-Score")
print(df_outliers)
# Filtrando os outliers com base no Z-score (> 1.5 ou < -1.5)
outliers = df_outliers[(df_outliers['Z_score_Idade'] > 1.5) | (df_outliers['Z_score_Idade'] < -1.5)]
print("\nOutliers detectados\n", outliers)
Saída:
Dados originais com Z-Score
Nome Idade Peso Z_score_Idade
0 Ana 25 70 -0.531724
1 Bruno 22 82 -0.632685
2 Carlos 30 65 -0.363457
3 Daniela 27 55 -0.464417
4 Eduardo 100 85 1.992284
Outliers detectados
Nome Idade Peso Z_score_Idade
4 Eduardo 100 85 1.992284
Neste exemplo, o valor de idade 100 é identificado como um outlier, já que seu Z-score é maior que 1.5. Outliers como esse podem ser tratados, seja pela remoção ou substituição por valores mais representativos.
A detecção de outliers é um passo essencial para garantir a integridade dos dados antes de aplicar qualquer modelo de aprendizado de máquina. O uso de técnicas como Z-score e boxplot facilita essa tarefa e assegura que os dados estejam livres de valores anômalos que possam comprometer a análise.
Exercício: Limpeza de Dados
Você recebeu o seguinte conjunto de dados que contém informações sobre funcionários de uma empresa. Sua tarefa é aplicar as técnicas de limpeza de dados para preparar este dataset para análise.
Dataset de Entrada:
import pandas as pd
import numpy as np
# Dados de exemplo com problemas
data = {
'Nome': ['Alice', 'Bruno', 'Carlos', 'Daniela', 'Eduardo', 'Fernanda', 'Bruno', 'Gustavo', 'Heloisa', 'Igor',
'Joana', 'Karina', 'Laura', 'Marcelo', 'Nina', 'Bruno', 'Otavio', 'Paula', 'Quintino', 'Rafaela'],
'Idade': [25, np.nan, 45, -2, 30, 31, 45, 28, np.nan, 26, 40, -1, 23, 36, np.nan, 33, 50, 29, 24, 32],
'Salario': [50000, 62000, 70000, np.nan, 52000, 51000, 62000, 45000, 48000, np.nan, 55000, 57000, 49000,
60000, np.nan, 62000, 73000, 51000, np.nan, 61000],
'Cidade': ['São Paulo', 'Rio de Janeiro', 'São Paulo', 'Rio de Janeiro', 'São Paulo', 'São Paulo',
'Rio de Janeiro', 'Brasília', 'São Paulo', 'São Paulo', 'Rio de Janeiro', 'São Paulo',
'São Paulo', 'Brasília', 'Rio de Janeiro', 'Rio de Janeiro', 'Brasília', 'São Paulo',
'São Paulo', 'Rio de Janeiro']
}
df = pd.DataFrame(data)
print("Dados originais:")
print(df)
Tarefas:
Tratar valores ausentes:
Substituir os valores ausentes na coluna
Idadepela média das idades válidas.Substituir os valores ausentes na coluna
Salariopela mediana dos salários.
Corrigir valores incorretos:
A coluna
Idadecontém valores negativos, o que é incorreto. Substitua esses valores pela média das idades válidas.
Remover duplicatas:
Verifique se há funcionários duplicados com base no nome e remova os registros duplicados, mantendo apenas o primeiro.
Saída esperada:
Dados originais:
Nome Idade Salario Cidade
0 Alice 25.0 50000.0 São Paulo
1 Bruno NaN 62000.0 Rio de Janeiro
2 Carlos 45.0 70000.0 São Paulo
3 Daniela -2.0 NaN Rio de Janeiro
4 Eduardo 30.0 52000.0 São Paulo
5 Fernanda 31.0 51000.0 São Paulo
6 Bruno 45.0 62000.0 Rio de Janeiro
7 Gustavo 28.0 45000.0 Brasília
8 Heloisa NaN 48000.0 São Paulo
9 Igor 26.0 NaN São Paulo
10 Joana 40.0 55000.0 Rio de Janeiro
11 Karina -1.0 57000.0 São Paulo
12 Laura 23.0 49000.0 São Paulo
13 Marcelo 36.0 60000.0 Brasília
14 Nina NaN NaN Rio de Janeiro
15 Bruno 33.0 62000.0 Rio de Janeiro
16 Otavio 50.0 73000.0 Brasília
17 Paula 29.0 51000.0 São Paulo
18 Quintino 24.0 NaN São Paulo
19 Rafaela 32.0 61000.0 Rio de Janeiro
Dados após limpeza (com duplicatas removidas):
Nome Idade Salario Cidade
0 Alice 25.0 50000.0 São Paulo
1 Bruno 33.1 62000.0 Rio de Janeiro
2 Carlos 45.0 70000.0 São Paulo
3 Daniela 33.1 56000.0 Rio de Janeiro
4 Eduardo 30.0 52000.0 São Paulo
5 Fernanda 31.0 51000.0 São Paulo
7 Gustavo 28.0 45000.0 Brasília
8 Heloisa 33.1 48000.0 São Paulo
9 Igor 26.0 56000.0 São Paulo
10 Joana 40.0 55000.0 Rio de Janeiro
11 Karina 33.1 57000.0 São Paulo
12 Laura 23.0 49000.0 São Paulo
13 Marcelo 36.0 60000.0 Brasília
14 Nina 33.1 56000.0 Rio de Janeiro
16 Otavio 50.0 73000.0 Brasília
17 Paula 29.0 51000.0 São Paulo
18 Quintino 24.0 56000.0 São Paulo
19 Rafaela 32.0 61000.0 Rio de Janeiro
Exercício: Análise e Visualização de Dados com o Dataset do UFC no Kaggle#
Este dataset contém dados detalhados sobre lutas do UFC desde 2013, incluindo características dos lutadores, como idade, altura, peso, técnicas usadas e o método de vitória. Cada linha do dataset representa uma luta, onde o lutador posicionado no corner azul (Blue) e o lutador no corner vermelho (Red) competem. As colunas que começam com “B_” referem-se ao lutador do corner azul, e as colunas que começam com “R_” referem-se ao lutador do corner vermelho. Sua tarefa é realizar uma análise completa do dataset, criando visualizações que ajudem a interpretar os dados e, por fim, definir um ranking dos lutadores.
Parte 1: Análise Exploratória e Visualizações
Construa as visualizações solicitadas e escreva uma análise para cada situação descrita a seguir:
Tratamento de Valores Faltantes:
Identifique as colunas com valores faltantes, como idade, altura e peso.
Substitua os valores faltantes pela média ou mediana dessas colunas. Imprima a quantidade de valores faltantes antes da substituição e depois, garantindo que foram devidamente corrigidos.
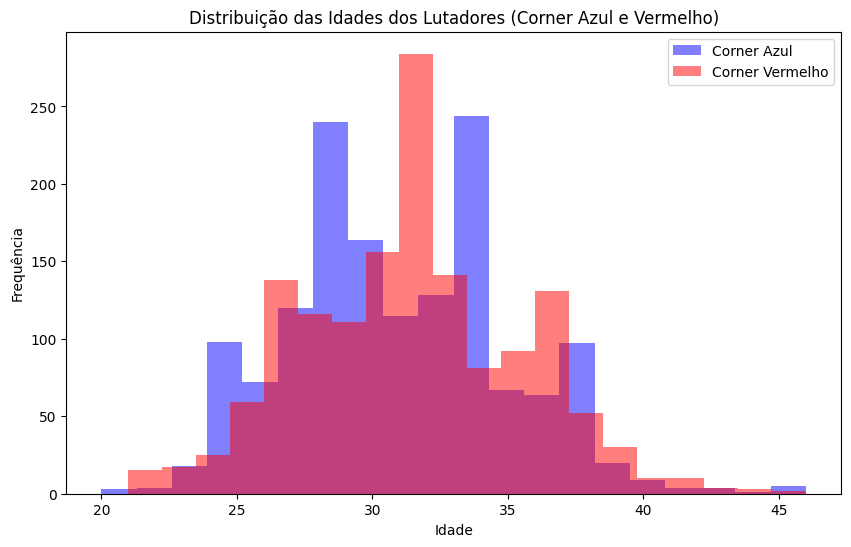
Distribuição de Idades dos Lutadores:
Crie um histograma que mostre a distribuição das idades dos lutadores nos corners vermelho e azul, e comente as tendências observadas.
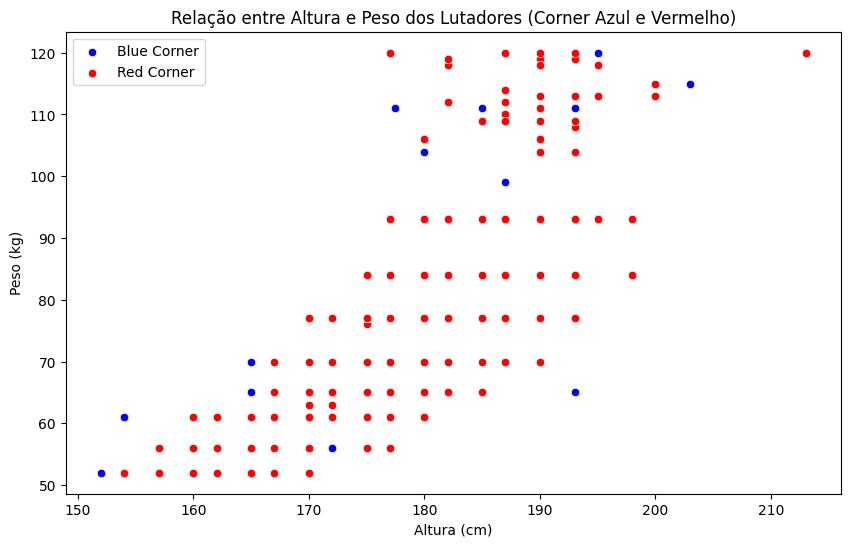
Relação entre Altura e Peso:
Construa um gráfico de dispersão para visualizar a relação entre altura e peso dos lutadores nos corners vermelho e azul.
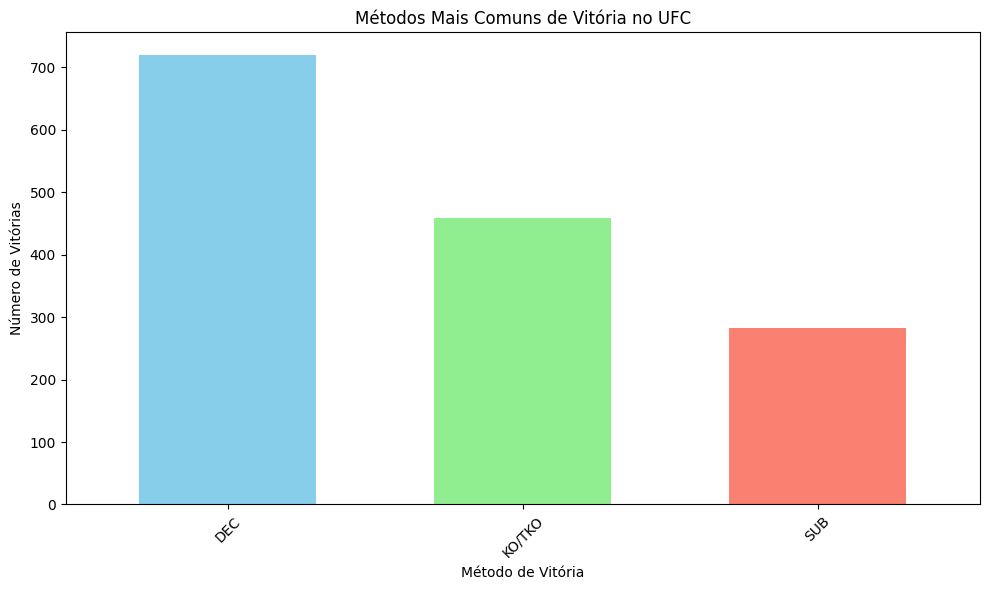
Métodos de Vitória:
Crie um gráfico de barras para mostrar os métodos mais comuns de vitória, tais como: decisão (DEC), nocaute (KO/TKO) e submissão (SUB). Comente sobre os métodos de vitória mais frequentes e o que isso pode indicar sobre o estilo dos lutadores.
Vitórias por Corner:
Crie um gráfico de pizza para mostrar a quantidade de vitórias de lutadores no corner vermelho e no corner azul.
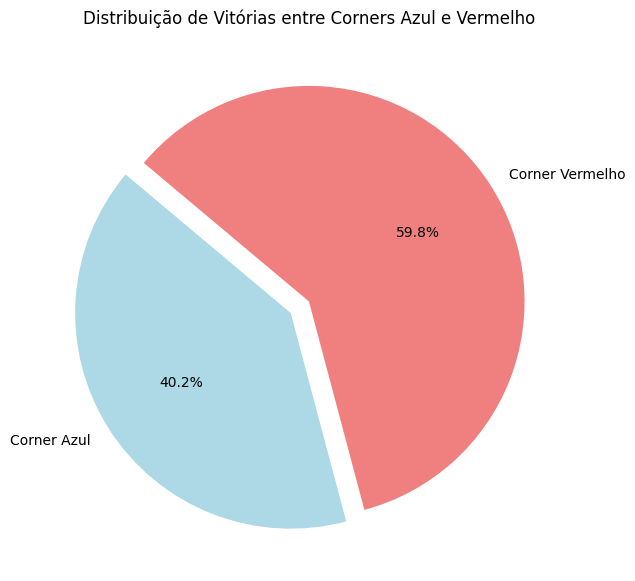
Comente sobre os resultados apresentados, sua importância para análise e conclusões gerais.
Parte 2: Criando um Ranking dos Lutadores
Agora, você deve criar um ranking dos lutadores utilizando a fórmula a seguir, ajustada para usar valores normalizados (entre 0 e 1), garantindo que todas as variáveis contribuam proporcionalmente ao cálculo do ranking:
Onde:
\( V_{norm} \) = Número de vitórias (normalizado)
\( K_{norm} \) = Vitórias por nocaute (normalizado)
\( S_{norm} \) = Vitórias por submissão (normalizado)
\( W_V = 0.5 \), \( W_K = 0.3 \), \( W_S = 0.2 \) = Pesos que determinam a importância de cada variável no ranking.
Tarefas:
Normalizar os valores de vitórias, vitórias por nocaute e vitórias por submissão.
Implementar a fórmula do ranking usando os dados do dataset, ajustando os pesos conforme já definidos:
\( W_V = 0.5 \) (Peso para vitórias)
\( W_K = 0.3 \) (Peso para vitórias por nocaute)
\( W_S = 0.2 \) (Peso para vitórias por submissão)
Listar os 10 melhores lutadores de acordo com o ranking gerado.
Vídeos#
Youtube Playlist uma lista de vídeos selecionados pelo professor.
Sites Importantes#
NumPy é uma biblioteca fundamental para computação numérica em Python.
SciPy é uma biblioteca que fornece módulos para otimização, integração, interpolação, álgebra linear, estatística e muito mais.
Scikit-learn é uma biblioteca de Machine Learning que fornece ferramentas simples e eficientes para análise de dados e modelagem.
Matplotlib é uma biblioteca de plotagem que fornece uma interface orientada a objetos para incorporar gráficos em aplicações.
Pandas é uma biblioteca que fornece estruturas de dados e operações de manipulação de dados de alto desempenho.
para desenhar gráficos estatísticos atraentes e informativos. Seaborn é uma biblioteca de visualização de dados baseada em Matplotlib que fornece uma interface de alto nível
TensorFlow é uma biblioteca de código aberto para aprendizado de máquina desenvolvida pela Google.
Keras é uma API de alto nível para construir e treinar modelos de aprendizado profundo. Ele pode ser executado em cima do TensorFlow, CNTK ou Theano.
PyTorch é uma biblioteca de aprendizado profundo desenvolvida pelo Facebook.
Plotly é uma biblioteca de visualização de dados que permite criar gráficos interativos e publicá-los na web.
Referências#
Aston Zhang, Zachary C. Lipton, Mu Li, and Alexander J. Smola. Dive into Deep Learning. Cambridge University Press, 2023. https://D2L.ai.