Capítulo 7: Computação Numérica e Visualização de Dados#

NumPy - Computação Numérica#
NumPy é uma biblioteca fundamental para computação numérica em Python. Ela fornece ferramentas poderosas para manipulação eficiente de arrays multidimensionais e operações matemáticas rápidas. NumPy é amplamente utilizado em diversas áreas, desde ciência de dados até aprendizado de máquina.
Importando a Biblioteca NumPy#
Para utilizar o NumPy, você precisa importar a biblioteca em seu código Python. A instrução import numpy as np é comumente usada para importar o NumPy e atribuir a ele o apelido “np”. Isso facilita a referência às funções e objetos da biblioteca.
import numpy as np
Definindo Arrays#
O array é a estrutura central do NumPy. Um array unidimensional (1D) funciona como um vetor: uma sequência de valores em linha. Um array bidimensional (2D) é uma matriz, organizada em linhas e colunas. Para criar qualquer um deles, passamos uma lista Python para a função np.array, que a converte em um array NumPy (uma lista simples vira um array 1D; uma lista de listas, um array 2D).
Array 1D (vetor) array_1d = np.array([1, 2, 3, 4, 5]):
| array_1d | 1 | 2 | 3 | 4 | 5 |
Array 2D (matriz) array_2d = np.array([[1, 2, 3], [4, 5, 6]]):
| 1 | 2 | 3 | |
| 4 | 5 | 6 |
# Array unidimensional (vetor)
array_1d = np.array([1, 2, 3, 4, 5])
print(f"array_1d:\n{array_1d}")
# Array bidimensional (matriz)
array_2d = np.array([[1, 2, 3], [4, 5, 6]])
print(f"array_2d:\n{array_2d}")
Saída do Código:
array_1d:
[1 2 3 4 5]
array_2d:
[[1 2 3]
[4 5 6]]
Além de criar arrays a partir de listas, o NumPy oferece funções para gerar arrays já preenchidos, úteis para inicializar dados:
np.zeros(shape): todos os elementos iguais a0;np.ones(shape): todos os elementos iguais a1;np.random.rand(linhas, colunas): valores aleatórios entre0e1.
zeros_array = np.zeros((3, 3)) # matriz 3x3 de zeros
ones_array = np.ones((2, 4)) # matriz 2x4 de uns
random_array = np.random.rand(3, 2) # matriz 3x2 aleatória
print(f"zeros_array:\n{zeros_array}")
print(f"ones_array:\n{ones_array}")
print(f"random_array:\n{random_array}")
Saída do Código:
zeros_array:
[[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]]
ones_array:
[[1. 1. 1. 1.]
[1. 1. 1. 1.]]
random_array:
[[0.53719399 0.11460566]
[0.54644121 0.10672048]
[0.01692397 0.05397693]]
Nota - Valores Aleatórios
Os valores no random_array podem variar a cada execução, pois são gerados aleatoriamente.
Verificando a Forma (shape) dos Arrays#
O atributo shape informa as dimensões de um array. Ele retorna uma tupla: para um array 2D, (número de linhas, número de colunas); para um array 1D, apenas (tamanho,).
Na matriz abaixo, são 2 linhas e 3 colunas, então shape = (2, 3):
| col 0 | col 1 | col 2 | |
| lin 0 | 1 | 2 | 3 |
| lin 1 | 4 | 5 | 6 |
print(f"Shape do array_1d: {array_1d.shape}")
print(f"Shape do array_2d: {array_2d.shape}")
print(f"Shape do zeros_array: {zeros_array.shape}")
Saída do Código:
Shape do array_1d: (5,)
Shape do array_2d: (2, 3)
Shape do zeros_array: (3, 3)
Esse recurso é muito útil para entender rapidamente a estrutura dos dados, especialmente ao trabalhar com matrizes, imagens ou tensores em machine learning.
Acessando Elementos em Arrays NumPy#
Após criar um array, é comum acessar elementos específicos, linhas, colunas ou fatias (slices). O NumPy usa indexação baseada em zero, assim como as listas: o primeiro elemento tem índice 0.
Acessando Elementos em Arrays Unidimensionais#
Em um array 1D, usamos colchetes com o índice. Índices negativos contam a partir do fim (-1 é o último). Veja as duas formas de indexar array_1d = np.array([10, 20, 30, 40, 50]):
| índice | 0 | 1 | 2 | 3 | 4 |
| índice neg. | -5 | -4 | -3 | -2 | -1 |
| valor | 10 | 20 | 30 | 40 | 50 |
Uma fatia array_1d[1:4] seleciona do índice 1 ao 3 (o 4 fica de fora), os valores em destaque:
| índice | 0 | 1 | 2 | 3 | 4 |
| valor | 10 | 20 | 30 | 40 | 50 |
array_1d = np.array([10, 20, 30, 40, 50])
print(f"Primeiro elemento: {array_1d[0]}")
print(f"Último elemento: {array_1d[-1]}")
print(f"Elementos do índice 1 ao 3: {array_1d[1:4]}")
Saída do Código:
Primeiro elemento: 10
Último elemento: 50
Elementos do índice 1 ao 3: [20 30 40]
Acessando Elementos em Arrays Multidimensionais#
Em arrays 2D, a indexação usa o formato array[linha, coluna]. A matriz a seguir tem os índices de linha e coluna indicados nas bordas:
| col 0 | col 1 | col 2 | |
| lin 0 | 1 | 2 | 3 |
| lin 1 | 4 | 5 | 6 |
| lin 2 | 7 | 8 | 9 |
Acima, array_2d[0, 1] (laranja) vale 2 e array_2d[2, 2] (verde) vale 9. Já uma fatia bidimensional array_2d[0:2, 0:2] recorta a submatriz do canto superior esquerdo (linhas 0–1, colunas 0–1):
| col 0 | col 1 | col 2 | |
| lin 0 | 1 | 2 | 3 |
| lin 1 | 4 | 5 | 6 |
| lin 2 | 7 | 8 | 9 |
array_2d = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
print(f"Linha 0, coluna 1: {array_2d[0, 1]}")
print(f"Linha 2, coluna 2: {array_2d[2, 2]}")
print(f"Segunda linha: {array_2d[1]}")
print(f"Primeira coluna: {array_2d[:, 0]}")
print(f"Submatriz 2x2:\n{array_2d[0:2, 0:2]}")
Saída do Código:
Linha 0, coluna 1: 2
Linha 2, coluna 2: 9
Segunda linha: [4 5 6]
Primeira coluna: [1 4 7]
Submatriz 2x2:
[[1 2]
[4 5]]
Indexação Booleana (Filtragem)#
Além de acessar por posição, podemos selecionar elementos por uma condição. Uma comparação como array > 3 gera um array de booleanos (True/False), usado para filtrar ou modificar apenas os elementos que satisfazem a condição.
| array_1d | 1 | 2 | 3 | 4 | 5 |
| > 3 | False | False | False | True | True |
No exemplo, array_1d > 3 resulta em [False, False, False, True, True]; a filtragem retorna apenas os valores True (4 e 5), e a atribuição condicional zera esses elementos.
array_1d = np.array([1, 2, 3, 4, 5])
# Seleciona apenas os elementos maiores que 3
print("Filtrados:", array_1d[array_1d > 3])
# Atribui zero aos elementos maiores que 3
array_1d[array_1d > 3] = 0
print("Após substituição:", array_1d)
Saída do Código:
Filtrados: [4 5]
Após substituição: [1 2 3 0 0]
Criando Arrays com Valores Específicos#
O NumPy facilita a criação de arrays preenchidos com valores gerados automaticamente, úteis para dados de teste, simulações e cálculos numéricos.
Arrays com Valores Repetidos#
A função np.full(shape, valor) cria um array de qualquer dimensão com todos os elementos iguais ao valor informado:
| 7 | 7 | 7 |
| 7 | 7 | 7 |
| 7 | 7 | 7 |
full_array = np.full((3, 3), 7) # matriz 3x3 preenchida com 7
print(f"Array preenchido:\n{full_array}")
Saída do Código:
Array preenchido:
[[7 7 7]
[7 7 7]
[7 7 7]]
Arrays com Valores Espaçados Uniformemente#
A função np.linspace(start, stop, num) gera num valores igualmente espaçados entre start e stop (ambos incluídos). O espaçamento entre valores consecutivos é:
Para np.linspace(0, 1, 5), temos \(\Delta = \tfrac{1-0}{5-1} = 0{,}25\), gerando os 5 valores:
| linspace | 0.0 | 0.25 | 0.5 | 0.75 | 1.0 |
linear_array = np.linspace(0, 1, 5) # 5 valores de 0 a 1
print(f"Array linear:\n{linear_array}")
Saída do Código:
Array linear:
[0. 0.25 0.5 0.75 1. ]
np.linspace vs np.arange#
As duas geram sequências, mas controlam coisas diferentes: no linspace você define quantos valores quer; no arange você define o passo entre eles (e o stop fica de fora).
Função |
Você controla |
|
|---|---|---|
|
a quantidade de valores |
sim |
|
o passo entre valores |
não |
Resultado de np.arange(0, 6, 1) (passo 1, do 0 ao 5):
| arange | 0 | 1 | 2 | 3 | 4 | 5 |
linear_array = np.linspace(0, 1, 5) # quantidade fixa (5 valores)
arange_array = np.arange(0, 6, 1) # passo fixo (de 1 em 1)
print(f"linspace: {linear_array}")
print(f"arange: {arange_array}")
Saída do Código:
linspace: [0. 0.25 0.5 0.75 1. ]
arange: [0 1 2 3 4 5]
Concatenando e Empilhando Arrays#
O NumPy combina arrays de três formas comuns: np.concatenate une vetores 1D em sequência, np.vstack empilha matrizes na vertical (uma sobre a outra) e np.hstack junta matrizes na horizontal (lado a lado). Em todos os casos, o resultado é uma nova matriz (as originais não são alteradas), que você pode guardar em uma variável.
Concatenação (1D): np.concatenate cola um vetor no fim do outro:
| a | 1 | 2 | 3 |
| b | 4 | 5 | 6 |
| a ⊕ b | 1 | 2 | 3 | 4 | 5 | 6 |
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
print(np.concatenate((a, b)))
Saída do Código:
[1 2 3 4 5 6]
Empilhamento vertical: np.vstack coloca uma matriz embaixo da outra (precisam ter o mesmo número de colunas):
| topo | 1 | 2 | 3 |
| topo | 4 | 5 | 6 |
| base | 10 | 20 | 30 |
| base | 40 | 50 | 60 |
topo = np.array([[1, 2, 3], [4, 5, 6]])
base = np.array([[10, 20, 30], [40, 50, 60]])
# vstack devolve uma nova matriz; guardamos em uma variável
empilhada = np.vstack((topo, base))
print(empilhada)
Saída do Código:
[[ 1 2 3]
[ 4 5 6]
[10 20 30]
[40 50 60]]
Empilhamento horizontal: np.hstack coloca uma matriz ao lado da outra (precisam ter o mesmo número de linhas):
| 1 | 2 | 3 | 10 | 20 | 30 |
| 4 | 5 | 6 | 40 | 50 | 60 |
# hstack também devolve uma nova matriz
lado_a_lado = np.hstack((topo, base))
print(lado_a_lado)
Saída do Código:
[[ 1 2 3 10 20 30]
[ 4 5 6 40 50 60]]
Reshape e Transposição#
Duas operações reorganizam a estrutura de um array sem alterar os valores: o reshape muda a forma (a tupla de dimensões) e a transposição troca linhas por colunas.
Reshape: Alterando a Forma de um Array#
O reshape redistribui os mesmos elementos em uma nova forma. A única exigência é que o número total de elementos seja preservado (aqui, sempre 5). Veja array.reshape((5, 1)), que transforma o vetor de 5 elementos em uma coluna 5×1:
| 1×5 | 1 | 2 | 3 | 4 | 5 |
vira
| 5×1 | 1 |
| 2 | |
| 3 | |
| 4 | |
| 5 |
array_1d = np.array([1, 2, 3, 4, 5])
array_5x1 = array_1d.reshape((5, 1))
print(f"Shape: {array_5x1.shape}")
print(array_5x1)
Saída do Código:
Shape: (5, 1)
[[1]
[2]
[3]
[4]
[5]]
O reshape também alcança dimensões maiores. Por exemplo, uma matriz 3×3 (9 elementos) pode virar um array tridimensional 3×1×3:
array_2d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
array_3d = array_2d.reshape((3, 1, 3))
print(array_3d)
Saída do Código:
[[[1 2 3]]
[[4 5 6]]
[[7 8 9]]]
Transposição: Reorganizando as Dimensões#
A transposição troca linhas por colunas: o elemento da posição \((i, j)\) vai para a posição \((j, i)\). Usamos o atributo .T, que leva uma matriz \(2\times3\) para \(3\times2\):
| 2×3 | 1 | 2 | 3 |
| 4 | 5 | 6 |
vira
| 3×2 | 1 | 4 |
| 2 | 5 | |
| 3 | 6 |
array_2d = np.array([[1, 2, 3], [4, 5, 6]]) # shape (2, 3)
array_transposta = array_2d.T # shape (3, 2)
print(array_transposta)
Saída do Código:
[[1 4]
[2 5]
[3 6]]
Operações com Arrays (Vetorização)#
A vetorização é a aplicação de uma operação sobre o array inteiro de uma só vez, sem escrever laços explícitos. Além de deixar o código mais curto e legível, ela é bem mais rápida: as operações rodam internamente em código otimizado (em C), e não elemento a elemento no interpretador Python.
Compare as duas formas de somar dois vetores a e b:
# Sem vetorização: laço explícito, elemento a elemento
resultado = []
for i in range(len(a)):
resultado.append(a[i] + b[i])
# Com vetorização: uma única expressão
resultado = a + b
As duas produzem o mesmo resultado, mas a versão vetorizada é mais clara e eficiente. A seguir, as operações vetorizadas mais comuns.
Operações Elemento a Elemento#
A forma mais simples de vetorização aplica a operação a cada par de elementos na mesma posição. Para dois vetores de mesmo tamanho:
| a | 1 | 2 | 3 | 4 | 5 |
| b | 10 | 20 | 30 | 40 | 50 |
| a + b | 11 | 22 | 33 | 44 | 55 |
A multiplicação por um escalar segue a mesma ideia: o valor é aplicado a todos os elementos, \(k\,\vec{a} = [\,k\,a_0,\ k\,a_1,\ \ldots\,]\).
a = np.array([1, 2, 3, 4, 5])
b = np.array([10, 20, 30, 40, 50])
print(a + b) # soma elemento a elemento
print(a * 2) # multiplicação por escalar
Saída do Código:
[11 22 33 44 55]
[ 2 4 6 8 10]
Produto Escalar#
O produto escalar (ou produto interno) multiplica os elementos correspondentes de dois vetores e soma tudo, resultando em um único número:
| a | 1 | 2 | 3 | |
| b | 4 | 5 | 6 | |
| a · b | 4 | 10 | 18 | = 32 |
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
print(np.dot(a, b)) # 1*4 + 2*5 + 3*6
print(a @ b) # o operador @ faz o mesmo
Saída do Código:
32
32
Redução por Eixo: axis=0 e axis=1#
Funções como np.sum e np.mean podem operar sobre o array inteiro ou ao longo de um eixo específico. Em uma matriz 2D, axis=0 percorre as linhas (gera um valor por coluna) e axis=1 percorre as colunas (gera um valor por linha).
| col 0 | col 1 | col 2 | axis=1 → | |
| lin 0 | 1 | 2 | 3 | 6 |
| lin 1 | 4 | 5 | 6 | 15 |
| lin 2 | 7 | 8 | 9 | 24 |
| ↓ axis=0 | 12 | 15 | 18 |
m = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
print(np.sum(m, axis=0)) # soma por coluna (percorre as linhas)
print(np.sum(m, axis=1)) # soma por linha (percorre as colunas)
print(np.mean(m, axis=1)) # média por linha
Saída do Código:
[12 15 18]
[ 6 15 24]
[2. 5. 8.]
Dica - Lembrando os Eixos
Pense no axis como a dimensão que é “colapsada”: axis=0 colapsa as linhas e sobra uma linha de totais por coluna; axis=1 colapsa as colunas e sobra uma coluna de totais por linha.
Produto Matricial#
O produto matricial combina linhas da primeira matriz com colunas da segunda. Cada elemento \(C_{ij}\) é o produto escalar da linha \(i\) de \(A\) com a coluna \(j\) de \(B\):
Para \(A\) e \(B\) de tamanho \(2\times2\):
Uma forma de visualizar: \(B\) fica acima, \(A\) à esquerda, e cada elemento de \(C\) ocupa o cruzamento de uma linha de \(A\) com uma coluna de \(B\). Em destaque, \(C_{00}\) é o produto escalar da linha 0 de \(A\) (laranja) pela coluna 0 de \(B\) (laranja): \(1{\cdot}5 + 2{\cdot}7 = 19\) (verde).
| 5 | 6 | ||
| 7 | 8 | ||
| 1 | 2 | 19 | 22 |
| 3 | 4 | 43 | 50 |
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
print(A @ B) # produto matricial
print(A * B) # multiplicação elemento a elemento (≠)
Saída do Código:
[[19 22]
[43 50]]
[[ 5 12]
[21 32]]
Atenção - Produto Matricial vs Elemento a Elemento
O produto matricial (np.dot ou @) é diferente da multiplicação elemento a elemento (*). O * apenas multiplica posições correspondentes; o @ faz a combinação linha-por-coluna da álgebra linear.
Funções Matemáticas#
O NumPy oferece uma ampla gama de funções matemáticas otimizadas para operações com arrays. Abaixo estão algumas das funções mais comuns organizadas por categoria, seguidas de exemplos.
Tabela de Funções Matemáticas
Categoria |
Função |
Descrição |
|---|---|---|
Trigonométricas |
|
Calcula o seno de cada elemento do array. |
|
Calcula o cosseno de cada elemento do array. |
|
|
Calcula a tangente de cada elemento do array. |
|
Exponenciais e Logarítmicas |
|
Calcula o exponencial \( e^x \) de cada elemento. |
|
Calcula o logaritmo natural \( \ln(x) \) de cada elemento. |
|
Outras Funções |
|
Calcula a raiz quadrada de cada elemento do array. |
Funções Trigonométricas
As funções trigonométricas podem ser usadas para cálculos com ângulos, sendo que os valores devem ser ajustados para evitar resultados indefinidos.
As funções operam em radianos (\(\pi\) rad \(= 180^\circ\)) e atuam elemento a elemento. Valem, entre outras, a identidade fundamental e a definição da tangente:
Exemplo:
import numpy as np
# NumPy trabalha em radianos, então convertemos os ângulos de graus
graus = np.array([0, 30, 45, 60])
theta = np.radians(graus)
# Cada função é aplicada a todo o array de uma vez (vetorização)
print("Ângulos (graus):", graus)
print("Seno: ", np.round(np.sin(theta), 2))
print("Cosseno: ", np.round(np.cos(theta), 2))
print("Tangente: ", np.round(np.tan(theta), 2))
Saída do Código:
Ângulos (graus): [ 0 30 45 60]
Seno: [0. 0.5 0.71 0.87]
Cosseno: [1. 0.87 0.71 0.5 ]
Tangente: [0. 0.58 1. 1.73]
Funções Exponenciais e Logarítmicas
As funções exponenciais e logarítmicas são amplamente utilizadas em cálculos matemáticos e científicos.
A exponencial natural e o logaritmo natural são funções inversas (para \(x > 0\)):
Exemplo:
import numpy as np
valores = np.array([1, 2, 3, 4])
# Funções aplicadas a todo o array (vetorização)
print("Valores: ", valores)
print("exp (e^x): ", np.round(np.exp(valores), 2))
print("log (ln x): ", np.round(np.log(valores), 2))
# exp e log são inversas: log(exp(x)) recupera o valor original
print("log(exp(x)):", np.round(np.log(np.exp(valores)), 2))
Saída do Código:
Valores: [1 2 3 4]
exp (e^x): [ 2.72 7.39 20.09 54.6 ]
log (ln x): [0. 0.69 1.1 1.39]
log(exp(x)): [1. 2. 3. 4.]
Atenção - Domínio do Logaritmo
O cálculo do logaritmo natural requer elementos estritamente positivos. Para valores zero ou negativos, o NumPy emite um aviso (RuntimeWarning) e retorna -inf ou nan, respectivamente.
Raiz Quadrada
A função np.sqrt permite calcular a raiz quadrada de cada elemento de um array. Para lidar com números negativos, pode-se utilizar números complexos.
A raiz quadrada é a potência de expoente \(\tfrac{1}{2}\), definida para \(x \ge 0\) nos números reais:
Exemplo:
import numpy as np
values = np.array([4, 9, 16, 25])
print(f"Raiz Quadrada: {[f'{x:.2f}' for x in np.sqrt(values)]}")
Saída do Código:
Raiz Quadrada: ['2.00', '3.00', '4.00', '5.00']
Dica - Raiz de Números Negativos
Para calcular a raiz quadrada de números negativos, crie o array com dtype=complex. Assim, a raiz de -4 é representada como o número complexo 2j, em vez de gerar um aviso e nan.
Operações Estatísticas#
O NumPy oferece funções e recursos avançados para cálculos estatísticos, manipulação de dados e operações lógicas. Abaixo, as operações estão organizadas em categorias para facilitar o entendimento.
Nota - Funciona com Listas do Python
Essas funções do NumPy também funcionam com listas do Python, não apenas com arrays numpy.ndarray. Ao receber uma lista, o NumPy a converte internamente em um array para realizar as operações.
Tabela de Funções Estatísticas
Categoria |
Função |
Descrição |
|---|---|---|
Média |
|
Calcula a média aritmética do array ou lista. |
Variância |
|
Calcula a variância, medindo a dispersão dos dados em relação à média. |
Desvio Padrão |
|
Retorna a raiz quadrada da variância, indicando a dispersão dos dados na mesma unidade. |
Mínimo e Máximo |
|
Retorna o menor valor do array ou lista. |
|
Retorna o maior valor do array ou lista. |
Para um conjunto de \(n\) valores \(x_1, x_2, \ldots, x_n\):
Média: \(\bar{x} = \dfrac{1}{n}\sum_{i=1}^{n} x_i\)
Variância: \(\sigma^2 = \dfrac{1}{n}\sum_{i=1}^{n} (x_i - \bar{x})^2\)
Desvio padrão: \(\sigma = \sqrt{\sigma^2}\)
Exemplo Prático - Estatísticas
import numpy as np
# Pode ser uma lista ou um array
dados = [1, 2, 3, 4, 5] # também funcionaria com np.array(dados)
# Cálculos estatísticos
media = np.mean(dados)
variancia = np.var(dados)
desvio_padrao = np.std(dados)
minimo = np.min(dados)
maximo = np.max(dados)
# Exibição dos resultados
print(f"Média: {media:.2f}")
print(f"Variância: {variancia:.2f}")
print(f"Desvio Padrão: {desvio_padrao:.2f}")
print(f"Mínimo: {minimo}")
print(f"Máximo: {maximo}")
Saída do Código:
Média: 3.00
Variância: 2.00
Desvio Padrão: 1.41
Mínimo: 1
Máximo: 5
Trabalhando com Arquivos#
O NumPy oferece funções simples e eficientes para salvar e carregar arrays. Essas ferramentas são essenciais para armazenar grandes volumes de dados numéricos ou compartilhar arrays entre diferentes programas.
Tabela de Funções para Manipulação de Arquivos
Função |
Descrição |
|---|---|
|
Salva um array NumPy em um arquivo binário no formato |
|
Carrega um array salvo previamente no formato |
Salvando Arrays com np.save
A função np.save permite salvar um array em um arquivo binário. O formato .npy garante a preservação da estrutura e do tipo de dados do array.
Exemplo Prático:
import numpy as np
# Criando um array
array_to_save = np.array([1, 2, 3, 4, 5])
# Salvando o array em um arquivo
np.save('array_salvo', array_to_save)
Após a execução, será gerado um arquivo chamado array_salvo.npy no diretório atual.
Carregando Arrays com np.load
A função np.load é usada para recuperar arrays previamente salvos. Isso é especialmente útil para reutilizar dados armazenados sem recriá-los manualmente.
Exemplo Prático:
import numpy as np
# Carregando o array salvo
loaded_array = np.load('array_salvo.npy')
# Exibindo o array carregado
print("Array Carregado:", loaded_array)
Saída do Código:
Array Carregado: [1 2 3 4 5]
Matplotlib - Visualização de Dados#
A visualização de dados transforma números em representações visuais que revelam padrões e tendências e facilitam a comunicação de resultados. O Matplotlib, criado por John D. Hunter em 2003, é a biblioteca de visualização mais usada em Python e um padrão na comunidade científica.
Com ele é possível criar praticamente qualquer tipo de gráfico (linhas, barras, dispersão, histogramas, pizza, mapas de calor, 3D, entre outros), personalizar cada detalhe (cores, estilos, rótulos, anotações) e exportar em formatos como PNG, PDF e SVG. Além disso, integra-se de forma natural com NumPy, Pandas, Seaborn e Scikit-learn, o que o torna peça central no fluxo de análise de dados.
Anatomia de um Gráfico#
O Matplotlib organiza um gráfico em duas estruturas: a Figure (a imagem inteira) e os Axes (a área onde os dados são desenhados, junto com seus eixos). Usando a interface pyplot, o fluxo de criação é quase sempre o mesmo:
Prepare os dados (listas ou arrays);
Escolha o tipo de gráfico (
plt.plot,plt.bar,plt.scatter, …);Configure título, rótulos dos eixos, legenda e grade;
Exiba com
plt.show()(ou salve complt.savefig).
A figura a seguir identifica as principais partes de um gráfico:
import matplotlib.pyplot as plt
import numpy as np
x = np.arange(1, 8)
y = np.array([2, 3, 5, 4, 6, 7, 6])
plt.figure(figsize=(8, 5))
plt.plot(x, y, marker='o', color='steelblue', label='Série de dados (legenda)')
plt.title('Título do Gráfico (title)')
plt.xlabel('Rótulo do eixo X (xlabel)')
plt.ylabel('Rótulo do eixo Y (ylabel)')
plt.legend(loc='upper left')
plt.grid(True, linestyle='--', alpha=0.5)
# Anotações apontando partes do gráfico
plt.annotate('marcador', xy=(3, 5), xytext=(2.0, 3.4), arrowprops=dict(arrowstyle='->'))
plt.annotate('linha', xy=(5.5, 6.5), xytext=(5.8, 5.0), arrowprops=dict(arrowstyle='->'))
plt.annotate('grade (grid)', xy=(6, 4), xytext=(4.2, 2.4), arrowprops=dict(arrowstyle='->'))
plt.show()
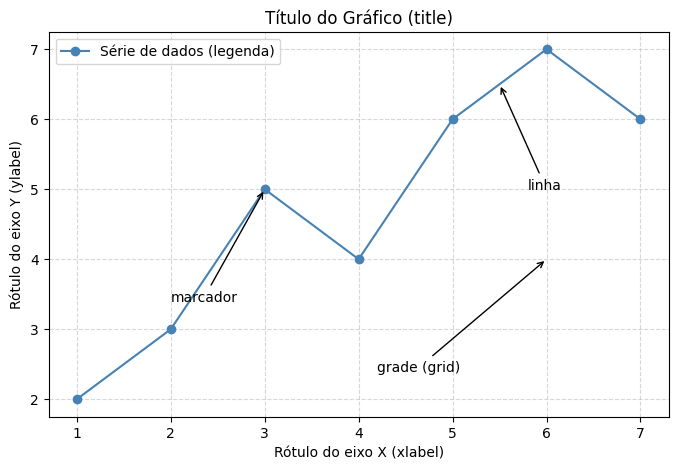
Um Primeiro Gráfico#
O exemplo abaixo aplica esse fluxo para criar um gráfico de linha simples:
# Importando a biblioteca Matplotlib
import matplotlib.pyplot as plt
# Definindo os dados para os eixos X e Y
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
# Criando o gráfico de linha
plt.plot(x, y)
# Adicionando rótulo ao eixo X
plt.xlabel('Eixo X')
# Adicionando rótulo ao eixo Y
plt.ylabel('Eixo Y')
# Adicionando título ao gráfico
plt.title('Gráfico de Linha Simples')
# Exibindo o gráfico
plt.show()
Gráfico de Linha: Vendas Acumuladas ao Longo do Mês#
Este exemplo cria um gráfico de linha mostrando as vendas acumuladas de uma loja ao longo de 30 dias. A biblioteca NumPy é usada para gerar dados fictícios para ilustração.
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(42)
# Dados fictícios: vendas acumuladas ao longo de 30 dias
dias = np.arange(1, 31)
vendas = np.random.randint(100, 1000, size=30).cumsum()
# Gráfico de linha com marcadores
plt.plot(dias, vendas, marker='o', color='b', label='Vendas diárias')
plt.xlabel('Dias')
plt.ylabel('Vendas acumuladas')
plt.title('Vendas Acumuladas ao Longo do Mês')
plt.legend()
plt.show()
Gráfico de Barras: Distribuição de Renda no Brasil#
Neste exemplo, um gráfico de barras é utilizado para representar a distribuição de renda no Brasil. Os dados são fictícios e representam percentuais da população em diferentes faixas de renda.
import matplotlib.pyplot as plt
# Dados fictícios para ilustração
faixas_renda = ['0-999', '1000-1999', '2000-2999', '3000-3999', '4000+']
percentuais = [20, 30, 25, 15, 10]
# Criando o gráfico de barras
plt.bar(faixas_renda, percentuais, color='green')
# Adicionando rótulos e título
plt.xlabel('Faixas de Renda')
plt.ylabel('Percentual da População')
plt.title('Distribuição de Renda no Brasil')
# Exibindo o gráfico
plt.show()
Gráfico de Dispersão: Correlação entre Duas Variáveis#
Este exemplo utiliza um gráfico de dispersão para visualizar a correlação entre duas variáveis fictícias: horas de estudo e desempenho em provas.
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(42) # mesmas figuras a cada execução
# Dados fictícios para ilustração
horas_estudo = np.random.uniform(1, 10, size=50)
desempenho_exames = 70 + 2 * horas_estudo + np.random.normal(0, 2, size=50)
# Criando o gráfico de dispersão
plt.scatter(horas_estudo, desempenho_exames, color='red', alpha=0.7)
# Adicionando rótulos e título
plt.xlabel('Horas de Estudo')
plt.ylabel('Desempenho em Exames')
plt.title('Correlação entre Horas de Estudo e Desempenho em Exames')
# Exibindo o gráfico
plt.show()
Histograma: Distribuição de uma Variável#
Neste exemplo, um histograma é utilizado para representar a distribuição de idades em uma amostra de pessoas.
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(42) # mesmas figuras a cada execução
# Dados fictícios para ilustração
idades = np.random.normal(30, 5, size=1000)
# Criando o histograma
plt.hist(idades, bins=20, color='purple', edgecolor='black')
# Adicionando rótulos e título
plt.xlabel('Idade')
plt.ylabel('Frequência')
plt.title('Distribuição de Idades')
# Exibindo o gráfico
plt.show()
Múltiplos Gráficos: Subplots#
Muitas vezes queremos exibir vários gráficos lado a lado, em uma única figura. A função plt.subplots(linhas, colunas) cria uma Figure e uma grade de Axes; cada Axes é configurado de forma independente com métodos como .plot(), .set_title() e .set_xlabel().
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(42)
# Cria uma figura com 1 linha e 2 colunas de gráficos
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 4))
# Gráfico da esquerda: linha
x = np.linspace(0, 10, 100)
ax1.plot(x, np.sin(x), color='blue')
ax1.set_title('Função Seno')
ax1.set_xlabel('x')
ax1.set_ylabel('sen(x)')
# Gráfico da direita: histograma
ax2.hist(np.random.normal(0, 1, 500), bins=20, color='green', edgecolor='black')
ax2.set_title('Distribuição Normal')
ax2.set_xlabel('Valor')
ax2.set_ylabel('Frequência')
# Ajusta automaticamente o espaçamento entre os gráficos
plt.tight_layout()
plt.show()
Trabalhando com Imagens#
Matplotlib não é apenas para gráficos e plots; também é uma ferramenta poderosa para manipulação e visualização de imagens.
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
# Define o caminho para a imagem local
caminho_imagem = "ch7.jpeg" # Imagem na mesma pasta do arquivo .py
# Lê a imagem como um array numpy
img = mpimg.imread(caminho_imagem)
# Cria uma nova figura
plt.figure(figsize=(10, 8))
# Exibe a imagem
plt.imshow(img)
# Adiciona um título
plt.title("Minha Imagem Local")
# Remove os eixos
plt.axis('off')
# Mostra a figura
plt.show()

Também podemos manipular uma imagem, já que o Matplotlib a representa como um array do NumPy. No exemplo a seguir, carregamos uma foto de domínio público de Alan Turing (um dos pais da computação) e aplicamos um efeito de negativo, exibindo a original e o resultado lado a lado.
A imagem está disponível para download: alan_turing.jpg. Baixe-a e salve na mesma pasta do seu notebook para reproduzir o exemplo.
{kind=link}
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
# Lê a imagem (em tons de cinza) que está na mesma pasta do notebook
imagem = mpimg.imread('alan_turing.jpg')
# Efeito de negativo: inverte os tons (a imagem é um array, então basta subtrair)
negativo = 255 - imagem
# Exibe a original e o negativo lado a lado
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(8, 5))
ax1.imshow(imagem, cmap='gray')
ax1.set_title('Original')
ax1.axis('off')
ax2.imshow(negativo, cmap='gray')
ax2.set_title('Negativo')
ax2.axis('off')
plt.show()

Dica - Imagens de Uso Livre
Ao usar imagens em seus projetos, prefira conteúdo com licença livre (domínio público, Creative Commons etc.). O Wikimedia Commons reúne milhões de imagens de uso livre. A foto de Alan Turing acima é de domínio público.
Salvando Gráficos como Figuras#
A biblioteca Matplotlib oferece uma maneira descomplicada de salvar gráficos em diversos formatos, como PNG, PDF, SVG e JPEG. Como exemplo, vamos criar um scatter plot.
import matplotlib.pyplot as plt
import numpy as np
# Dados para o scatter plot
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
# Ajustar a cor e tamanho dos pontos com base nos valores de Y
colors = np.arange(len(y))
sizes = [40 * val for val in y]
# Criar um scatter plot personalizado
plt.scatter(x, y, c=colors, s=sizes, cmap='viridis', edgecolor='black', alpha=0.7, label='Pontos de Exemplo')
plt.colorbar(label='Valores de Y')
plt.xlabel('Eixo X')
plt.ylabel('Eixo Y')
plt.title('Scatter Plot Didático')
# Adicionar uma linha de tendência
plt.plot(x, np.poly1d(np.polyfit(x, y, 1))(x), color='orange', linestyle='--', label='Linha de Tendência')
# Adicionar legenda
plt.legend()
# Adicionar grade para melhor visualização
plt.grid(True)
# Salvar o scatter plot como arquivo PNG
plt.savefig('scatter_plot.png')
# Exibir o scatter plot
plt.show()
Para salvar, utilizamos a função savefig(), indicando o nome do arquivo com a extensão desejada. Para outros formatos, mude a extensão do nome:
plt.savefig('scatter_plot.pdf')
plt.savefig('scatter_plot.svg')
plt.savefig('scatter_plot.jpg')
A resolução padrão será utilizada, mas você pode ajustá-la conforme necessário com o argumento dpi. Este processo oferece uma maneira eficiente de preservar visualizações geradas em Python para uso futuro, compartilhamento ou inclusão em documentos e apresentações.
Exercícios#
Analisando Coleta de Temperaturas
Você é um cientista de dados trabalhando em um conjunto de dados de temperaturas diárias coletadas ao longo de uma semana. As temperaturas foram registradas em graus Celsius e estão organizadas em um array NumPy.
Dados:
import numpy as np
temperaturas = np.array([
[25.5, 26.1, 27.8, 28.3, 27.9, 26.8, 25.9], # Domingo
[24.8, 25.3, 26.5, 27.1, 26.7, 25.6, 24.9], # Segunda
[23.9, 24.5, 25.8, 26.4, 26.0, 24.9, 24.1], # Terça
[24.2, 24.8, 26.1, 26.7, 26.3, 25.2, 24.4], # Quarta
[25.1, 25.7, 27.0, 27.6, 27.2, 26.1, 25.3], # Quinta
[26.0, 26.6, 28.1, 28.7, 28.3, 27.2, 26.3], # Sexta
[25.4, 26.0, 27.5, 28.0, 27.6, 26.5, 25.7] # Sábado
])
Suas tarefas são:
Calcular a temperatura média diária da semana.
Encontrar a temperatura máxima e mínima da semana.
Calcular a diferença entre a temperatura máxima e mínima de cada dia da semana.
# Teste
Entrada: Considere os dados apresentados no enunciado
Saída:
Temperatura média diária da semana:
Dia 1: 26.90°C
Dia 2: 25.84°C
Dia 3: 25.09°C
Dia 4: 25.39°C
Dia 5: 26.29°C
Dia 6: 27.31°C
Dia 7: 26.67°C
Temperatura máxima da semana: 28.70°C
Temperatura mínima da semana: 23.90°C
Diferença entre temperatura máxima e mínima de cada dia:
Dia 1: 2.80°C
Dia 2: 2.30°C
Dia 3: 2.50°C
Dia 4: 2.50°C
Dia 5: 2.50°C
Dia 6: 2.70°C
Dia 7: 2.60°C
Análise de Ondas Sonoras
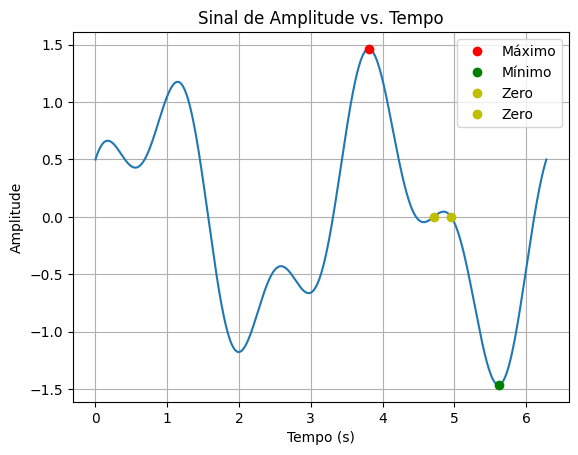
Você é um engenheiro de áudio trabalhando em um projeto de análise de ondas sonoras. Você tem um conjunto de dados que representa as amplitudes de uma onda sonora em diferentes pontos no tempo. Sua tarefa é analisar esses dados usando funções matemáticas do NumPy.
import numpy as np
# Dados: tempo em segundos e amplitudes correspondentes
tempo = np.linspace(0, 2*np.pi, 1000)
amplitudes = np.sin(2*tempo) + 0.5*np.cos(5*tempo)
Tarefas:
Calcule o valor máximo e mínimo das amplitudes.
Encontre os pontos de tempo onde a amplitude é próxima de zero (use
np.wherecomnp.isclosepara considerar uma tolerância deatol=1e-3).Calcule a energia total do sinal (soma dos quadrados das amplitudes).
Arredonde todos os resultados para 4 casas decimais e imprima os resultados de cada tarefa.
Opcionalmente, você pode plotar os gráficos utilizando o matplotlib para visualizar os resultados.
# Teste
Entrada: Utilize os dados apresentados no enunciado.
Saída:
Amplitude máxima: 1.4627
Amplitude mínima: -1.4628
Pontos de tempo onde a amplitude é próxima de zero:
4.7108 segundos
4.9561 segundos
Energia total do sinal: 624.6250
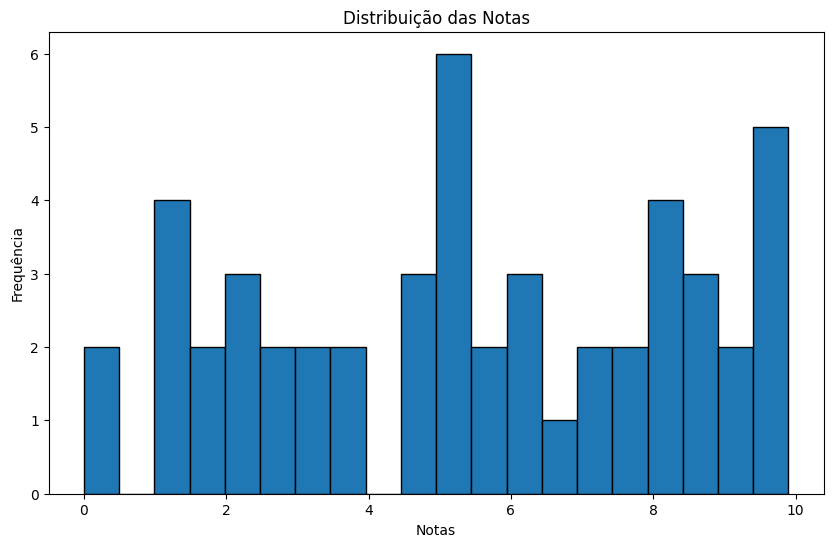
Cálculo de Médias e Desvios Padrão
Desenvolva um programa que analisa as notas de uma turma de alunos em uma disciplina. O objetivo é gerar um relatório estatístico básico que inclua a média, a variância e o desvio padrão das notas dos alunos.
Implemente uma função usando o NumPy para calcular as seguintes estatísticas:
Média das notas: A média aritmética das notas.
Variância das notas: A medida de dispersão que indica o quão espalhadas as notas estão em relação à média.
Desvio padrão das notas: A raiz quadrada da variância, que fornece uma medida da dispersão das notas em relação à média.
Implemente uma outra função para imprimir o relatório final no seguinte formato:
“Média das notas: X.XX”
“Variância das notas: X.XX”
“Desvio padrão das notas: X.XX”
Onde X.XX deve ser substituído pelos valores calculados, arredondados para duas casas decimais.
Opcionalmente, você pode plotar um histograma para visualizar a distribuição das notas usando a biblioteca matplotlib.
# Teste
Entrada:
6.3, 9.5, 1.7, 9.1, 8.2, 1.8, 0.4, 7.4, 4.6, 7.7, 8.1, 1.4, 3.8, 6.6, 7.6, 3.4, 3.8, 9.3, 9.9, 2.5, 6.3, 5.1, 5.4, 1.1, 4.5, 2.4, 8.7, 9.9, 2.0, 5.1, 8.0, 5.3, 1.0, 1.3, 8.5, 5.6, 4.7, 0.0, 6.0, 3.2, 2.2, 9.5, 9.7, 5.1, 5.6, 5.4, 8.7, 7.1, 2.6, 8.3
Saída:
Média: 5.43
Variância: 8.37
Desvio padrão: 2.89
Operações Algébricas em Matrizes
Neste exercício, você irá implementar operações algébricas fundamentais em matrizes utilizando a biblioteca NumPy. O objetivo é consolidar o entendimento sobre multiplicação, soma, transposição, inversão de matrizes e cálculo de determinantes.
Instruções
Geração das Matrizes
Crie duas matrizes quadradas \(A\) e \(B\) de dimensões \(3 \times 3\), preenchidas com números inteiros aleatórios entre 1 e 10.
Defina uma semente aleatória recebida como entrada para garantir a reprodutibilidade dos resultados. Utilize a função
numpy.random.seedpara configurar a semente, seguida pornumpy.random.randintpara gerar as matrizes.
Operações Algébricas
a) Soma das Matrizes: Calcule a soma \(C = A + B\).
b) Produto das Matrizes: Calcule o produto matricial \(D = A \cdot B\) (multiplicação matricial).
c) Transposição: Encontre a transposta da matriz \(D\), denotada por \(D^T\).
d) Determinante: Calcule o determinante de \(D\) utilizando
numpy.linalg.det.e) Inversão de Matriz:
Verifique se \(D\) é invertível (determinante diferente de zero).
Se for, calcule sua inversa \(D^{-1}\) usando
numpy.linalg.inv.Caso contrário, informe que \(D\) não possui inversa.
Relatório Final Implemente uma função para exibir os resultados das operações em um relatório formatado da seguinte forma:
Relatório:
Matriz A: \( \begin{bmatrix} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \\ a_{31} & a_{32} & a_{33} \end{bmatrix} \)
Matriz B: (Formato semelhante ao de \(A\)).
Matriz C (A + B): Resultado da soma.
Matriz D (A \cdot B): Resultado da multiplicação matricial.
Matriz D Transposta: Resultado de \(D^T\).
Determinante de D: Valor do determinante.
Inversa de D: Mostre \(D^{-1}\) se existir, ou exiba “Matriz não invertível.”
Exemplo de Saída
# Teste com semente 42
np.random.seed(42)
A = np.random.randint(1, 11, (3, 3))
B = np.random.randint(1, 11, (3, 3))
Saída:
Matriz A:
[[ 7 4 8]
[ 5 7 10]
[ 3 7 8]]
Matriz B:
[[5 4 8]
[8 3 6]
[5 2 8]]
Matriz C (A + B):
[[12 8 16]
[13 10 16]
[ 8 9 16]]
Matriz D (A @ B):
[[107 56 144]
[131 61 162]
[111 49 130]]
Matriz D Transposta:
[[107 131 111]
[ 56 61 49]
[144 162 130]]
Determinante de D: 1768.00
Inversa de D:
[[-0.0045 -0.1267 0.1629]
[ 0.5385 -1.1731 0.8654]
[-0.1991 0.5503 -0.4576]]
Dicas
Utilize
np.isclosepara comparar o determinante com zero, evitando erros de precisão numérica.Teste o código com diferentes valores de semente para verificar a robustez da implementação.
Utilize
np.dotou o operador@para realizar a multiplicação matricial.