Capítulo 3: Deep Learning#

Redes Neurais Artificiais#
As Redes Neurais Artificiais (ANNs) são sistemas computacionais inspirados na estrutura e no funcionamento dos neurônios biológicos do cérebro humano. Elas são compostas por unidades de processamento, chamadas neurônios artificiais ou nós, organizados em camadas e conectados por pesos ajustáveis []. A seguir, exploramos os componentes e o funcionamento das redes neurais no contexto matemático.
O Neurônio Artificial: A Base das Redes Neurais#
Um conceito central no aprendizado de máquina, especialmente no aprendizado profundo, é o neurônio artificial. Inspirado nos neurônios biológicos, ele atua como uma função matemática que processa informações. O neurônio artificial recebe uma ou mais entradas, cada uma multiplicada por um peso que reflete sua importância. Em seguida, essas entradas ponderadas são somadas. O resultado passa por uma função de ativação, que determina a saída final do neurônio [].
As redes neurais, como as utilizadas em aprendizado profundo, são compostas por camadas interconectadas de neurônios artificiais. Essas camadas trabalham em conjunto para processar dados complexos e identificar padrões nos dados. Essa arquitetura em camadas permite que as redes neurais modelem relações complexas, executando tarefas sofisticadas e contribuindo para avanços em áreas como visão computacional, processamento de linguagem natural e robótica.
Estrutura Matemática de um Neurônio Artificial#
Um neurônio artificial é uma unidade de processamento que realiza uma operação matemática simples, mas essencial. Ele pode ser representado pela seguinte equação:
\( y = f\left(\sum_{i=1}^{n} w_i x_i + b\right) \)
onde:
\( x_i \): são as entradas do neurônio, representando os dados de entrada.
\( w_i \): são os pesos associados a cada entrada, responsáveis por determinar a relevância de cada entrada.
\( b \): é o bias, um termo adicional que ajusta a saída do neurônio, permitindo maior flexibilidade no modelo, especialmente quando todas as entradas são zero.
\( \sum_{i=1}^{n} w_i x_i \): é a soma ponderada das entradas, que combina as entradas com seus respectivos pesos.
\( f \): é a função de ativação, que introduz não-linearidade na saída, permitindo que a rede neural modele relações mais complexas nos dados.
\( y \): é a saída final do neurônio, resultado do processamento das entradas.
Exemplo de um Neurônio Artificial
Essa imagem permite visualizar a modelagem de todas as partes de um neurônio artificial utilizadas nas redes neurais artificiais.
{kind=link}
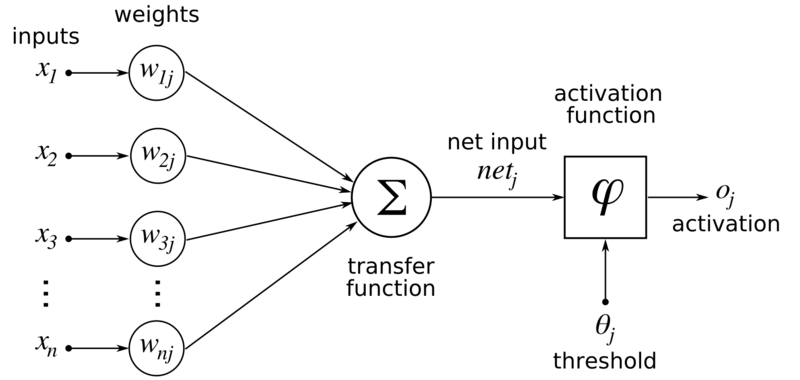
Pesos e Conexões#
Os pesos \( w_i \) são parâmetros ajustáveis que conectam os neurônios entre diferentes camadas de uma rede neural. Eles representam a força de influência de uma entrada no neurônio subsequente e são ajustados durante o processo de treinamento da rede. Durante o treinamento, os pesos são modificados para minimizar o erro na saída da rede, permitindo que ela se torne mais precisa na realização de suas tarefas.
Funções de Ativação#
As funções de ativação introduzem não-linearidade nas redes neurais, o que é fundamental para que essas redes possam aprender e modelar relações complexas nos dados. Sem essa não-linearidade, as redes seriam equivalentes a uma simples combinação linear, limitando sua capacidade de resolver problemas sofisticados. Algumas das funções de ativação mais comuns são:
Sigmoid: \( \sigma(x) = \frac{1}{1 + e^{-x}} \)
A função sigmoid comprime a saída para um valor entre 0 e 1, sendo útil em classificações binárias.ReLU (Rectified Linear Unit): \( \text{ReLU}(x) = \max(0, x) \)
A ReLU é amplamente usada em redes neurais profundas devido à sua simplicidade e eficiência computacional. Ela retorna 0 para valores negativos e o próprio valor para positivos, ajudando a evitar o problema de gradientes que desaparecem.Tanh (Tangente Hiperbólica): \( \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} \)
A função Tanh mapeia a saída para um intervalo entre -1 e 1, oferecendo uma curva de transição mais suave em comparação com a sigmoid, o que pode ser vantajoso em algumas situações.
Implementação das Funções de Ativação#
O código a seguir implementa as três funções de ativação mencionadas e exibe seus gráficos:
import numpy as np
import matplotlib.pyplot as plt
# Define as funções de ativação
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def relu(x):
return np.maximum(0, x)
def tanh(x):
return (np.exp(x) - np.exp(-x)) / (np.exp(x) + np.exp(-x))
# Cria um intervalo de valores para o eixo x
x = np.linspace(-5, 5, 100)
# Calcula os valores das funções de ativação
y_sigmoid = sigmoid(x)
y_relu = relu(x)
y_tanh = tanh(x)
# Plota os gráficos
plt.figure(figsize=(15, 4)) # Ajusta o tamanho da figura para 3 subplots lado a lado
plt.subplot(1, 3, 1) # Cria 1 linha e 3 colunas, subplot 1
plt.plot(x, y_sigmoid, label='Sigmoid')
plt.title('Sigmoid')
plt.xlabel('x')
plt.ylabel('σ(x)')
plt.legend()
plt.subplot(1, 3, 2) # Cria 1 linha e 3 colunas, subplot 2
plt.plot(x, y_relu, label='ReLU')
plt.title('ReLU')
plt.xlabel('x')
plt.ylabel('ReLU(x)')
plt.legend()
plt.subplot(1, 3, 3) # Cria 1 linha e 3 colunas, subplot 3
plt.plot(x, y_tanh, label='Tanh')
plt.title('Tanh')
plt.xlabel('x')
plt.ylabel('tanh(x)')
plt.legend()
plt.tight_layout()
plt.show()
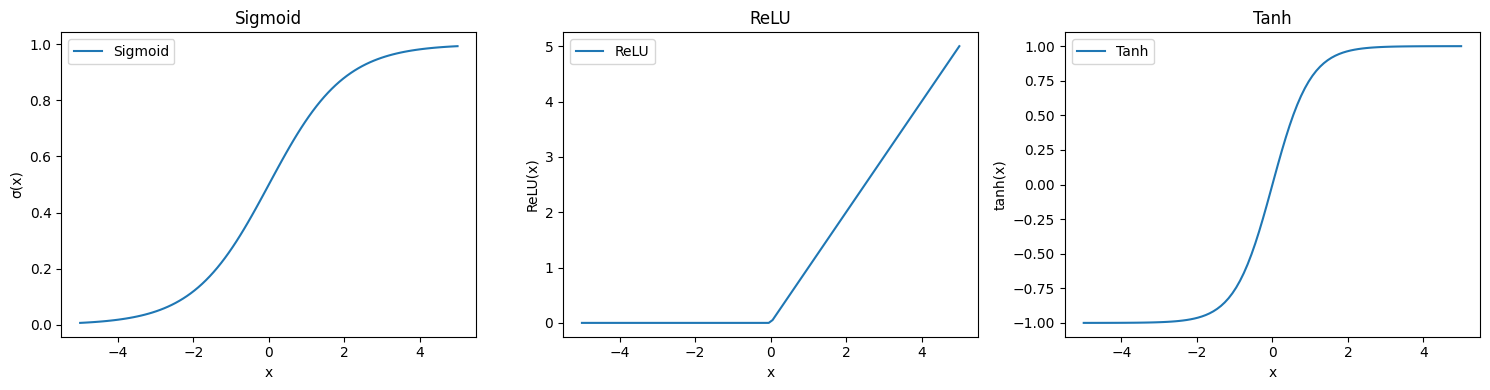
Esse código implementa e visualiza três das funções de ativação mais comuns: Sigmoid, ReLU e Tanh. As funções de ativação são essenciais para o aprendizado eficaz das redes neurais, permitindo que os modelos capturem padrões não triviais e realizem tarefas complexas com eficiência.
Neurônio em Python#
import numpy as np
# Definição do neurônio artificial
def neuron(entrada, pesos, bias, func_ativacao):
# Calcula a soma ponderada das entradas mais o bias
soma_pesos = np.dot(entrada, pesos) + bias
# Aplica a função de ativação
saida = func_ativacao(soma_pesos)
return saida
# Definição da função de ativação
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# Entradas, pesos e bias
entrada = np.array([1, 2, 3]) # Entradas do neurônio
pesos = np.array([0.1, 0.2, 0.3]) # Pesos associados às entradas
bias = 0.4
# Calcula a saída do neurônio com a função de ativação sigmoid
saida_prevista = neuron(entrada, pesos, bias, sigmoid)
# Exibe o resultado previsto
print(f'Saída do Neurônio: {saida_prevista:.4f}')
A função
neuronrecebe as entradas, pesos, o bias, e uma função de ativação. Ela calcula a soma ponderada das entradas e aplica a função de ativação para gerar a saída prevista.A função
sigmoidé usada como a função de ativação.O código de exemplo define as entradas, pesos e bias, e calcula a saída prevista do neurônio, que é exibida ao final.
Saída do Código:
Saída Prevista do Neurônio: 0.8581
Função de Custo (Erro Quadrático para um Neurônio)#
Quando tratamos de um neurônio individual, a função de custo (ou função de perda) mede o erro entre a saída prevista por esse neurônio e o valor real esperado (alvo). A fórmula mais simples para calcular o erro quadrático é:
onde:
\(y_{\text{previsto}}\) é a saída prevista pelo neurônio.
\(y_{\text{real}}\) é o valor esperado (ou alvo).
O resultado é o erro quadrático, que é a diferença ao quadrado entre a previsão e o valor real.
Exemplo Numérico de Erro Quadrático:
Suponha que:
A saída prevista pelo neurônio (\(y_{\text{previsto}}\)) seja 0.7.
O valor real esperado (\(y_{\text{real}}\)) seja 1.
O erro quadrático pode ser calculado da seguinte forma:
Ou seja, o erro quadrático para este exemplo é 0.09. Esse valor quantifica o quanto a previsão do neurônio se desvia do valor esperado.
Visualização Gráfica do Erro Quadrático
A seguir, vamos gerar um gráfico que ilustra a curva da função de erro quadrático, variando a saída prevista (\(y_{\text{previsto}}\)) e fixando o valor real (\(y_{\text{real}} = 1\)). No gráfico, também vamos destacar o ponto onde a saída prevista é 0.7 e o erro correspondente é 0.09.
import numpy as np
import matplotlib.pyplot as plt
# Função de erro quadrático
def erro_quadratico(y_real, y_previsto):
return (y_real - y_previsto) ** 2
# Valores de y_previsto para o gráfico
y_previsto = np.linspace(0, 2, 100)
y_real = 1 # Valor real fixo
# Calcula o erro quadrático para cada valor de y_previsto
erro = erro_quadratico(y_real, y_previsto)
# Valor previsto específico para visualização do erro
y_previsto_especifico = 0.7
erro_especifico = erro_quadratico(y_real, y_previsto_especifico)
# Criação do gráfico
plt.figure(figsize=(8, 6))
plt.plot(y_previsto, erro, label='$L(y_{previsto}, y_{real}) = (y_{previsto} - y_{real})^2$', color='blue')
plt.axvline(x=y_real, color='red', linestyle='--', label='$y_{real} = 1$', linewidth=2)
plt.scatter(y_previsto_especifico, erro_especifico, color='green', zorder=5)
plt.text(y_previsto_especifico, erro_especifico + 0.01, f'($y_{{previsto}} = {y_previsto_especifico}, Erro = {erro_especifico:.2f}$)', fontsize=12)
# Adicionando título e rótulos
plt.title('Função de Erro Quadrático', fontsize=14)
plt.xlabel('Saída Prevista ($y_{previsto}$)', fontsize=12)
plt.ylabel('Erro Quadrático', fontsize=12)
# Exibindo a legenda
plt.legend(fontsize=12)
# Exibindo o gráfico
plt.grid(True)
plt.show()
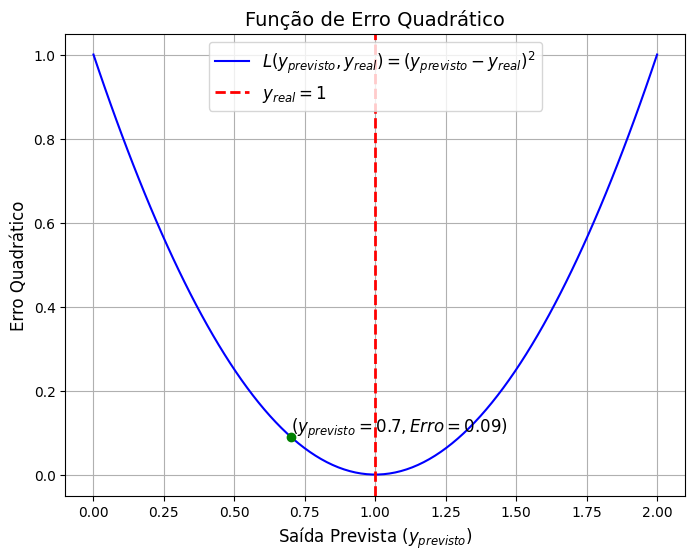
Função
erro_quadratico: Calcula o erro quadrático dado um valor real (\(y_{\text{real}}\)) e uma saída prevista (\(y_{\text{previsto}}\)).Gráfico: A curva azul mostra como o erro quadrático varia em função da saída prevista. A linha vermelha pontilhada indica o valor real (\(y_{\text{real}} = 1\)), onde o erro é mínimo.
Ponto Verde: O ponto verde representa o exemplo numérico específico, onde a saída prevista é 0.7 e o erro quadrático é 0.09.
O gráfico mostra como o erro quadrático aumenta à medida que a previsão (\(y_{\text{previsto}}\)) se distancia do valor real (\(y_{\text{real}} = 1\)). O objetivo do treinamento é minimizar esse erro ajustando os pesos do neurônio.
Cálculo do Erro no Neurônio
Agora, vamos inserir essa ideia no código Python para calcular o erro quadrático em um neurônio individual:
import numpy as np
# Definição do neurônio artificial
def neuron(entrada, pesos, bias, func_ativacao):
# Calcula a soma ponderada das entradas mais o bias
soma_pesos = np.dot(entrada, pesos) + bias
# Aplica a função de ativação
saida = func_ativacao(soma_pesos)
return saida
# Definição da função de ativação Sigmoid
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# Definição da função de custo - Erro Quadrático para um neurônio
def erro_quadratico(y_real, y_previsto):
return (y_real - y_previsto) ** 2
# Entradas, pesos, bias e valor real esperado
entrada = np.array([1, 2, 3]) # Entradas do neurônio
pesos = np.array([0.1, 0.2, 0.3]) # Pesos associados às entradas
bias = 0.4
y_real = 1 # Valor real esperado (alvo)
# Calcula a saída do neurônio
y_previsto = neuron(entrada, pesos, bias, sigmoid)
# Calcula o erro quadrático
erro = erro_quadratico(y_real, y_previsto)
# Exibe o resultado
print(f'Saída do Neurônio: {y_previsto:.4f}')
print(f'Erro Quadrático: {erro:.4f}')
Saída Esperada:
Saída do Neurônio: 0.8581
Erro Quadrático: 0.0201
Neste exemplo, o neurônio calculou uma saída prevista de 0.8581. Como o valor esperado era 1, o erro quadrático resultante foi de 0.0201, o que indica o desvio entre a previsão e o valor real.
O gráfico da função de erro quadrático ajuda a entender como o erro varia à medida que as previsões se aproximam ou se distanciam do valor esperado. O treinamento de redes neurais busca minimizar essa função, ajustando os pesos do neurônio até que as previsões fiquem o mais próximas possíveis dos valores reais.
Exercício: Cálculo do Erro do Neurônio com Diferentes Funções de Ativação#
Neste exercício, você deverá implementar um neurônio que calcule a saída prevista utilizando quatro funções de ativação diferentes: Tangente Hiperbólica (tanh), ReLU, Leaky ReLU e Sigmoide. Depois, será necessário calcular o erro quadrático em relação ao valor real esperado para cada uma dessas funções.
Além disso, antes de alimentar o neurônio, os dados de entrada serão normalizados para garantir que todos os valores estejam dentro da mesma escala, o que é uma prática comum no treinamento de redes neurais.
Função de Custo (Erro Quadrático)
A função de custo utilizada será o erro quadrático, que mede a diferença entre a saída prevista pelo neurônio e o valor real esperado. A fórmula é:
Onde:
\(y_{\text{previsto}}\) é a saída prevista pelo neurônio.
\(y_{\text{real}}\) é o valor esperado (ou alvo).
Funções de Ativação
Tangente Hiperbólica (tanh): \( \text{tanh}(x) = \frac{2}{1 + e^{-2x}} - 1 \)
ReLU (Rectified Linear Unit): \( \text{ReLU}(x) = \max(0, x) \)
Leaky ReLU: \( \text{Leaky ReLU}(x) = \begin{cases} x & \text{se } x \geq 0 \\ 0.01x & \text{se } x < 0 \end{cases} \)
Sigmoide: \( \text{Sigmoide}(x) = \frac{1}{1 + e^{-x}} \)
Normalização dos Dados de Entrada
Para que o neurônio funcione de maneira mais eficiente, os dados de entrada serão normalizados para ficarem dentro de uma escala padrão. A normalização será feita utilizando a seguinte fórmula:
onde \(x\) representa os valores da entrada original e \(x_{\text{norm}}\) os valores normalizados.
Implementação do Neurônio
Implemente um neurônio que utilize um vetor de entrada de tamanho 20x20 (ou seja, 400 elementos). A entrada será um vetor de valores inteiros de 1 a 400, que deve ser normalizado antes de ser alimentado ao neurônio. Use os seguintes parâmetros fixos para garantir que todos os alunos obtenham o mesmo resultado:
Entrada: vetor de 400 elementos com valores inteiros de 1 a 400, normalizados.
Pesos: vetor de 400 elementos, todos definidos como 0.05.
Bias: valor fixo de 1.2.
Valor Real Esperado (alvo): 2.0.
Perguntas:
Qual função de ativação resultou no menor erro quadrático?
Como a normalização dos dados afeta o desempenho do neurônio?
Qual a influência de cada função de ativação no cálculo do erro do neurônio?
Como essas diferenças no erro podem impactar o processo de treinamento de redes neurais?
Introdução à Regressão Linear e Redes Neurais#
A regressão linear é uma das técnicas mais simples e amplamente utilizadas em aprendizado de máquina. Ela visa modelar a relação entre uma variável dependente (resposta ou alvo) e uma ou mais variáveis independentes (preditores ou características), ajustando uma linha reta aos dados. Sua simplicidade a torna um excelente ponto de partida para entender conceitos fundamentais de aprendizado de máquina e preparar o terreno para abordagens mais complexas, como redes neurais.
Aplicações da Regressão Linear#
A regressão linear é amplamente utilizada em diversas áreas, com aplicações que vão desde previsões simples até modelagem financeira. Alguns exemplos incluem:
Previsão de preços: Estimar o valor de uma casa com base em características como tamanho, localização e número de quartos.
Análise financeira: Modelar a relação entre variáveis financeiras, como prever o preço de uma ação com base em fatores econômicos.
Modelagem de tendências: Prever tendências de vendas ou crescimento populacional com base em dados históricos.
Apesar de sua simplicidade e eficácia em problemas que seguem uma relação linear, muitas vezes as variáveis possuem relações não lineares, que não podem ser representadas adequadamente por uma linha reta. Para lidar com esses casos, técnicas mais avançadas, como redes neurais, são utilizadas. Redes neurais têm a capacidade de aprender padrões complexos e não lineares, permitindo a modelagem de problemas mais sofisticados.
Fórmula Geral da Regressão Linear Simples#
Na regressão linear simples, temos a seguinte fórmula:
onde:
\(y_{\text{previsto}}\) é a variável dependente ou alvo (o valor que queremos prever).
\(x\) é a variável independente ou preditor (o valor de entrada).
\(a\) é o peso, também conhecido como coeficiente angular, que define a inclinação da linha. O coeficiente angular \(a\) pode ser calculado pela razão entre a variação de \(y\) e a variação de \(x\), ou seja:
Este valor indica o quanto a variável dependente \(y\) varia para cada mudança de uma unidade em \(x\). Se \(a\) for positivo, a linha sobe conforme \(x\) aumenta. Se for negativo, a linha desce.
\(b\) é o intercepto (ou bias), que determina onde a linha cruza o eixo Y (o valor de \(y\) quando \(x = 0\)).
O objetivo da regressão linear é ajustar os parâmetros \(a\) e \(b\) de modo que a linha resultante minimize a diferença entre as previsões \(y_{\text{previsto}}\) e os valores reais \(y_{\text{real}}\). Essa diferença é quantificada por uma função de erro.
Visualizando Retas com Diferentes Inclinações e Interceptos#
Aqui está um código que ilustra três retas com diferentes inclinações e interceptos, ajudando a visualizar a equação da reta:
import numpy as np
import matplotlib.pyplot as plt
# Definindo os valores de inclinação (a) e intercepto (b) para cada reta
params = [
{"a": 0.5, "b": 1}, # Inclinação 0.5, Intercepto 1
{"a": 2, "b": -3}, # Inclinação 2, Intercepto -3
{"a": -1, "b": 4} # Inclinação -1, Intercepto 4
]
# Gerando valores de x (variável independente)
x = np.linspace(-10, 10, 100)
# Criando o gráfico para as três retas
plt.figure(figsize=(8, 6))
for param in params:
a = param["a"]
b = param["b"]
y = a * x + b # Calculando y com base na equação da reta: y = a*x + b
plt.plot(x, y, label=f'y = {a}x + {b}', linewidth=2)
# Destacando o intercepto no gráfico
plt.scatter(0, b, color='blue', zorder=5)
plt.text(0, b + 0.5, f'Intercepto = {b}', color='blue')
# Adicionando grades, título e legendas explicativas
plt.title('Três Retas com Diferentes Inclinações e Interceptos')
plt.xlabel('Variável Independente (x)')
plt.ylabel('Variável Dependente (y)')
plt.axhline(0, color='black', linewidth=0.5) # Linha horizontal no eixo Y
plt.axvline(0, color='black', linewidth=0.5) # Linha vertical no eixo X
plt.grid(True) # Adicionando grid para facilitar a leitura
plt.legend()
# Exibindo o gráfico
plt.show()
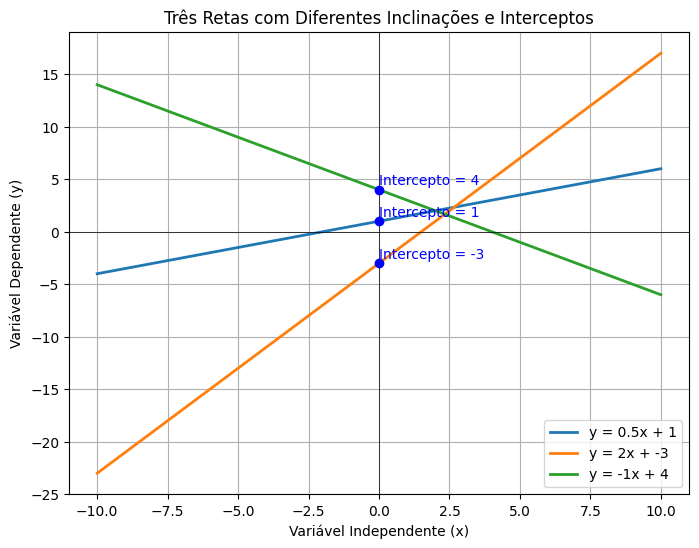
Neste gráfico:
Cada reta tem uma inclinação e um intercepto distintos.
A equação de cada reta está indicada na legenda, no formato
y = ax + b, para facilitar a compreensão de como a inclinação e o intercepto afetam a posição e o ângulo da reta.
A Relação entre a Regressão Linear e um Neurônio#
A equação da regressão linear se assemelha muito à equação que define o funcionamento de um neurônio em uma rede neural. No caso de um neurônio, temos:
onde:
\(y_{\text{neurônio}}\) é a saída do neurônio.
\(x\) é o valor de entrada.
\(w\) é o peso, que funciona de forma semelhante à inclinação \(a\) na regressão linear, indicando a importância de \(x\) na saída \(y_{\text{neurônio}}\).
\(b\) é o bias, que ajusta a saída do neurônio, assim como o intercepto na regressão linear.
Essa equação é idêntica à da regressão linear. A diferença no neurônio é que, após calcular o valor \(y_{\text{neurônio}}\), a saída passa por uma função de ativação, que transforma a saída linear em uma não-linear. Assim, a equação completa de um neurônio seria:
onde \(\sigma\) representa a função de ativação, como a função sigmoide, tangente hiperbólica, ou ReLU, que adiciona não-linearidade ao modelo, permitindo que a rede neural aprenda relações mais complexas.
Agora, para exemplificar a aplicação da regressão linear, veja um código que gera uma distribuição de pontos e ajusta uma linha de regressão a esses dados:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# Gerando dados de exemplo (distribuição de pontos)
np.random.seed(0)
x = 2 * np.random.rand(100, 1)
y = 4 + 3 * x + np.random.randn(100, 1) # Linha com alguma variação aleatória
# Ajustando o modelo de regressão linear
lin_reg = LinearRegression()
lin_reg.fit(x, y)
y_pred = lin_reg.predict(x)
# Plotando a distribuição de pontos e a linha de regressão
plt.scatter(x, y, color='blue', label='Pontos de Dados')
plt.plot(x, y_pred, color='red', linewidth=2, label='Linha de Regressão')
plt.title('Distribuição de Pontos e Regressão Linear')
plt.xlabel('Variável Independente (x)')
plt.ylabel('Variável Dependente (y)')
plt.legend()
plt.show()

Neste gráfico:
Pontos de Dados: Os pontos azuis representam a distribuição dos dados observados.
Linha de Regressão: A linha vermelha é a linha de regressão ajustada pelo modelo, que tenta capturar a relação linear entre
xey.
Redes Neurais e Regressão Linear: Uma Conexão Essencial#
As redes neurais podem ser vistas como uma generalização da regressão linear. No caso mais simples, um neurônio individual em uma rede neural funciona de forma semelhante à regressão linear, onde temos uma combinação linear de entradas, ponderada pelos pesos (\(w\)) e ajustada por um bias (\(b\)).
A principal diferença entre a regressão linear e as redes neurais é que, nas redes neurais, podemos ter múltiplos neurônios organizados em várias camadas e podemos aplicar funções de ativação não lineares. Isso permite que o modelo aprenda relações mais complexas e não lineares nos dados, o que é importante para a resolução de problemas como reconhecimento de imagens, análise de texto e previsão de séries temporais.
Contudo, tanto na regressão linear quanto nas redes neurais, o objetivo é ajustar os pesos (\(w\)) e o bias (\(b\)) para minimizar o erro entre as previsões e os valores reais. Este ajuste é feito utilizando o algoritmo de backpropagation (retropropagação do erro), que permite atualizar os pesos de forma eficiente.
Vamos resolver o problema da regressão linear utilizando um neurônio artificial e o algoritmo de backpropagation.
Minimização do Erro com Backpropagation#
O backpropagation é um método para ajustar os pesos e o bias de um neurônio (ou de uma rede neural inteira) de maneira a minimizar o erro entre a saída prevista e a saída real. Para entender como isso funciona, vamos utilizar o exemplo de uma regressão linear simples.
Gradiente Descendente e Cálculo das Derivadas Parciais#
Para ajustar os parâmetros (\(w\) e \(b\)) e minimizar o erro, precisamos calcular os gradientes (derivadas parciais) da função de custo em relação a cada um desses parâmetros.
A função de custo que estamos utilizando é o erro quadrático:
onde:
\(y_{\text{previsto}}\) é a saída prevista pelo modelo, ou seja, \(y_{\text{previsto}} = w \cdot x + b\)
\(y_{\text{real}}\) é o valor real ou alvo.
Agora, vamos calcular as derivadas parciais de \(L\) em relação a \(w\) e \(b\).
Derivada Parcial de \(L\) em relação ao Peso (\(w\))#
Primeiro, reescrevemos a função de custo \(L\) em termos de \(w\):
Sabemos que:
Logo, podemos reescrever \(L\) como:
Agora, aplicamos a regra da cadeia para calcular a derivada de \(L\) em relação a \(w\).
Primeiro, derivamos \(L\) em relação à expressão \((y_{\text{previsto}} - y_{\text{real}})\):
Em seguida, derivamos \(y_{\text{previsto}} = w \cdot x + b\) em relação a \(w\):
Agora, multiplicamos esses dois resultados:
Esse é o gradiente do peso (\(w\)).
Derivada Parcial de \(L\) em relação ao Bias (\(b\))#
Agora, vamos calcular a derivada de \(L\) em relação ao bias \(b\). Começamos reescrevendo \(L\):
Novamente, aplicamos a regra da cadeia. Primeiro, derivamos \(L\) em relação à expressão \((y_{\text{previsto}} - y_{\text{real}})\):
Agora, derivamos \(y_{\text{previsto}} = w \cdot x + b\) em relação a \(b\):
Multiplicando os dois resultados, obtemos:
Esse é o gradiente do bias (\(b\)).
Atualização dos Parâmetros#
Agora que temos as derivadas parciais da função de custo em relação a \(w\) e \(b\), podemos atualizar os parâmetros utilizando a regra de atualização do gradiente descendente:
Atualização do peso (\(w\)): \( w_{\text{novo}} = w_{\text{antigo}} - \eta \cdot \frac{\partial L}{\partial w} \)
Atualização do bias (\(b\)): \( b_{\text{novo}} = b_{\text{antigo}} - \eta \cdot \frac{\partial L}{\partial b} \)
Onde \(\eta\) é a taxa de aprendizado, que controla o tamanho das atualizações nos parâmetros.
Exemplo Prático: Regressão Linear com Backpropagation
A seguir, implementamos um exemplo em Python que ilustra o processo de backpropagation em uma regressão linear simples.
import numpy as np
import matplotlib.pyplot as plt
# Gerando dados de exemplo (nuvem de pontos)
np.random.seed(0)
x = 2 * np.random.rand(100, 1)
y_real = 4 + 3 * x + np.random.randn(100, 1) # Linha com algum ruído
# Inicializa pesos e bias
w = np.random.randn(1) # Peso inicial aleatório
b = np.random.randn(1) # Bias inicial aleatório
# Definição da taxa de aprendizado
eta = 0.01 # Taxa de aprendizado
# Função para calcular a previsão
def predict(x, w, b):
return w * x + b #y_pred
# Função para calcular o erro quadrático
def loss(y_real, y_pred):
return np.mean((y_real - y_pred) ** 2)
# Função para realizar uma iteração de backpropagation
def backpropagation(x, y_real, w, b, eta):
# Forward pass: cálculo da previsão
y_pred = predict(x, w, b)
# Cálculo do erro quadrático
erro = loss(y_real, y_pred)
# Gradientes em relação a w e b
grad_w = -2 * np.mean((y_real - y_pred) * x)
grad_b = -2 * np.mean(y_real - y_pred)
# Atualizando os parâmetros
w -= eta * grad_w
b -= eta * grad_b
return w, b, erro
# Calculando a reta antes de ajustar os parâmetros
y_pred_inicial = predict(x, w, b)
# Executando múltiplas iterações para ajustar os parâmetros
num_iteracoes = 100
erros = []
for i in range(num_iteracoes):
w, b, erro = backpropagation(x, y_real, w, b, eta)
erros.append(erro)
# Calculando a reta ajustada
y_pred_final = predict(x, w, b)
# Plotando as retas antes e depois do ajuste
plt.figure(figsize=(10, 6))
plt.subplot(1, 2, 1)
plt.scatter(x, y_real, color='blue', label='Pontos de Dados')
plt.plot([np.min(x), np.max(x)], [np.min(y_pred_inicial), np.max(y_pred_inicial)], color='orange', label='Reta Inicial')
plt.plot([np.min(x), np.max(x)], [np.min(y_pred_final), np.max(y_pred_final)], color='red', label='Reta Ajustada')
plt.xlabel('x')
plt.ylabel('y')
plt.title('Reta Inicial vs Reta Ajustada')
plt.legend()
# Plotando o erro ao longo das iterações
plt.subplot(1, 2, 2)
plt.plot(range(num_iteracoes), erros, color='purple')
plt.xlabel('Iterações')
plt.ylabel('Erro Quadrático')
plt.title('Redução do Erro com Backpropagation')
plt.tight_layout()
plt.show()
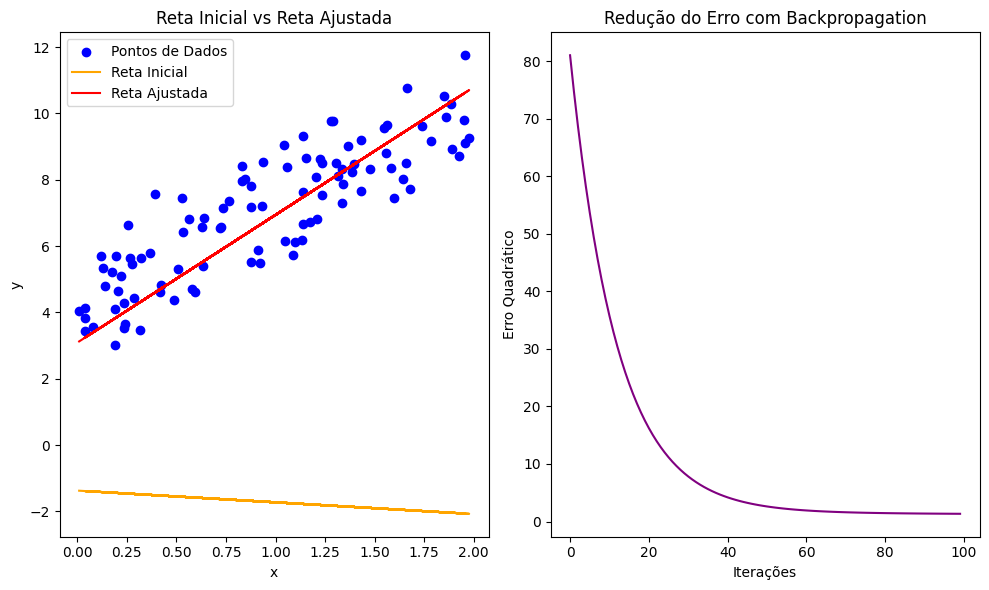
Este exemplo de regressão linear é uma forma simples de visualizar o funcionamento do backpropagation, onde ajustamos os pesos e o bias de um único neurônio para minimizar o erro. O mesmo princípio pode ser aplicado a redes neurais maiores e mais complexas, permitindo que o modelo aprenda relações não lineares e resolva problemas complexos de forma eficiente.
A partir desta base, podemos expandir o conceito para redes neurais com múltiplas camadas e neurônios, onde o backpropagation é utilizado para otimizar todos os parâmetros da rede, tornando-se uma ferramenta fundamental para o sucesso do treinamento em redes neurais profundas.
Exercício: Ajuste de Regressão Linear com Backpropagation#
Neste exercício, você implementará uma regressão linear simples utilizando backpropagation para ajustar os parâmetros da reta. O objetivo é encontrar a quantidade de iterações necessárias para atingir um erro mínimo desejado, variando a taxa de aprendizado. O exercício explora como diferentes valores de taxa de aprendizado afetam o número de iterações e a convergência do modelo.
Objetivos do Exercício:
Implementar o gradiente descendente e backpropagation para ajustar os coeficientes da reta.
Definir um erro mínimo (por exemplo, 0.001) que o modelo deve atingir.
Utilizar três taxas de aprendizado (exemplo: 0.001, 0.01, 0.1) e verificar quantas iterações são necessárias para alcançar o erro mínimo com cada uma delas.
Dados Fornecidos: Aqui estão os dados necessários para iniciar o exercício:
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
# Configuração de seeds para reprodutibilidade
np.random.seed(42)
tf.random.set_seed(42)
# Gerando dados de área e preço de aluguel
X = 30 + 120 * np.random.rand(100, 1) # Áreas entre 30m² e 150m²
y = 1500 + 50 * X + np.random.randn(100, 1) * 250 # Preço base + preço por m² + variação
# Construindo o modelo de regressão linear
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(1,)),
tf.keras.layers.Dense(units=1)
])
# Compilação com Adam para melhor convergência
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), loss='mean_squared_error')
# Treinamento do modelo
history = model.fit(X, y, epochs=2500, verbose=0)
# Previsões para visualização da linha de regressão
X_range = np.linspace(30, 150, 100).reshape(-1, 1)
y_pred = model.predict(X_range)
# Coeficientes do modelo
weights, bias = model.layers[0].get_weights()
print(f"weights: {weights[0][0]:.2f}")
print(f"bias: {bias[0]:.2f}")
# Visualização do modelo e dados
plt.figure(figsize=(10, 6))
plt.scatter(X, y, color='blue', alpha=0.5, label='Dados reais')
plt.plot(X_range, y_pred, color='red', label='Modelo de precificação')
plt.xlabel("Área do imóvel (m²)")
plt.ylabel("Valor do Aluguel (R$)")
plt.title("Relação entre Área e Valor do Aluguel")
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# Visualizando o histórico de perda
plt.figure(figsize=(10, 6))
plt.plot(history.history['loss'], color='purple')
plt.xlabel("Épocas")
plt.ylabel("Erro Quadrado Médio (MSE)")
plt.title("Convergência do Treinamento")
plt.grid(True, alpha=0.3)
plt.show()
Tarefa:
Complete o código para implementar o gradiente descendente com backpropagation.
Teste o código com três diferentes taxas de aprendizado: 0.001, 0.01 e 0.1.
Verifique o número de iterações necessárias para atingir o erro mínimo para cada uma das taxas de aprendizado.
Plotar os resultados: a reta inicial e a reta ajustada após o treinamento, além da evolução do erro ao longo das iterações.
Resultados Esperados: Você deverá observar como diferentes taxas de aprendizado influenciam a velocidade de convergência e quantas iterações são necessárias para atingir o erro mínimo.
Regressão Linear com TensorFlow#
Exemplo Aplicado ao Mercado Imobiliário
No mercado imobiliário brasileiro, o preço do aluguel costuma estar correlacionado com o tamanho do imóvel. Neste exemplo, vamos construir um modelo de regressão linear para estimar o valor do aluguel com base na área do apartamento.
Considerações para a Análise:
Imóveis variam de 30 m² (kitnets e studios) até 150 m² (apartamentos maiores).
Um valor base de R$ 1500 representa o aluguel mínimo na região analisada.
Um incremento médio de R$ 50 por m² reflete a valorização por área.
Variações de preço simulam fatores como localização, estado do imóvel, andar, infraestrutura e mobília.
Esse modelo pode ser útil para:
Imobiliárias definirem valores de aluguel iniciais;
Proprietários avaliarem a precificação de seus imóveis;
Inquilinos analisarem se os valores pagos estão alinhados ao mercado.
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
# Configuração de seeds para reprodutibilidade
np.random.seed(42)
tf.random.set_seed(42)
# Gerando dados de área e preço de aluguel
X = 30 + 120 * np.random.rand(100, 1) # Áreas entre 30m² e 150m²
y = 1500 + 50 * X + np.random.randn(100, 1) * 250 # Preço base + preço por m² + variação
# Construindo o modelo de regressão linear
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(1,)),
tf.keras.layers.Dense(units=1)
])
# Compilação com Adam para melhor convergência
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), loss='mean_squared_error')
# Treinamento do modelo
history = model.fit(X, y, epochs=2500, verbose=0)
# Previsões para visualização da linha de regressão
X_range = np.linspace(30, 150, 100).reshape(-1, 1)
y_pred = model.predict(X_range)
# Coeficientes do modelo
weights, bias = model.layers[0].get_weights()
print(f"weights: {weights[0][0]:.2f}")
print(f"bias: {bias[0]:.2f}")
# Visualização do modelo e dados
plt.figure(figsize=(10, 6))
plt.scatter(X, y, color='blue', alpha=0.5, label='Dados reais')
plt.plot(X_range, y_pred, color='red', label='Modelo de precificação')
plt.xlabel("Área do imóvel (m²)")
plt.ylabel("Valor do Aluguel (R$)")
plt.title("Relação entre Área e Valor do Aluguel")
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# Visualizando o histórico de perda
plt.figure(figsize=(10, 6))
plt.plot(history.history['loss'], color='purple')
plt.xlabel("Épocas")
plt.ylabel("Erro Quadrado Médio (MSE)")
plt.title("Convergência do Treinamento")
plt.grid(True, alpha=0.3)
plt.show()
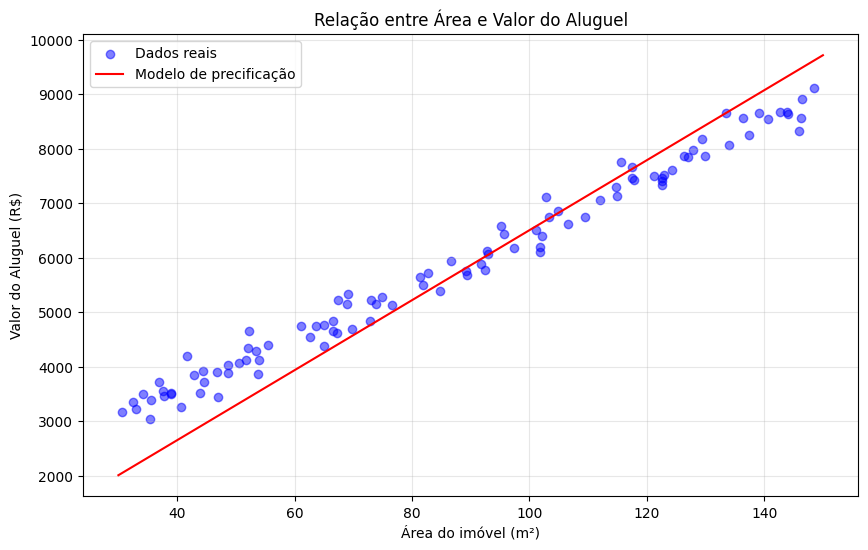
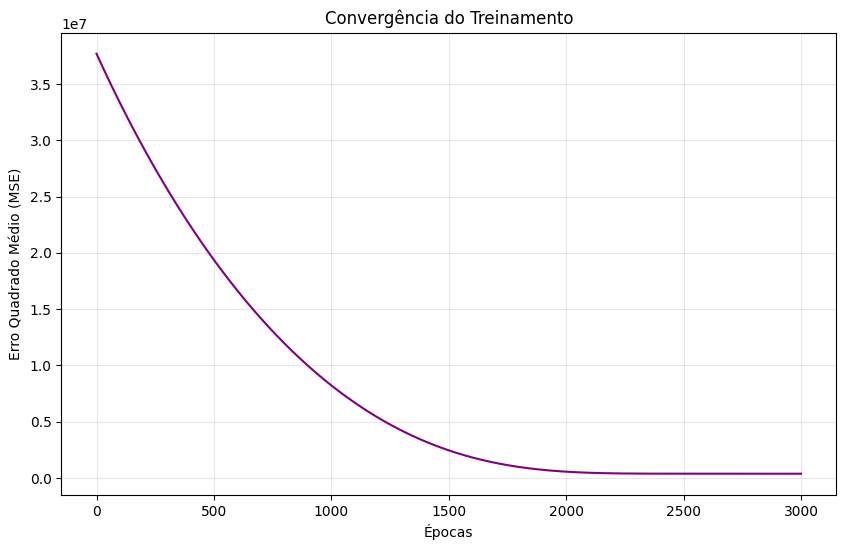
Análise dos Resultados
Valor Base (Intercepto): Representa o preço mínimo estimado na região.
Valor por m² (Coeficiente Angular): Mostra o aumento médio do aluguel para cada m² adicional.
Dispersão dos Pontos: Indica variações nos preços devido a fatores além da área, como localização, condições e infraestrutura do imóvel.
Esse tipo de análise pode ser expandido para incluir variáveis adicionais, como número de quartos, vagas de garagem e qualidade da localização, permitindo uma previsão mais precisa dos valores de aluguel no mercado imobiliário.
Rede Neural como Aproximadora de Funções Não Lineares#
Uma das aplicações mais fascinantes do machine learning é a capacidade de aproximar funções não lineares complexas, como a função seno, sem precisar conhecer a fórmula exata. Utilizando machine learning, é possível treinar um modelo para aprender a relação entre entradas e saídas observadas e, dessa forma, criar uma representação da função original.
Para isso, vamos construir um modelo de rede neural que será treinado com valores da função seno no intervalo de \(0\) a \(10\). Após o treinamento, testaremos o modelo em novos pontos para verificar se ele consegue reproduzir o comportamento da função seno.
Importando Bibliotecas Necessárias
Primeiro, importamos as bibliotecas:
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
numpy: para manipulação dos dados.matplotlib: para visualização dos resultados.tensorflow: para construir e treinar o modelo de machine learning.
Gerando Dados para o Treinamento
x_train = np.linspace(0, 10, 1000)
y_train = np.sin(x_train)
x_train: uma sequência de 1000 pontos igualmente espaçados entre \(0\) e \(10\).y_train: calculado usando a função seno de cada ponto emx_train. Esses pares \((x, y)\) representam os dados que o modelo usará para aprender a forma da função seno.
Definindo e Construindo o Modelo
model = Sequential([
tf.keras.layers.Input(shape=(1,)),
Dense(64, activation='relu'),
Dense(64, activation='relu'),
Dense(1)
])
Camada de entrada: aceita um valor escalar (a entrada
x).Camadas ocultas: duas camadas densas, cada uma com 64 neurônios e ativação
ReLU. Elas ajudam o modelo a capturar padrões não lineares complexos.Camada de saída: uma camada densa com um único neurônio (saída
y), pois queremos prever um valor contínuo.
Compilando o Modelo
model.compile(optimizer='adam', loss='mean_squared_error')
Otimizador:
adam, que é eficiente para encontrar o mínimo do erro em muitos tipos de redes.Função de perda:
mean_squared_error, ideal para problemas de regressão, que mede a diferença média ao quadrado entre os valores reais e os previstos.
Treinando o Modelo
history = model.fit(x_train, y_train, epochs=1500, batch_size=32, verbose=0)
Épocas: 1500, para garantir que o modelo tenha bastante tempo para aprender.
Tamanho do lote: 32 amostras por atualização de peso. Isso ajuda a estabilizar e acelerar o treinamento.
Gerando Dados de Teste e Fazendo Previsões
x_test = np.linspace(0, 10, 100)
y_test = np.sin(x_test)
y_pred = model.predict(x_test)
x_test: valores no mesmo intervalo de treinamento, mas com menos pontos.
y_pred: previsões do modelo para os valores em
x_test.
Visualizando os Resultados
plt.figure(figsize=(10, 6))
plt.plot(x_test, y_test, label='Função Senoidal')
plt.plot(x_test, y_pred, "--", label='Aproximação do Modelo')
plt.xlabel('X')
plt.ylabel('Y')
plt.title('Aproximação de Função Senoidal')
plt.legend()
plt.grid(True)
plt.show()
O gráfico mostra a função seno verdadeira (
y_test) e a curva gerada pelo modelo (y_pred). A semelhança entre as duas indica o quão bem o modelo conseguiu aprender a função.
Visualizando a Convergência do Treinamento
plt.figure(figsize=(10, 6))
plt.plot(history.history['loss'])
plt.xlabel('Época')
plt.ylabel('Erro Quadrático Médio')
plt.title('Convergência do Treinamento')
plt.grid(True)
plt.show()
O gráfico de perda mostra a redução do erro quadrado médio ao longo das épocas, indicando que o modelo aprendeu a forma da função seno.
Código Completo
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# Dados de treinamento
x_train = np.linspace(0, 10, 1000)
y_train = np.sin(x_train)
# Construindo o modelo
model = Sequential([
tf.keras.layers.Input(shape=(1,)),
Dense(64, activation='relu'),
Dense(64, activation='relu'),
Dense(1)
])
# Compilando o modelo
model.compile(optimizer='adam', loss='mean_squared_error')
# Treinamento
history = model.fit(x_train, y_train, epochs=1500, batch_size=32, verbose=0)
# Dados de teste
x_test = np.linspace(0, 10, 100)
y_test = np.sin(x_test)
y_pred = model.predict(x_test)
# Visualização dos resultados
plt.figure(figsize=(10, 6))
plt.plot(x_test, y_test, label='Função Senoidal')
plt.plot(x_test, y_pred, "--", label='Aproximação do Modelo')
plt.xlabel('X')
plt.ylabel('Y')
plt.title('Aproximação de Função Senoidal')
plt.legend()
plt.grid(True)
plt.show()
# Visualizando a convergência do treinamento
plt.figure(figsize=(10, 6))
plt.plot(history.history['loss'])
plt.xlabel('Época')
plt.ylabel('Erro Quadrático Médio')
plt.title('Convergência do Treinamento')
plt.grid(True)
plt.show()
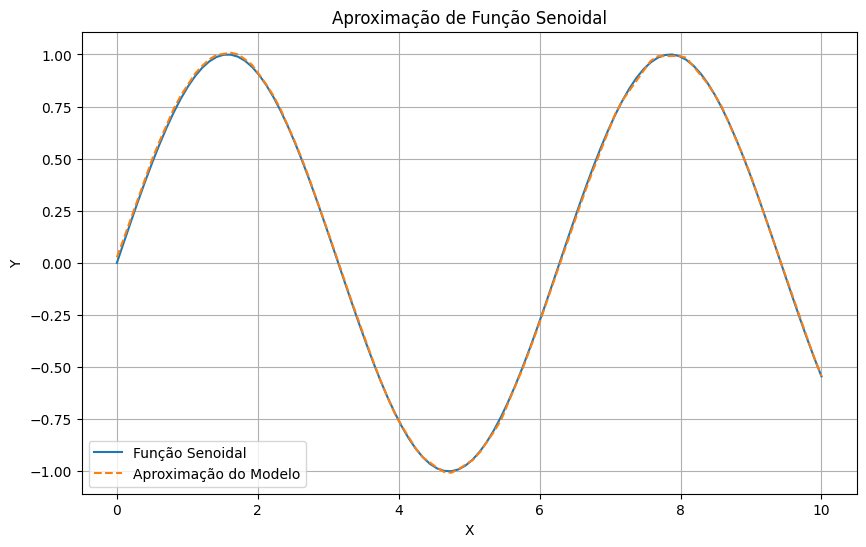
Após o treinamento, o modelo consegue reproduzir a forma da função seno, ilustrando a capacidade das redes neurais em aprender e aproximar funções complexas. Esse processo é especialmente útil em áreas que envolvem funções de difícil formulação analítica, como física, economia e biomedicina.
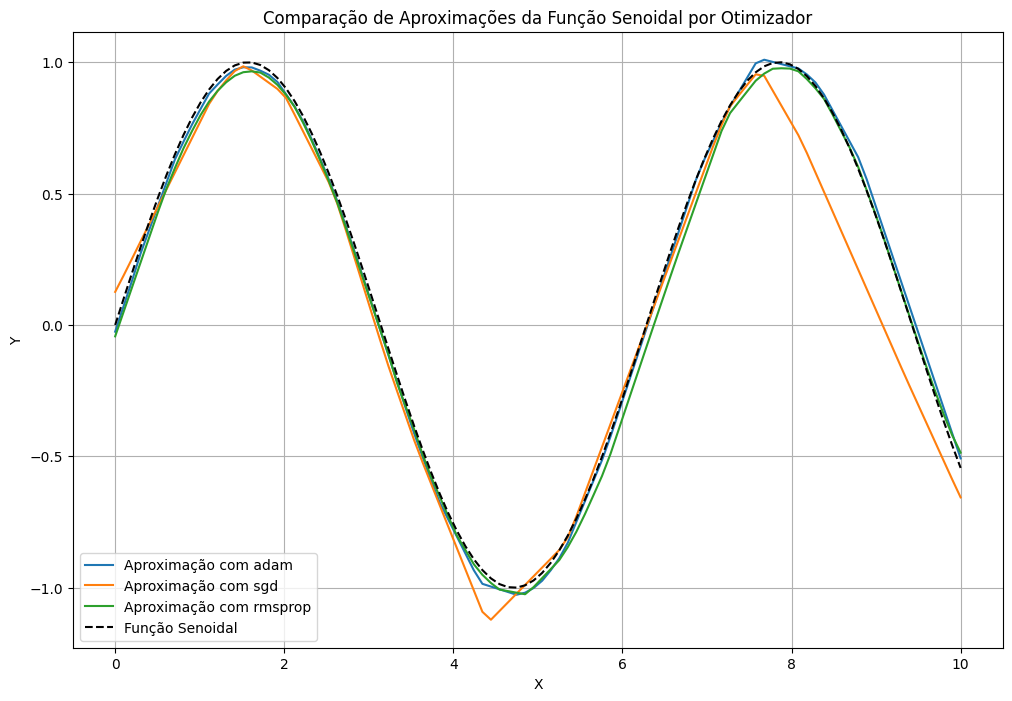
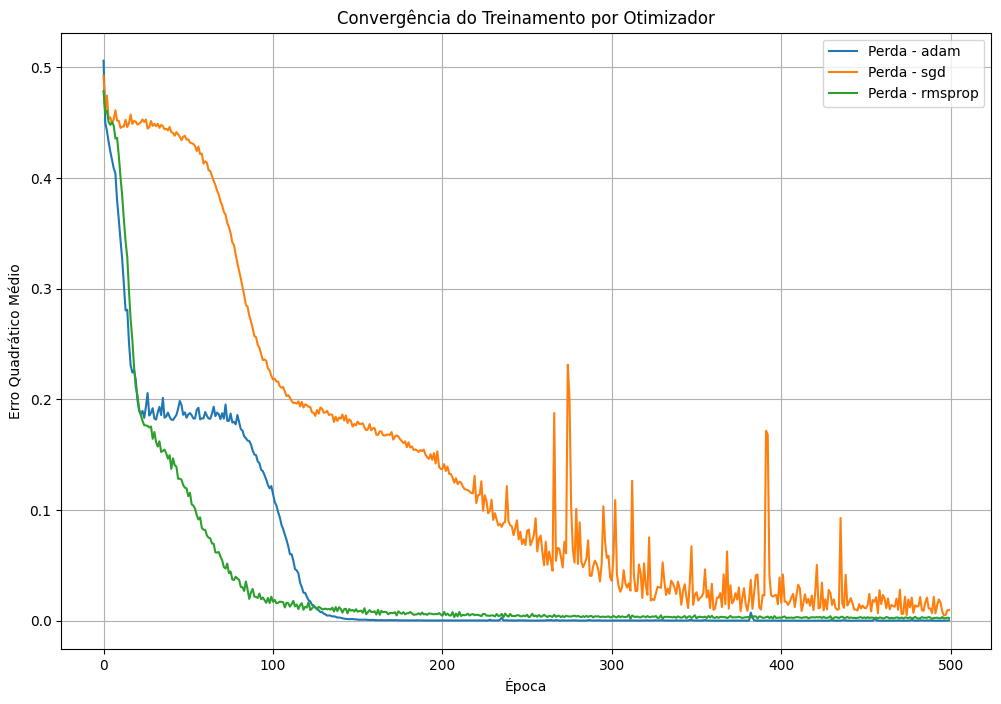
Exercício: Testando Otimizadores para Aproximação de Função Não Linear#
Neste exercício, vamos explorar o impacto de diferentes otimizadores ao aproximar a função seno no intervalo de \(0\) a \(10\). O objetivo é observar como a escolha do otimizador influencia o desempenho e a convergência do modelo.
Você irá:
Testar três otimizadores do Keras (
Adam,SGDeRMSprop), alterando o código conforme indicado.Visualizar a curva de perda para cada otimizador ao longo do treinamento.
Comparar o desempenho na aproximação da função seno e discutir qual otimizador teve melhor desempenho.
Código Base para Modificações
Use o código abaixo e modifique o otimizador para cada teste, conforme indicado:
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# Definindo os dados de treino
x_train = np.linspace(0, 10, 1000)
y_train = np.sin(x_train)
# Função para criar e treinar o modelo com um otimizador específico
def train_model(optimizer_name):
# Construir o modelo
model = Sequential([
tf.keras.layers.Input(shape=(1,)),
Dense(64, activation='relu'),
Dense(64, activation='relu'),
Dense(1)
])
# Compilar o modelo com o otimizador especificado
model.compile(optimizer=optimizer_name, loss='mean_squared_error')
# Treinar o modelo
history = model.fit(x_train, y_train, epochs=500, batch_size=32, verbose=0)
return model, history
# Lista de otimizadores para o teste
optimizers = ['adam', 'sgd', 'rmsprop']
histories = {}
models = {}
# Treinar o modelo e salvar os históricos de perda
for opt in optimizers:
...
# Gerando dados de teste
...
# Visualização das aproximações da função seno
...
# Visualização da convergência do treinamento (perda) para cada otimizador
...
Qual otimizador teve a menor curva de perda ao longo das épocas?
Algum otimizador produziu uma aproximação mais fiel à curva da função seno?
A escolha do otimizador influenciou a estabilidade da curva de perda ou gerou oscilações?
Resultado Esperado:
Classificação de Dígitos com Multilayer Perceptron#
O Multilayer Perceptron (MLP) é uma rede neural artificial composta de várias camadas de neurônios que é capaz de aprender representações complexas, resolvendo problemas de classificação e regressão. Neste exemplo, usaremos um MLP para classificar dígitos manuscritos do famoso conjunto de dados MNIST. O MNIST contém 60.000 imagens de treinamento e 10.000 de teste de dígitos de 0 a 9, com cada imagem em escala de cinza de 28x28 pixels.
Importando Bibliotecas Necessárias
Primeiro, importamos as bibliotecas para manipular dados, construir e treinar o modelo, e visualizar os resultados. Note que o TensorFlow possui uma lista de datasets incorporados, facilitando seu uso.
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Input
from tensorflow.keras.datasets import mnist
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
Carregando e Pré-processando os Dados
Carregamos os dados e aplicamos o pré-processamento necessário para preparar o MLP.
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
Visualizando uma Amostra de Imagens
Para entender melhor o conjunto de dados, vamos visualizar algumas das imagens de dígitos.
plt.figure(figsize=(10, 5))
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.imshow(x_train[i], cmap='gray')
plt.axis('off')
plt.title(f'Rótulo: {y_train[i]}')
plt.show()
Definindo e Construindo o Modelo
Para construir o modelo de rede neural MLP com camadas densas, vamos usar a camada Input para especificar a entrada, eliminando o aviso sobre input_shape:
model = Sequential([
Input(shape=(28, 28)), # Define a forma de entrada
Flatten(),
Dense(128, activation='relu'),
Dense(64, activation='relu'),
Dense(10, activation='softmax')
])
Camada de saída: usamos
softmaxcomo função de ativação, que converte os valores de saída em probabilidades. Isso permite que o modelo escolha o dígito com maior probabilidade como a classificação final.
Compilando o Modelo
Compilamos o modelo, definindo a função de perda, o otimizador e a métrica de desempenho:
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
Treinando o Modelo
Treinamos o modelo com as imagens de treinamento:
history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
Salvando o modelo
Após o treinamento, podemos salvar o modelo para reutilizá-lo em uma interface de classificação de novos dígitos. Insira o path no google drive, caso queira salvar e armazenar para uso posterior.
model.save('mlp_mnist_model.h5')
Avaliando o Modelo
Após o treinamento, avaliamos o modelo com o conjunto de teste:
test_loss, test_accuracy = model.evaluate(x_test, y_test)
print(f"Acurácia no conjunto de teste: {test_accuracy:.4f}")
Fazendo Previsões
Podemos fazer previsões sobre novas imagens e visualizar os resultados:
predictions = model.predict(x_test[:10]) # Para 10 imagens
plt.figure(figsize=(10, 5))
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.imshow(x_test[i], cmap='gray')
plt.axis('off')
plt.title(f'Previsto: {np.argmax(predictions[i])}, Real: {y_test[i]}')
plt.show()
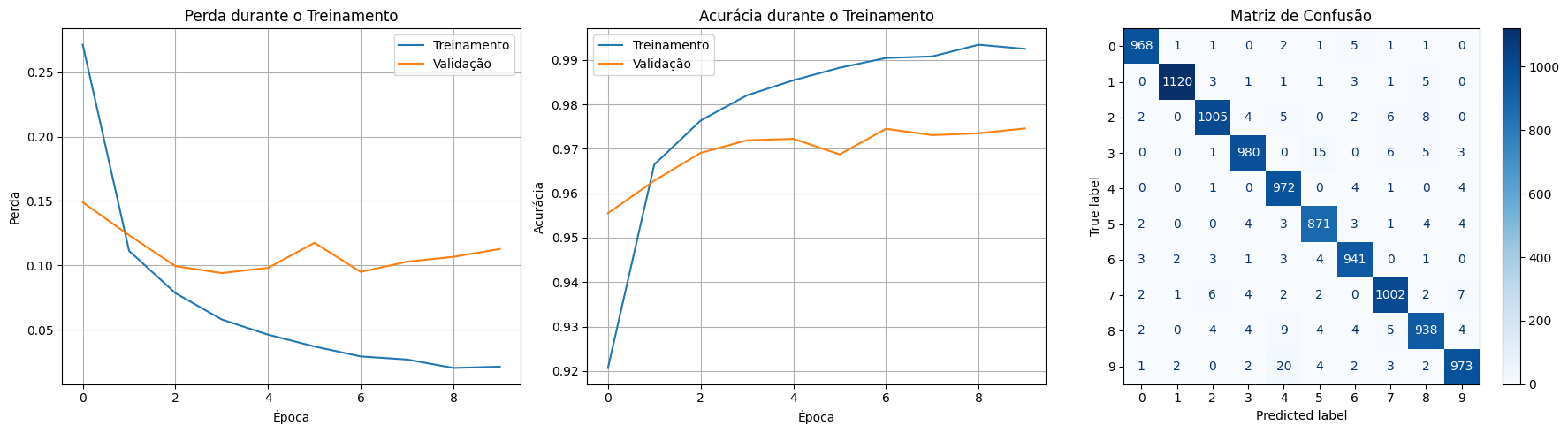
Visualizando a Convergência do Treinamento
Para entender a evolução da perda e da acurácia ao longo das épocas:
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='Treinamento')
plt.plot(history.history['val_loss'], label='Validação')
plt.xlabel('Época')
plt.ylabel('Perda')
plt.legend()
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], label='Treinamento')
plt.plot(history.history['val_accuracy'], label='Validação')
plt.xlabel('Época')
plt.ylabel('Acurácia')
plt.legend()
plt.grid(True)
plt.show()
Matriz de Confusão como Análise Essencial
A matriz de confusão permite verificar a quantidade de classificações corretas e incorretas para cada classe de dígitos, sendo uma análise útil para entender onde o modelo tem dificuldades. Abaixo, estão as expressões matemáticas que definem as métricas principais usadas para construir e analisar a matriz de confusão:
Métrica |
Símbolo/Expressão |
Descrição |
|---|---|---|
True Positives (TP) |
\( TP_i = \text{CM}_{ii} \) |
Número de vezes que o modelo classificou corretamente a classe \( i \) como \( i \). Representa os acertos do modelo para a classe \( i \), ou seja, quando a previsão coincide com a classe verdadeira. |
False Positives (FP) |
\( FP_i = \sum_{j \neq i} \text{CM}_{ji} \) |
Número de vezes que o modelo classificou incorretamente outras classes \( j \) como sendo a classe \( i \). Indica os erros onde o modelo rotulou amostras de outras classes como \( i \). |
False Negatives (FN) |
\( FN_i = \sum_{j \neq i} \text{CM}_{ij} \) |
Número de vezes que o modelo classificou a classe \( i \) como sendo uma outra classe \( j \). Indica os casos em que o modelo não conseguiu identificar corretamente a classe \( i \). |
True Negatives (TN) |
\( TN_i = \sum_{k \neq i} \sum_{l \neq i} \text{CM}_{kl} \) |
Total de classificações corretas e incorretas para todas as outras classes, exceto \( i \). Representa as previsões feitas corretamente para classes que não são \( i \), além de erros onde nenhuma das classes envolvem \( i \). |
Accuracy |
\( \frac{\sum_{i} \text{CM}_{ii}}{N} \) |
Proporção de previsões corretas em relação ao total de amostras \( N \). Mede o desempenho geral do modelo na classificação, considerando todas as classes. |
Precision (para classe \( i \)) |
\( \frac{TP_i}{TP_i + FP_i} \) |
Proporção de previsões corretas para a classe \( i \) entre todas as previsões feitas como \( i \). Mede a precisão do modelo ao identificar a classe \( i \) entre as amostras rotuladas como \( i \). |
Recall (para classe \( i \)) |
\( \frac{TP_i}{TP_i + FN_i} \) |
Proporção de previsões corretas para a classe \( i \) entre todas as instâncias reais de \( i \). Mede a capacidade do modelo em encontrar corretamente as amostras da classe \( i \) entre os dados verdadeiros dessa classe. |
Implementação em Python:
y_pred = np.argmax(model.predict(x_test), axis=1)
cm = confusion_matrix(y_test, y_pred)
ConfusionMatrixDisplay(cm).plot(cmap="Blues")
plt.title("Matriz de Confusão")
plt.show()
Código Completo#
O código completo para o processo de classificação de dígitos com o MLP está abaixo:
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Input
from tensorflow.keras.datasets import mnist
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
# Carregando e pré-processando os dados
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# Visualizando uma amostra de imagens
plt.figure(figsize=(10, 5))
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.imshow(x_train[i], cmap='gray')
plt.axis('off')
plt.title(f'Rótulo: {y_train[i]}')
plt.show()
# Definindo e construindo o modelo
model = Sequential([
Input(shape=(28, 28)),
Flatten(),
Dense(128, activation='relu'),
Dense(64, activation='relu'),
Dense(10, activation='softmax')
])
# Compilando o modelo
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Treinando o modelo
history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
# Salvando modelo
model.save('mlp_mnist_model.h5')
# Avaliando o modelo
test_loss, test_accuracy = model.evaluate(x_test, y_test)
print(f"Acurácia no conjunto de teste: {test_accuracy:.4f}")
# Fazendo previsões
predictions = model.predict(x_test[:10])
plt.figure(figsize=(10, 5))
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.imshow(x_test[i], cmap='gray')
plt.axis('off')
plt.title(f'Previsto: {np.argmax(predictions[i])}, Real: {y_test[i]}')
plt.show()
# Visualizando a convergência do treinamento
plt.figure(figsize=(18, 5))
# Gráfico de perda
plt.subplot(1, 3, 1)
plt.plot(history.history['loss'], label='Treinamento')
plt.plot(history.history['val_loss'], label='Validação')
plt.xlabel('Época')
plt.ylabel('Perda')
plt.legend()
plt.grid(True)
plt.title("Perda durante o Treinamento")
# Gráfico de acurácia
plt.subplot(1, 3, 2)
plt.plot(history.history['accuracy'], label='Treinamento')
plt.plot(history.history['val_accuracy'], label='Validação')
plt.xlabel('Época')
plt.ylabel('Acurácia')
plt.legend()
plt.grid(True)
plt.title("Acurácia durante o Treinamento")
# Matriz de Confusão
plt.subplot(1, 3, 3)
y_pred = np.argmax(model.predict(x_test), axis=1)
cm = confusion_matrix(y_test, y_pred)
ConfusionMatrixDisplay(cm).plot(cmap="Blues", ax=plt.gca()) # Ajuste para plotar no subplot atual
plt.title("Matriz de Confusão")
plt.tight_layout() # Ajuste para evitar sobreposição
plt.show()
Criando Interfaces Gráficas com Gradio#
Depois de treinar sua rede neural, você pode usar o Gradio para criar uma interface interativa. Essa interface permitirá testar a rede MLP com novas imagens de maneira prática e intuitiva. Abaixo, apresento um guia passo a passo para implementar essa interface.
Carregando o Modelo para a Interface
Primeiro, crie um novo script para a interface Gradio e carregue o modelo treinado:
from tensorflow.keras.models import load_model
model = load_model('mlp_mnist_model.h5')
Assim que o modelo é carregado com load_model, ele estará pronto para realizar previsões. Não é necessário recompilar o modelo para fazer inferências.
Criando uma Interface no Gradio
Para começar, vamos criar um exemplo básico que carrega uma imagem e aplica uma transformação — neste caso, converte a imagem de RGB para escala de cinza.
import gradio as gr
import cv2
# Função para exibir a imagem carregada em escala de cinza
def show_image(image):
# Converte a imagem para escala de cinza
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
return gray_image # Retorna a imagem em escala de cinza
# Interface Gradio
iface = gr.Interface(
fn=show_image,
inputs=gr.Image(type="numpy", label="Carregue uma imagem"), # Usando numpy para o formato OpenCV
outputs="image",
title="Visualizador de Imagem em Escala de Cinza com OpenCV",
description="Carregue uma imagem do seu computador para visualizá-la em escala de cinza."
)
# Executa a interface
iface.launch()
Desafio: Crie seu Próprio Classificador de Dígitos Usando o modelo treinado, implemente um classificador de dígitos com Gradio! Configure a interface para que as imagens de entrada possam ser em RGB, carregadas do computador ou desenhadas em uma tela interativa.
Exercício: Classificação de Roupas com o Fashion MNIST#
Neste exercício, você irá construir e treinar um modelo Multilayer Perceptron (MLP) para classificar itens de vestuário do conjunto de dados Fashion MNIST. O objetivo é avaliar o desempenho do modelo por meio de métricas e visualizações.
Tarefas:
Carregar e Pré-processar os Dados
Utilize
tensorflow.keras.datasetspara carregar o conjunto Fashion MNIST.Normalize os dados para o intervalo [0, 1].
Construir o Modelo
Crie um modelo MLP com camadas densas e ative
relupara as camadas intermediárias esoftmaxna camada de saída.Teste diferentes configurações (número de neurônios e camadas) para obter o melhor desempenho.
Compilar e Treinar
Compile o modelo usando o otimizador
adam, com a função de perdasparse_categorical_crossentropye a métricaaccuracy.Treine o modelo e registre o tempo de treinamento.
Visualizar Desempenho
Plote as curvas de treino para acurácia e perda (loss).
Exiba a matriz de confusão para avaliar a performance por classe.
Comentário e Análise dos Resultados
Comente sobre os resultados obtidos. Informe qual foi a configuração escolhida para o modelo e por que ela apresentou o melhor desempenho.
Se testou outras configurações, descreva as principais observações e as mudanças de desempenho que notou.
Código Base
Preencha o código abaixo para completar o exercício:
# Importação de bibliotecas
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.datasets import fashion_mnist
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
import time
# Carregar e pré-processar os dados
# Definir e construir o modelo
# Compilar o modelo
# Treinamento do modelo e cálculo do tempo
# Visualizar curvas de treino (acurácia e perda) e matriz de confusão
# Comentário e análise dos resultados