Capítulo 6: Manipulação de Strings#

Introdução às Strings#
As strings são um dos tipos de dados mais comuns e versáteis na programação. Este capítulo revisará conceitos introdutórios e expandirá o uso de strings em Python, ajudando você a dominá-las para aplicações práticas no desenvolvimento.
Para mais detalhes técnicos sobre strings em Python, você pode consultar a PEP 498 - Literal String Interpolation, que introduz f-strings, uma das formas mais eficientes de formatar strings.
Documentação Oficial - Strings
Consulte também a documentação oficial sobre strings para a lista completa de métodos e operações disponíveis.
O que são strings?#
Strings são sequências de caracteres usadas para representar texto em programação. Em Python, elas podem conter letras, números, símbolos e espaços. Strings são delimitadas por aspas (simples ou duplas) e podem ter qualquer comprimento, desde uma única letra até textos extensos.
Exemplo de string:
"Olá, Mundo!"
Do teclado à string
Cada tecla do teclado corresponde a um caractere que pode entrar em uma string. Pense nas teclas como peças individuais e a string como uma sequência delas em uma ordem específica:
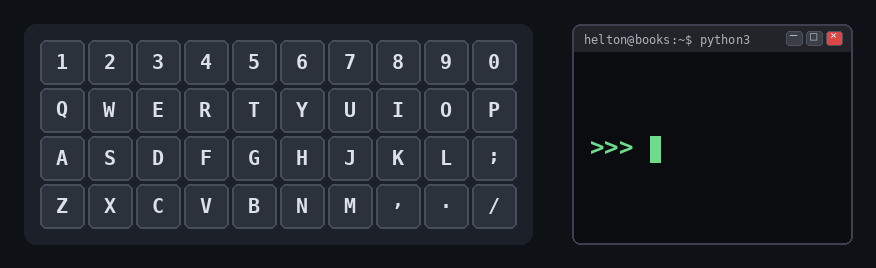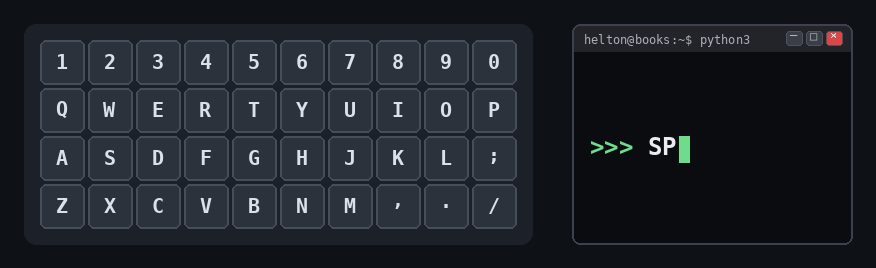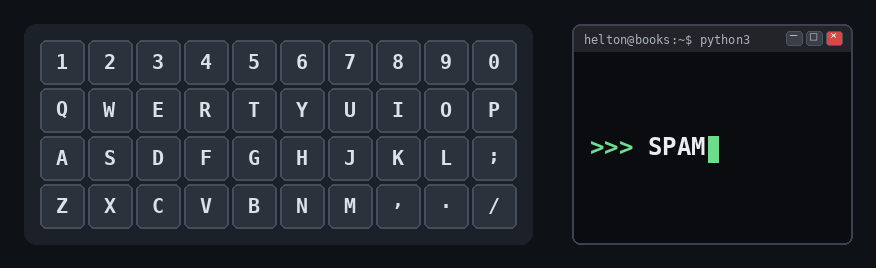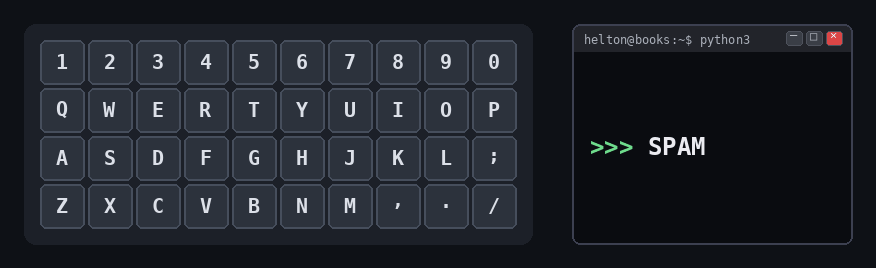
Curiosidade - Por que SPAM?
A palavra SPAM que aparece na animação não é aleatória: ela é o placeholder oficial nos exemplos da documentação Python (no lugar de foo/bar). A linguagem foi batizada em homenagem ao grupo britânico de comédia Monty Python’s Flying Circus, famoso por um esquete sobre o presunto enlatado de mesmo nome.
Para ler texto digitado pelo usuário em tempo de execução, use a função input():
nome = input("Digite seu nome: ")
print(f"Olá, {nome}!")
A função input() espera o usuário digitar algo, pressionar Enter, e devolve uma string com tudo que foi digitado. O valor retornado é sempre uma string, mesmo que o usuário digite apenas números: você recebe "42" (string), não 42 (inteiro). Para usar como número, é preciso converter com int() ou float().
Códigos ASCII: o número por trás do caractere
No nível mais baixo, o computador armazena cada caractere como um número inteiro, mas para que A signifique 65 em qualquer máquina é preciso um padrão. Nos primórdios da computação, cada fabricante usava sua própria codificação (a IBM, por exemplo, usava a EBCDIC), e arquivos enviados entre computadores diferentes viravam texto ilegível. A ASCII (American Standard Code for Information Interchange), publicada em 1963, resolveu isso: 128 códigos (de 0 a 127) acordados por todos os fabricantes. Até hoje a ASCII é a base de praticamente toda codificação de texto, incluindo Unicode. A tabela completa, organizada em colunas de 16 em 16, é:
Dec Chr Dec Chr Dec Chr Dec Chr Dec Chr Dec Chr Dec Chr Dec Chr
0 NUL 16 DLE 32 SP 48 0 64 @ 80 P 96 ` 112 p
1 SOH 17 DC1 33 ! 49 1 65 A 81 Q 97 a 113 q
2 STX 18 DC2 34 " 50 2 66 B 82 R 98 b 114 r
3 ETX 19 DC3 35 # 51 3 67 C 83 S 99 c 115 s
4 EOT 20 DC4 36 $ 52 4 68 D 84 T 100 d 116 t
5 ENQ 21 NAK 37 % 53 5 69 E 85 U 101 e 117 u
6 ACK 22 SYN 38 & 54 6 70 F 86 V 102 f 118 v
7 BEL 23 ETB 39 ' 55 7 71 G 87 W 103 g 119 w
8 BS 24 CAN 40 ( 56 8 72 H 88 X 104 h 120 x
9 HT 25 EM 41 ) 57 9 73 I 89 Y 105 i 121 y
10 LF 26 SUB 42 * 58 : 74 J 90 Z 106 j 122 z
11 VT 27 ESC 43 + 59 ; 75 K 91 [ 107 k 123 {
12 FF 28 FS 44 , 60 < 76 L 92 \ 108 l 124 |
13 CR 29 GS 45 - 61 = 77 M 93 ] 109 m 125 }
14 SO 30 RS 46 . 62 > 78 N 94 ^ 110 n 126 ~
15 SI 31 US 47 / 63 ? 79 O 95 _ 111 o 127 DEL
Repare na estrutura por blocos:
0-31 e 127: caracteres de controle (não imprimíveis), usados historicamente para comandos de terminal e impressoras. Os mais úteis em strings Python têm sequências de escape:
\0(NUL, 0),\t(HT/tabulação, 9),\n(LF/nova linha, 10),\r(CR/retorno ao início da linha, 13).32: o espaço (
SP).33-47, 58-64, 91-96, 123-126: pontuação e símbolos.
48-57: dígitos
0a9.65-90: letras maiúsculas
AaZ.97-122: letras minúsculas
aaz.
Em Python, as funções embutidas ord() e chr() convertem entre caractere e código:
print(ord('A')) # 65: código do caractere 'A'
print(chr(65)) # 'A': caractere do código 65
# Caracteres consecutivos têm códigos consecutivos:
for codigo in range(65, 71):
print(codigo, chr(codigo))
Saída do Código:
65
A
65 A
66 B
67 C
68 D
69 E
70 F
Repare na ordenação: letras maiúsculas ocupam os códigos 65 a 90 e minúsculas, 97 a 122. A diferença constante de 32 entre uma letra e sua versão maiúscula/minúscula é exatamente o que métodos como .upper() e .lower() exploram por baixo dos panos.
Nota - ASCII, Unicode e Acentos
ASCII cobre apenas 128 caracteres, suficiente para o inglês básico. Para acentos (á, ç), emojis e outros alfabetos, Python usa Unicode (codificado em UTF-8 por padrão), que abrange mais de 140 mil caracteres. As funções ord() e chr() continuam funcionando: ord('á') retorna 225 e ord('🐍') retorna 128013.
Criando strings#
Em Python, uma string pode ser delimitada por aspas simples ('), aspas duplas (") ou aspas triplas (''' ou """). As três formas produzem o mesmo tipo str, mas cada uma tem um caso de uso natural.
Aspas simples ou duplas são intercambiáveis. A escolha entre elas costuma ser pela conveniência: você usa uma das duas para delimitar a string e a outra dentro dela, sem precisar de escape.
frase1 = 'Ele disse: "Python é incrível!"'
frase2 = "Ele disse: 'Python é incrível!'"
print(frase1)
print(frase2)
Saída do Código:
Ele disse: "Python é incrível!"
Ele disse: 'Python é incrível!'
Aspas triplas servem para strings que ocupam várias linhas, preservando as quebras de linha sem precisar de \n:
mensagem = """Este é um exemplo de string
que ocupa várias linhas. É bastante útil."""
print(mensagem)
Saída do Código:
Este é um exemplo de string
que ocupa várias linhas. É bastante útil.
Dica - Consistência no Uso de Aspas
Embora aspas simples e duplas sejam equivalentes, escolha um estilo padrão e mantenha-o ao longo do código, alternando apenas quando o conteúdo da string exigir. A PEP 8 não impõe uma escolha, mas recomenda consistência dentro de um mesmo projeto.
Indexação e Fatiamento de Strings#
Strings em Python podem ser tratadas como sequências de caracteres, e cada caractere na string tem um índice numérico associado. A indexação e o fatiamento de strings permitem acessar e manipular caracteres individuais ou substrings dentro de uma string.
Acessando caracteres individuais em uma string#
Cada caractere em uma string tem um índice numérico, começando do zero. Você pode acessar um caractere específico em uma string usando colchetes [] e fornecendo o índice do caractere desejado.
Exemplo:
string = "Python"
primeiro_caractere = string[0]
ultimo_caractere = string[5]
print(primeiro_caractere)
print(ultimo_caractere)
Saída do Código:
P
n
Atenção - Índices Fora do Intervalo
Acessar um índice maior ou igual ao tamanho da string (ou menor que -len(string)) gera um IndexError. Sempre verifique o tamanho com len() antes de acessar uma posição específica, principalmente quando o índice vem de uma variável.
Fatiamento de strings#
O fatiamento de strings permite extrair uma substring de uma string maior. Você pode especificar um intervalo de índices para obter uma substring. A sintaxe para fatiamento é [início:fim], onde início é o índice do primeiro caractere da substring e fim é o índice do caractere após o último caractere desejado.
Exemplo:
string = "Python é incrível!"
substring = string[9:17]
print(substring)
Saída do Código:
incrível
Exemplo:
string = "Aprender Python"
substring = string[0:8]
print(substring)
Saída do Código:
Aprender
Nota - Fatiamento com Passo
O fatiamento aceita uma terceira parte opcional, o passo: [início:fim:passo]. Por exemplo, "Python"[::2] retorna "Pto" (pulando de 2 em 2) e "Python"[::-1] retorna "nohtyP" (invertendo a string). Esse recurso será muito útil em listas e sequências mais à frente.
Indexação negativa#
Python também permite o uso de índices negativos para acessar caracteres a partir do final da string. O índice -1 refere-se ao último caractere, -2 ao penúltimo, e assim por diante.
Exemplo:
string = "Python"
ultimo_caractere = string[-1]
penultimo_caractere = string[-2]
print(ultimo_caractere)
print(penultimo_caractere)
Saída do Código:
n
o
Exemplo:
string = "Indexação negativa"
substring = string[-8:]
print(substring)
Saída do Código:
negativa
Exemplo com fatiamento intermediário (positivo e negativo)
Considere uma string que representa um número de telefone:
telefone = "(84) 91234-5678"
Queremos extrair a parte “91234”, que está no meio da string.
Usando indexação positiva:
numero_meio = telefone[5:10]
print(numero_meio)
Usando indexação negativa:
numero_meio = telefone[-10:-5]
print(numero_meio)
Saída do Código:
91234
Dica - Quando Preferir Índices Negativos
Use índices negativos quando souber a posição contando a partir do final da string, mas não souber (ou não importar) o tamanho total. Por exemplo, arquivo[-4:] extrai a extensão .txt sem precisar calcular len(arquivo) - 4.
Formatação de Strings#
A formatação de strings é uma tarefa comum na programação, especialmente ao exibir informações para os usuários. Com as versões mais recentes do Python, há ferramentas modernas e eficientes que oferecem flexibilidade e legibilidade na formatação de texto. As duas abordagens mais usadas atualmente são as f-strings e o método str.format().
Usando f-strings#
As f-strings (ou strings formatadas) foram introduzidas no Python 3.6 e são uma maneira prática e eficiente de formatar strings. Elas permitem inserir variáveis, expressões ou até mesmo chamadas de funções diretamente dentro da string, com uma sintaxe clara e legível. Para usar uma f-string, basta prefixar a string com a letra f ou F e incluir as expressões dentro de chaves {}.
Exemplo básico:
saudação = "Olá"
nome = "Alana"
resultado = f"{saudação}, {nome}!"
print(resultado)
Saída do Código:
Olá, Alana!
Exemplo com expressões:
a = 5
b = 3
resultado = f"O resultado de {a} + {b} é {a + b}."
print(resultado)
Saída do Código:
O resultado de 5 + 3 é 8.
As f-strings também permitem especificar formatações avançadas, como precisão de números decimais, alinhamento de texto e preenchimento de espaços.
Exemplo com formatação:
valor = 123.45678
print(f"O valor formatado é {valor:.2f}.")
Saída do Código:
O valor formatado é 123.46.
Trabalhando com expressões#
preco = 99.90
desconto = 0.1
mensagem = f"O preço com desconto é {preco * (1 - desconto):.2f}."
print(mensagem)
Saída do Código:
O preço com desconto é 89.91.
Formatação com :.2f
O formato :.2f em f-strings é usado para formatar números diretamente dentro das chaves {}. Ele funciona assim:
:Inicia a formatação..2Limita o número a duas casas decimais.fEspecifica que o número é um ponto flutuante (float).
Chamadas de funções#
Dentro das chaves {} você pode chamar métodos e funções diretamente, sem precisar criar variáveis intermediárias. Isso deixa o código mais conciso quando o valor precisa ser transformado antes de aparecer no texto.
texto = "python"
mensagem = f"O texto em maiúsculas é {texto.upper()}."
print(mensagem)
Saída do Código:
O texto em maiúsculas é PYTHON.
Qualquer expressão Python válida pode aparecer dentro das chaves: {len(nome)}, {lista[0]}, {round(media, 2)}, e assim por diante.
Alinhamento e largura#
Para gerar tabelas, relatórios ou qualquer saída em colunas, você pode reservar uma largura mínima para o valor e escolher como ele será posicionado dentro desse espaço. A sintaxe é {valor:[alinhamento][largura]}, onde o alinhamento é um destes símbolos:
<: Alinha à esquerda (padrão para strings).^: Centraliza.>: Alinha à direita (padrão para números).
nome = "João"
idade = 28
mensagem = f"|{nome:<10}|{idade:^6}|{idade:>5}|"
print(mensagem)
Saída do Código:
|João | 28 | 28|
No exemplo, nome ocupa 10 caracteres alinhado à esquerda e idade aparece duas vezes: primeiro centralizada em 6 caracteres, depois alinhada à direita em 5. Se o valor for maior que a largura definida, ele aparece inteiro, sem ser cortado.
Juntando vários recursos num único print#
O verdadeiro poder das f-strings aparece quando você combina chamada de método, expressão, alinhamento, largura, separador de milhar, casas decimais, percentual e zeros à esquerda numa só linha. É o que transforma um único print numa linha completa de relatório:
produto = "spam"
codigo = 42
estoque = 1287
preco = 9.99
desconto = 0.20
print(f"| {produto.upper():^10} | #{codigo:05d} | {estoque:>5,} un | R$ {preco * (1 - desconto):>6.2f} (-{desconto:.0%}) |")
Saída do Código:
| SPAM | #00042 | 1,287 un | R$ 7.99 (-20%) |
Quebrando cada pedaço entre as chaves:
{produto.upper():^10}→ chama o método.upper()e centraliza o resultado em 10 caracteres.{codigo:05d}→ formata o inteiro com 5 dígitos, preenchendo com zeros à esquerda.{estoque:>5,}→ alinha à direita em 5 caracteres e adiciona separador de milhar.{preco * (1 - desconto):>6.2f}→ avalia uma expressão (preço já com desconto), alinha à direita em 6 e mostra 2 casas decimais.{desconto:.0%}→ converte o número para percentual sem casas decimais.
Esse é o padrão que sustenta tabelas, recibos e relatórios direto no terminal, sem precisar de bibliotecas externas.
Formatando números em diferentes estilos#
Você pode usar f-strings para exibir números de formas variadas e legíveis. Cada formato resolve um problema diferente, veja três cenários comuns:
Valores monetários — separador de milhar e duas casas decimais
faturamento = 1250789.5
print(f"Faturamento anual: R$ {faturamento:,.2f}")
Saída do Código:
Faturamento anual: R$ 1,250,789.50
Valores muito grandes ou muito pequenos — notação científica
distancia_terra_sol_km = 149597871
massa_eletron_kg = 9.10938e-31
print(f"Distância Terra-Sol: {distancia_terra_sol_km:.2e} km")
print(f"Massa do elétron: {massa_eletron_kg:.2e} kg")
Saída do Código:
Distância Terra-Sol: 1.50e+08 km
Massa do elétron: 9.11e-31 kg
Códigos e identificadores — zeros à esquerda
codigo_pedido = 42
print(f"Pedido nº {codigo_pedido:06d}")
Saída do Código:
Pedido nº 000042
Explicando:
:,→ Adiciona separador de milhar (por padrão, vírgula)..2f→ Mostra duas casas decimais com ponto fixo..2e→ Formata em notação científica com duas casas decimais.06d→ Converte para inteiro com 6 dígitos, preenchendo com zeros à esquerda se necessário (use08d,010d, etc. para outros tamanhos).
Nota - Outras Formas de Formatação (Legado)
Em códigos mais antigos você ainda encontra o método str.format() ("Olá, {}".format(nome)) e o operador % ("Olá, %s" % nome). Saber identificá-los é útil para ler código existente, mas em código novo prefira f-strings, que são mais legíveis e eficientes.
Operações com Strings#
As strings oferecem uma ampla gama de operações que podem ser realizadas para manipulação e análise de texto. Nesta seção, exploraremos algumas operações comuns com strings: concatenação, repetição e comparação.
Concatenando strings#
A concatenação de strings é o processo de unir duas ou mais strings em uma única string. Isso pode ser feito de várias maneiras:
Usando o operador +: O operador + é utilizado para concatenar duas ou mais strings.
string1 = "Olá,"
string2 = "Pessoal!"
resultado = string1 + " " + string2
print(resultado)
Saída do Código:
Olá, Pessoal!
Usando o método join(): O método join() pode ser utilizado para concatenar uma lista de strings com um delimitador específico.
palavras = ["Olá", "Pessoal"]
resultado = " ".join(palavras) # Delimitador de espaço nesse caso
print(resultado)
Saída do Código:
Olá Pessoal
O separador pode ser qualquer string. Trocar " " por ", " produz uma listagem no estilo de uma frase, útil para mostrar itens ao usuário:
ingredientes = ["ovo", "bacon", "spam", "spam"]
resultado = ", ".join(ingredientes) # Vírgula e espaço como separador
print(resultado)
Saída do Código:
ovo, bacon, spam, spam
Outros separadores comuns são "\n" (uma linha por item), "/" (caminhos), " | " (colunas) e "" (concatenação pura, sem nada entre os itens).
Repetindo strings#
Repetir strings é um processo simples que pode ser realizado usando o operador *. Este operador multiplica a string pelo número de vezes especificado.
Exemplo:
string = "Oi! "
repetida = string * 3
print(repetida)
Saída do Código:
Oi! Oi! Oi!
Um uso clássico dessa operação é desenhar barras de progresso, separadores e indicadores visuais direto no terminal, sem precisar de bibliotecas externas. Combinando * com f-strings dá para fazer uma barra de progresso completa em poucas linhas:
progresso = 0.7 # 70% concluído
total = 20 # largura da barra em caracteres
preenchido = int(progresso * total)
barra = "█" * preenchido + "░" * (total - preenchido)
print(f"[{barra}] {progresso:.0%}")
Saída do Código:
[██████████████░░░░░░] 70%
A mesma ideia serve para imprimir linhas separadoras (print("=" * 50)), recuos (" " * nivel) ou pequenas decorações em cabeçalhos.
E para realmente ver a barra se preenchendo, é só colocar o código dentro de um loop, atualizar o estado a cada passo e combinar três pequenos truques do print:
import time
total = 20
for passo in range(total + 1):
barra = "█" * passo + "░" * (total - passo)
print(f"\r[{barra}] {passo / total:.0%}", end="", flush=True)
time.sleep(0.1)
print()
Saída do Código (estado final, depois de ~2 segundos animando):
[████████████████████] 100%
Os truques envolvidos:
\rretorna o cursor para o início da mesma linha, de modo que cadaprintsobrescreve o anterior em vez de criar uma linha nova.end=""desliga o\nautomático doprint— sem isso, cada atualização desceria uma linha.flush=Trueforça a saída a aparecer na hora, sem esperar o buffer.time.sleep(0.1)faz uma pausa de 100 ms entre passos para o olho conseguir acompanhar.
Rodando no terminal, você vê uma única linha onde a barra vai se preenchendo do 0% até 100%.
Nota - Strings são Imutáveis
Operações como concatenação (+) e repetição (*) não modificam as strings originais, elas criam uma nova string em memória. Por isso, o resultado precisa ser atribuído a uma variável para ser usado depois.
Comparando strings#
Comparar strings é uma operação comum e pode ser realizada usando operadores de comparação. Python compara strings lexicograficamente, ou seja, com base na ordem alfabética e na posição dos caracteres.
Igualdade (==) e desigualdade (!=):
string1 = "Python"
string2 = "python"
print(string1 == string2) # False, diferencia maiúsculas e minúsculas
print(string1 != string2) # True, diferencia maiúsculas e minúsculas
Saída do Código:
False
True
Comparações lexicográficas (<, >, <=, >=):
string1 = "Abacate"
string2 = "Banana"
print(string1 < string2) # True, "Abacate" vem antes de "Banana"
print(string1 > string2) # False, "Abacate" vem antes de "Banana"
Saída do Código:
True
False
Dica - Comparações Insensíveis a Caso
Para comparações que devem ignorar maiúsculas e minúsculas, converta ambos os lados com .lower() (ou .upper()) antes de comparar. Para textos internacionais, prefira .casefold(), que trata corretamente caracteres como o ß alemão.
Exemplo de comparação insensível a caso:
string1 = "Python"
string2 = "python"
print(string1.lower() == string2.lower()) # True, ignora maiúsculas e minúsculas
Saída do Código:
True
Métodos de String#
Strings em Python possuem vários métodos internos que permitem realizar diversas operações de manipulação de texto. Aqui estão alguns dos métodos de string mais comumente usados, com exemplos de código e a saída esperada:
Método |
Descrição |
Exemplo |
Saída |
|---|---|---|---|
|
Converte a string em letras maiúsculas. |
|
OLÁ, MUNDO! |
|
Converte a string em letras minúsculas. |
|
olá, mundo! |
|
Converte a primeira letra da string em maiúscula e as demais em minúsculas. |
|
Olá, mundo! |
|
Remove espaços em branco (incluindo tabulações, quebras de linha, etc.) do início e do final da string. |
|
Olá, Mundo! |
|
Olá, Mundo! |
||
|
Remove espaços em branco apenas do início da string. |
|
Olá, Mundo! |
|
Remove espaços em branco apenas do final da string. |
|
Olá, Mundo! |
|
Divide a string em uma lista de substrings, separando-a por um delimitador especificado. |
|
[‘Olá’, ‘Mundo’] |
|
Junta os elementos de uma lista em uma única string, usando um delimitador especificado. |
|
Olá Mundo |
|
Substitui todas as ocorrências de um substring específico por outro substring. |
|
Eu gosto de laranjas |
|
Formata a string inserindo valores nas posições especificadas por chaves {}. |
|
Meu nome é Alberto e tenho 25 anos |
Nota - Métodos Retornam Novas Strings
Como strings são imutáveis, esses métodos nunca modificam a string original, eles sempre devolvem uma nova string. Para preservar o resultado, atribua a uma variável:
texto = "olá"
texto.upper() # cria "OLÁ", mas é descartado
texto = texto.upper() # agora `texto` guarda "OLÁ"
Verificação e Conversão de Tipos#
A verificação e conversão de tipos são tarefas importantes ao lidar com strings que representam números. A seguir, exploraremos os principais métodos para verificar se uma string contém apenas números e como realizar conversões entre strings e tipos numéricos.
Verificação de números em strings#
Python oferece três métodos para verificar se todos os caracteres de uma string são numéricos. A diferença entre eles está em quão permissivo cada um é: pense neles como camadas, onde cada método aceita tudo do anterior, mais alguns caracteres extras.
Método |
Aceita |
Exemplos |
Exemplos |
|---|---|---|---|
|
O mais restritivo: apenas dígitos do sistema decimal ( |
|
|
|
Tudo de |
|
|
|
O mais permissivo: tudo de |
|
|
Vendo isdecimal() em ação
A maneira mais rápida de internalizar o que conta como “dígito decimal” para o Python é jogar uma lista variada de strings dentro de um loop e observar o veredito:
casos = ["123", "٠١٢٣", "²", "½", "12.3", "-5", "1e10", "abc", ""]
for s in casos:
print(f"{s!r:>8} → {s.isdecimal()}")
Saída do Código:
'123' → True
'٠١٢٣' → True
'²' → False
'½' → False
'12.3' → False
'-5' → False
'1e10' → False
'abc' → False
'' → False
Lendo linha por linha:
"123"e"٠١٢٣"→ dígitos decimais “puros” (latinos e árabe-índicos): True."²"e"½"→ parecem números, mas não são decimais: False. (isdigit()aceitaria"²", eisnumeric()aceitaria os dois.)"12.3","-5","1e10"→ representam números válidos, mas contêm caracteres não-dígitos (.,-,e)."abc"→ óbvio: nenhuma letra é dígito decimal.""→ detalhe importante: a string vazia retornaFalse. Ou seja,isdecimal()já garante que existe pelo menos um caractere, todos sendo dígitos.
Qual usar?
Para a maioria dos casos práticos (validar que uma string pode ser convertida com
int()), useisdecimal(). É o mais previsível.isdigit()eisnumeric()só se justificam em contextos específicos de processamento de texto Unicode (sobrescritos, frações, algarismos romanos).
Atenção - O que Esses Métodos Não Aceitam
Nenhum dos três aceita sinal de menos, ponto decimal ou notação científica. Strings como "-5", "3.14" ou "1e10" retornam False em todos eles. Para validar números reais (float) ou inteiros negativos, use o padrão try/except mostrado na próxima seção.
Convertendo strings para números#
A conversão de strings para números pode ser feita usando as funções int() e float(). Se a string contiver caracteres inválidos (como letras), será gerado um erro.
Exemplos:
idade_str = "25"
idade_int = int(idade_str)
print(idade_int)
preco_str = "49.99"
preco_float = float(preco_str)
print(preco_float)
Saída do Código:
25
49.99
Atenção - ValueError na Conversão
As funções int() e float() levantam ValueError quando a string contém caracteres que não fazem parte de um número válido. Sempre valide a entrada antes (ou capture a exceção com try/except) para evitar que o programa quebre.
Tratando entradas inválidas#
É uma boa prática verificar a validade da string antes da conversão para evitar erros.
Exemplo:
entrada = "12.34"
if entrada.replace(".", "").isdigit():
numero = float(entrada)
print(numero)
else:
print("Entrada inválida!")
Saída do Código:
12.34
Dica - Conversão Segura com try/except
Para entradas vindas de usuários ou arquivos, prefira o padrão try/except, que é mais robusto do que validar com isdigit():
entrada = input("Digite um número: ")
try:
numero = float(entrada)
print(f"Você digitou: {numero}")
except ValueError:
print("Entrada inválida!")
Convertendo números para strings#
Para exibir números como texto, você pode usar as funções str() ou f-strings para obter maior controle sobre a formatação.
Exemplos:
numero = 42
numero_str = str(numero)
print(f"O número como string é: {numero_str}") # Usando f-string
valor = 3.14159
valor_formatado = f"{valor:.2f}" # Formata com 2 casas decimais
print(f"Valor formatado: {valor_formatado}")
Saída do Código:
O número como string é: 42
Valor formatado: 3.14
Conversão com formatação avançada Você pode personalizar ainda mais a conversão de números para strings.
Exemplo com separador de milhar:
numero_grande = 123456789
numero_str = f"{numero_grande:,}" # Usa ',' como separador
print(f"Valor formatado: {numero_str}")
Saída do Código:
Valor formatado: 123,456,789
Importante:
Use os métodos
isdigit(),isdecimal()ouisnumeric()para validar strings antes de convertê-las.Utilize
int()efloat()para conversões numéricas, garantindo que a string seja válida.Prefira f-strings para conversões e formatações avançadas, pois são mais modernas e legíveis.
Funções Úteis para Strings#
Python oferece várias funções integradas úteis para manipulação de strings. Estas funções permitem obter informações, verificar conteúdo ou realizar operações específicas. Aqui estão algumas das mais usadas:
Função |
Descrição |
Exemplo |
Saída (print) |
|---|---|---|---|
|
Retorna o comprimento (número de caracteres) da string. |
|
|
|
Verifica se um substring está contido ou não na string. |
|
|
|
Retorna o número de ocorrências de um substring na string. |
|
|
|
Retorna o índice da primeira ocorrência de um substring na string, ou |
|
|
|
Retorna o índice da primeira ocorrência de um substring na string. Levanta um erro se não encontrado. |
|
|
|
|
Atenção - find() vs index()
Os dois métodos fazem a mesma busca, mas tratam o caso de “não encontrado” de formas opostas: find() devolve -1 (que você precisa checar manualmente) e index() levanta ValueError. Use find() quando o substring pode legitimamente não existir e você quer um teste simples; use index() quando a ausência indica um erro real no fluxo do programa.
Expressões Regulares#
Expressões regulares (regex) são padrões utilizados para buscar e manipular texto de maneira eficiente. Em Python, o módulo re oferece funcionalidades para trabalhar com expressões regulares.
Uma ideia antes da teoria#
Imagine que você recebeu um texto e precisa extrair todos os números de telefone dele:
texto = "Entre em contato pelos telefones 3211-1234, 99988-7766 ou 4002-8922."
Sem nenhuma ferramenta especial, você teria que percorrer o texto caractere por caractere, verificar quais são dígitos, contar quantos vieram juntos, lembrar de tratar o hífen… um trabalho longo e fácil de errar.
Com expressões regulares, descrevemos o formato do que procuramos (“quatro ou cinco dígitos, um hífen, quatro dígitos”) e deixamos o módulo re fazer a busca:
import re
texto = "Entre em contato pelos telefones 3211-1234, 99988-7766 ou 4002-8922."
telefones = re.findall(r"\d{4,5}-\d{4}", texto)
print(telefones)
Saída:
['3211-1234', '99988-7766', '4002-8922']
Em uma única linha resolvemos o problema. O segredo está no padrão r"\d{4,5}-\d{4}", em que cada símbolo tem um significado: \d é um dígito, {4,5} é “de quatro a cinco vezes”, e - é o próprio hífen. É exatamente esse vocabulário de símbolos que a tabela a seguir organiza. Não se preocupe em decorar tudo de uma vez: cada símbolo vai aparecer em uso ao longo dos exemplos.
Tabela de Caracteres Especiais em Expressões Regulares#
Caractere |
Descrição |
Exemplo de Padrão |
Resultado do Exemplo |
|---|---|---|---|
|
Qualquer caractere (exceto nova linha) |
|
Corresponde a “casa”, “vasa”, “basa”, etc. |
|
Zero ou mais repetições do elemento anterior |
|
“ac”, “abc”, “abbbc”, etc. |
|
Uma ou mais repetições do elemento anterior |
|
“abc”, “abbc”, “abbbc”, etc. |
|
Zero ou uma repetição do elemento anterior |
|
“core” ou “cores” (o |
|
Início da linha |
|
“olá” somente no início da linha. |
|
Fim da linha |
|
“mundo” somente no final da linha. |
|
Início da string |
|
“olá” apenas no início da string. |
|
Fim da string |
|
“mundo” apenas no final da string. |
|
Conjunto de caracteres permitidos |
|
“ala”, “ela”, “ila”, etc. |
|
Conjunto de caracteres proibidos |
|
“bla”, “cla”, “fla”, etc. |
|
Um dígito ( |
|
“3”, “7”, etc. |
|
Um ou mais dígitos |
|
“3”, “75”, “1024”, etc. |
|
Caractere alfanumérico ( |
|
“a”, “Z”, “5”, “_” etc. |
|
Sequência alfanumérica contínua |
|
“texto”, “abc123”, “_abc”, etc. |
|
Um caractere de espaço (inclui tab, quebra de linha) |
|
“ “, “\t”, “\n”. |
|
Um ou mais espaços |
|
Sequências de espaços, tabs, quebras de linha. |
|
Um caractere que não é espaço |
|
“a”, “!”, “9”, etc. |
|
Sequência sem espaços |
|
“texto”, “abc123!”, etc. |
|
Limite de palavra |
|
Corresponde a “gato” como palavra isolada. |
|
Alternativa entre padrões |
|
“gato” ou “cão”. |
|
Exatamente n repetições |
|
“aa”. |
|
Entre n e m repetições |
|
“a”, “aa”, “aaa”. |
|
Grupo de captura |
|
Captura “12-3456”. |
Nota - Linha vs String
^ e $ marcam início e fim de linha; já \A e \Z marcam início e fim da string inteira. A diferença só aparece em textos com várias linhas (quando se usa a flag re.MULTILINE): nesse caso $ corresponde ao fim de cada linha, mas \Z corresponde apenas ao fim de tudo.
Saber montar o padrão é metade do trabalho; a outra metade é escolher o que fazer com ele. O módulo re oferece funções diferentes conforme a pergunta que queremos responder. Voltando ao texto dos telefones:
import re
texto = "Entre em contato pelos telefones 3211-1234, 99988-7766 ou 4002-8922."
padrao = r"\d{4,5}-\d{4}"
print(re.search(padrao, texto).group()) # só o primeiro telefone
print(re.findall(padrao, texto)) # todos os telefones
print(re.sub(padrao, "(oculto)", texto)) # troca cada telefone por outro texto
Saída:
3211-1234
['3211-1234', '99988-7766', '4002-8922']
Entre em contato pelos telefones (oculto), (oculto) ou (oculto).
Repare que o mesmo padrão serve para três tarefas distintas: encontrar a primeira ocorrência, listar todas ou substituir. A tabela abaixo reúne as principais funções do módulo re e quando usar cada uma.
Tabela de Funções do Módulo re#
Função |
Descrição |
Exemplo |
Resultado |
|---|---|---|---|
|
Encontra a primeira ocorrência do padrão em qualquer parte da string |
|
Match object para “gato”. |
|
Encontra o padrão no início da string |
|
Match object para “gato”. |
|
Retorna todas as ocorrências do padrão como lista |
|
|
|
Retorna um iterador com todas as correspondências, cada uma com acesso à posição |
|
Objetos Match para “3” e “5”. |
|
Substitui o padrão encontrado |
|
|
|
Divide a string pelo padrão |
|
|
|
Compila um padrão para uso eficiente |
|
|
Explicação detalhada
re.search: Procura o padrão em qualquer parte da string, mas retorna apenas a primeira ocorrência.re.match: Procura somente no início da string.re.findall: Retorna uma lista com todas as correspondências.re.finditer: Igual aofindall, mas retorna MatchObjects, permitindo posição inicial e final de cada ocorrência.re.sub: Substitui o padrão por outro texto.re.split: Divide o texto onde o padrão ocorre.re.compile: Pré-compila o padrão para repetição eficiente.
Sobre o uso de r em expressões regulares
O prefixo r cria uma raw string, evitando que Python trate \ como escape.
Isso facilita expressões como:
r"\bpalavra\b"
r"\d+"
Sem r, seria necessário escapar todas as barras invertidas, diminuindo a legibilidade.
Encontrando uma única palavra e sua posição com re.search#
import re
texto = "O rápido cão pulou sobre o coelho lento."
padrao = r"\brápido\b"
correspondencia = re.search(padrao, texto)
if correspondencia:
print(f"Palavra encontrada: {correspondencia.group()}")
print(f"Posição inicial: {correspondencia.start()}")
print(f"Posição final: {correspondencia.end()}")
else:
print("Palavra não encontrada.")
Saída:
Palavra encontrada: rápido
Posição inicial: 2
Posição final: 8
O que é o .group()?#
Após encontrar uma correspondência, o objeto retornado (match) contém várias informações sobre ela.
O método .group() retorna exatamente o trecho de texto que corresponde à expressão regular.
No exemplo acima:
correspondencia.group()
retorna:
rápido
Quando usar .group()?
Para recuperar o trecho do texto que combinou com a regex.
Para acessar grupos específicos quando sua expressão usa parênteses
().
Grupos adicionais
Se você tiver capturas como:
(\d{2})/(\d{2})/(\d{4})
então:
group(0)→ toda a datagroup(1)→ diagroup(2)→ mêsgroup(3)→ ano
Veja na prática, capturando os três grupos de uma data:
import re
texto = "O primeiro episódio do Monty Python foi ao ar em 05/10/1969."
padrao = r"(\d{2})/(\d{2})/(\d{4})"
m = re.search(padrao, texto)
print(m.group()) # toda a data (group(0))
print(m.group(1)) # dia
print(m.group(2)) # mês
print(m.group(3)) # ano
print(m.groups()) # todos os grupos numa tupla
Saída:
05/10/1969
05
10
1969
('05', '10', '1969')
Cada par de parênteses na regex cria um grupo, numerado da esquerda para a direita.
O método .groups() é um atalho que devolve todos eles de uma vez, em uma tupla.
Mas quando não há grupos na regex (como no exemplo do “rápido”),
group() e group(0) são iguais.
Encontrando todas as ocorrências com re.finditer()#
import re
texto = "O rápido cão encontrou outro cão rápido e depois mais um rápido."
padrao = r"\brápido\b"
ocorrencias = re.finditer(padrao, texto)
encontrou = False
for match in ocorrencias:
encontrou = True
print(f"Palavra encontrada: {match.group()}")
print(f"Posição inicial: {match.start()}")
print(f"Posição final: {match.end()}")
print("-" * 30)
if not encontrou:
print("Nenhuma ocorrência encontrada.")
Saída:
Palavra encontrada: rápido
Posição inicial: 2
Posição final: 8
------------------------------
Palavra encontrada: rápido
Posição inicial: 33
Posição final: 39
------------------------------
Palavra encontrada: rápido
Posição inicial: 57
Posição final: 63
------------------------------
Por que usar finditer?
Porque ele permite percorrer todas as correspondências e obter posições exatas, perfeito para análise de texto, marcação e destaque de palavras.
Exemplo: Procurando um número de telefone em um texto#
import re
texto = "Por favor, ligue para 123-456-7890 para mais informações."
padrao = r"\d{3}-\d{3}-\d{4}"
correspondencia = re.search(padrao, texto)
if correspondencia:
numero = correspondencia.group()
print(numero)
else:
print("Número de telefone não encontrado.")
Saída do Código:
123-456-7890
Explicação da expressão regular:
\d{3}: Corresponde a exatamente três dígitos.-: Corresponde ao caractere de hífen.\d{3}: Novamente, corresponde a exatamente três dígitos.-: Mais uma vez, corresponde ao caractere de hífen.\d{4}: Corresponde aos últimos quatro dígitos do número de telefone.
Exemplo: Verificando se uma string começa com um prefixo específico#
import re
def inicia_com_prefixo(texto, prefixo):
padrao = fr"^{prefixo}"
return bool(re.match(padrao, texto))
if inicia_com_prefixo("https://www.example.com", "http"):
print("A string começa com 'http'.")
else:
print("A string não começa com 'http'.")
Saída do Código:
A string começa com 'http'.
Explicação da expressão regular e da string fr"...":
^: Início de linha, garante que estamos correspondendo ao início da string.http: O prefixo que estamos procurando no início da string.fr"^{prefixo}": Combina f-string (f) com raw string (r).O
fpermite inserir a variável{prefixo}dentro do padrão.O
rgarante que a expressão regular seja tratada como literal, sem precisar escapar barras invertidas.
Ou seja, fr"^{prefixo}" permite montar dinamicamente uma expressão regular correta e segura, sem escapes desnecessários.
Exemplo: Validando um endereço de e-mail#
import re
def valida_email(email):
padrao = r"^\S+@\S+\.\S+$"
return bool(re.match(padrao, email))
email_valido = "exemplo@email.com"
email_invalido = "exemplo email.com"
if valida_email(email_valido):
print(f"{email_valido} é um endereço de e-mail válido.")
else:
print(f"{email_valido} não é um endereço de e-mail válido.")
if not valida_email(email_invalido):
print(f"{email_invalido} não é um endereço de e-mail válido.")
else:
print(f"{email_invalido} é um endereço de e-mail válido.")
Saída do Código:
exemplo@email.com é um endereço de e-mail válido.
exemplo email.com não é um endereço de e-mail válido.
Atenção - Validação de E-mail no Mundo Real
O padrão ^\S+@\S+\.\S+$ é didático e serve para entender a ideia, mas é frágil: ele aceita endereços claramente inválidos como a@@b.c. Validar e-mails de verdade é surpreendentemente complexo (a especificação oficial é enorme). Em projetos reais, prefira bibliotecas dedicadas, como a email-validator.
Explicação da expressão regular:
^: Início de linha.\S+: Corresponde a uma ou mais ocorrências de caracteres não-espaço.@: Corresponde ao símbolo @.\S+: Mais uma vez, corresponde a uma ou mais ocorrências de caracteres não-espaço.\.: Corresponde ao caractere ponto.\S+: Novamente, corresponde a uma ou mais ocorrências de caracteres não-espaço.$: Indica o fim de string.
Exemplo: Extraindo todas as ocorrências de uma palavra específica em um texto#
import re
texto = "Eu gosto de maçãs, bananas e laranjas. Maçãs são minhas favoritas."
padrao = r"\bmaçãs?\b" # aceita "maçã" e "maçãs"
ocorrencias = re.findall(padrao, texto, flags=re.IGNORECASE)
print(ocorrencias)
Saída do Código:
['maçãs', 'Maçãs']
Explicação da expressão regular:
\b: Indica limite de palavra, garantindo que a busca não encontre partes dentro de outras palavras.maçã: A raiz da palavra que queremos encontrar.s?: O?torna o “s” opcional — assim capturamos tanto “maçã” quanto “maçãs”.flags=re.IGNORECASE: Ignora diferença entre maiúsculas e minúsculas, permitindo encontrar “maçãs” e “Maçãs”.
Exemplo: Extraindo datas em um formato específico#
import re
texto = "As datas do evento são 2023-05-10, 2023-06-20 e 2023-07-15."
padrao = r"\b\d{4}-\d{2}-\d{2}\b"
datas = re.findall(padrao, texto)
print(datas)
Saída do Código:
['2023-05-10', '2023-06-20', '2023-07-15']
Explicação da expressão regular:
\b: Limite de palavra.\d{4}: Corresponde a exatamente quatro dígitos (ano).-: Corresponde ao caractere hífen.\d{2}: Corresponde a exatamente dois dígitos (mês).-: Mais uma vez, corresponde ao caractere hífen.\d{2}: Corresponde a exatamente dois dígitos (dia).\b: Limite de palavra.
Exemplo: Substituindo texto com re.sub()#
import re
texto = "Eu gosto de cachorros, gatos e cachorros."
padrao = r"\bcachorros\b"
substituicao = "gatos"
texto_modificado = re.sub(padrao, substituicao, texto)
print(texto_modificado)
Saída do Código:
Eu gosto de gatos, gatos e gatos.
Explicação da expressão regular:
\b: Limite de palavra, garante que estamos correspondendo à palavra inteira “cachorros”.“cachorros”: A palavra que estamos procurando para substituir.
Exemplo: Removendo caracteres não alfanuméricos de uma string#
import re
texto = "Este texto contém # caracteres $ especiais."
padrao = r"[^a-zA-Z0-9À-ÿ ]+" # mantém letras acentuadas também
texto_limpo = re.sub(padrao, "", texto)
print(texto_limpo)
Saída do Código:
Este texto contém caracteres especiais
Explicação da expressão regular:
[^a-zA-Z0-9À-ÿ ]+:[...]define um conjunto de caracteres permitidos ou negados.^dentro dos colchetes significa negação, ou seja, “qualquer caractere que NÃO seja um destes”.a-zA-Z0-9À-ÿinclui:Letras minúsculas e maiúsculas,
Dígitos,
Letras acentuadas.
O espaço também está permitido.
+significa “uma ou mais ocorrências” desses caracteres proibidos.Isso faz com que sequências como
##,$$$ou!!!sejam removidas de uma vez só.
Assim, o padrão remove qualquer símbolo ou caractere especial, mantendo apenas letras, números e espaços.
Nota - Espaços que sobram
Repare na saída: onde havia # e $ , ficaram espaços duplos. Isso acontece porque o padrão remove apenas os símbolos, deixando os espaços que estavam ao lado. Para colapsar vários espaços em um só, basta uma segunda substituição: re.sub(r"\s+", " ", texto).
Exemplo web: Vamos buscar uma palavra padrão em um site.#
import requests
import re
# URL do website
url = "https://heltonmaia.com/pythonbook/chapters/ch6/ch6.html"
# Faz a requisição GET para o website
response = requests.get(url)
# Obtém o conteúdo HTML da página
conteudo = response.text
# Procura a palavra "procurando" no conteúdo (com variações)
matches = re.findall(r'procurando', conteudo, re.IGNORECASE)
# Imprime o resultado
print(f"A palavra 'procurando' foi encontrada {len(matches)} vezes no site.")
Explicação rápida:
Importamos
requestspara fazer requisições web erepara trabalhar com expressões regulares.Definimos a URL do site a ser analisado.
Fazemos uma requisição GET e obtemos o HTML completo da página.
Usamos
re.findall()para procurar todas as ocorrências da palavra “procurando”.O padrão
r'procurando'encontra a palavra mesmo com pontuação colada (procurando.,procurando:).re.IGNORECASEpermite encontrar tanto “procurando” quanto “PROCURANDO”.
Imprimimos quantas vezes a palavra foi encontrada.
Saída do Código (exemplo):
A palavra 'procurando' foi encontrada X vezes no site.
As expressões regulares são uma ferramenta poderosa para manipulação de texto e podem ser aplicadas em diversas tarefas, incluindo busca, extração e transformação de padrões específicos. Para explorar ainda mais as possibilidades, consulte a documentação oficial sobre expressões regulares em Python: Expressões Regulares (re).
Exercícios#
Uma observação antes de começar os exercícios.
Alguns exercícios, dependendo do ambiente onde são resolvidos, podem exigir o tratamento de strings que contenham aspas duplas no início ou no final. Por exemplo, isso pode acontecer ao lidar com dados exportados de arquivos ou APIs. Nesse caso, o método .strip() pode ser usado não apenas para remover espaços em branco, mas também para eliminar as aspas duplas indesejadas.
Exemplos:
Removendo apenas as aspas duplas
# String com aspas duplas no início e no final
texto = '"Olá, Mundo!"'
# Removendo apenas as aspas duplas
texto_sem_aspas = texto.strip('"')
print(texto_sem_aspas)
Saída do Código:
Olá, Mundo!
Removendo apenas os espaços em branco
# String com espaços em branco no início e no final
texto = " Olá, Mundo! "
# Removendo apenas os espaços
texto_sem_espacos = texto.strip()
print(texto_sem_espacos)
Saída do Código:
Olá, Mundo!
Strings em Python possuem vários métodos internos que permitem realizar diversas operações de manipulação de texto. Entre os mais usados estão upper(), lower(), capitalize(), split(), join(), e replace(). Cada um deles oferece funcionalidades úteis para transformar ou manipular o conteúdo das strings. Você pode combinar esses métodos para atender às necessidades específicas de seu código.
1. Manipulação Básica de Strings
Desenvolva uma função chamada manipular_string que aceita uma string como entrada e executa as seguintes operações:
Extrai o primeiro caractere da string.
Obtém o último caractere da string.
Seleciona os três primeiros caracteres da string.
Captura os três últimos caracteres da string.
Inverte a ordem dos caracteres na string.
Remove apenas as vogais minúsculas (a, e, i, o, u) da string, mantendo as vogais maiúsculas e todos os outros caracteres.
A função deve compilar os resultados dessas operações em uma lista e retorná-la.
Exemplo de uso:
resultado = manipular_string("Python")
print(resultado)
Saída esperada:
['P', 'n', 'Pyt', 'hon', 'nohtyP', 'Pythn']
Testes a serem realizados:
# Teste 1
Entrada: "Hello"
Saída: ['H', 'o', 'Hel', 'llo', 'olleH', 'Hll']
# Teste 2
Entrada: "A"
Saída: ['A', 'A', 'A', 'A', 'A', 'A']
# Teste 3
Entrada: "Manipulando Strings"
Saída: ['M', 's', 'Man', 'ngs', 'sgnirtS odnalupinaM', 'Mnplnd Strngs']
2. Criando um Padrão de Moldura
Escreva uma função chamada criar_moldura que receba dois parâmetros: uma string (texto) e um caractere (elemento decorativo). A função deve criar uma moldura decorativa ao redor do texto fornecido, utilizando o caractere decorativo escolhido.
A moldura deve seguir estas regras:
Ter uma linha superior e inferior composta pelo caractere decorativo repetido.
O texto deve estar centralizado na moldura.
Deve haver um espaço entre o texto e o caractere decorativo nas laterais.
A largura total da moldura deve ser o comprimento do texto mais 4 caracteres (para os espaços e caracteres decorativos nas laterais).
Exemplo de uso da função:
texto = "Hello, World!"
caractere = "*"
moldura = criar_moldura(texto, caractere)
print(moldura)
Saída esperada:
*****************
* Hello, World! *
*****************
Sua tarefa é implementar a função criar_moldura que produz este resultado. Use concatenação e repetição de strings para criar a moldura. Lembre-se de que a função deve funcionar para textos de diferentes comprimentos e diferentes caracteres decorativos.
Testes adicionais:
# Teste 1
Entrada: Seu Nome,*
Saída:
************
* Seu Nome *
************
# Teste 2
Entrada: Python,#
Saída:
##########
# Python #
##########
# Teste 3
Entrada: _Strings_,=
Saída:
=============
= _Strings_ =
=============
3. Detector de Palavras-Chave em Textos
Você foi contratado para desenvolver um programa que analisa textos e identifica a presença de palavras-chave específicas. O programa deve ser capaz de contar quantas vezes cada palavra-chave aparece no texto, ignorando maiúsculas e minúsculas.
Crie uma função chamada busca_palavras_chave(texto, palavras_chave) que recebe dois parâmetros:
texto: Uma string contendo o texto a ser analisado.palavras_chave: Uma lista de strings contendo as palavras-chave a serem buscadas.
Faça:
Converta o texto para minúsculas para garantir que a busca seja case-insensitive.
Percorra a lista de palavras-chave e conte quantas vezes cada palavra aparece no texto.
Retorne um dicionário onde as chaves são as palavras-chave e os valores são o número de ocorrências de cada palavra no texto.
Para a leitura da entrada, use o seguinte formato: entrada = input().split(",")
Testes:
# Teste 1
Entrada: Python é uma linguagem de programação poderosa. python é poderoso e fácil de aprender. Muitos programadores adoram Python!, python, programação, linguagem
Saída: {'python': 3, 'programação': 1, 'linguagem': 1}
# Teste 2
Entrada: O gato preto pulou sobre o muro. O GATO branco miou para o gato preto., gato, preto, branco, cachorro
Saída: {'gato': 3, 'preto': 2, 'branco': 1, 'cachorro': 0}
# Teste 3
Entrada: A rápida raposa marrom pula sobre o cão preguiçoso., raposa, cão, gato, pula
Saída: {'raposa': 1, 'cão': 1, 'gato': 0, 'pula': 1}
Dica: Opcionalmente, você pode usar expressões regulares (módulo re) para solucionar o problema.
4. Validador de Senhas
Criar um programa que valide a qualidade de uma senha inserida pelo usuário, com base nos seguintes critérios:
Comprimento mínimo: 8 caracteres;
Letras maiúsculas: Pelo menos uma;
Letras minúsculas: Pelo menos uma;
Números: Pelo menos um.
Seu programa deve solicitar ao usuário que insira uma senha. Em seguida, utilizando funções de manipulação de strings, o programa deve verificar se a senha informada atende a todos os critérios de segurança listados acima.
Implemente uma função chamada validar_senha que recebe a senha como parâmetro e retorna uma lista contendo um booleano para cada uma das condições de segurança estabelecidas. A ordem dos booleanos na lista deve ser:
lista = [comprimento_minimo, tem_letra_maiuscula, tem_letra_minuscula, tem_numero]
Para cada critério, o programa deve exibir uma mensagem informando se ele foi atendido ou não, baseando-se nos valores booleanos retornados pela função.
Ao final da validação, o programa deve exibir uma mensagem geral informando se a senha é considerada forte ou fraca. Uma senha é considerada forte apenas se atender a todos os critérios.
Testes:
# Teste 1
Entrada: Senha123456
Saída:
Comprimento mínimo de 8 caracteres: OK
Pelo menos uma letra maiúscula: OK
Pelo menos uma letra minúscula: OK
Pelo menos um número: OK
Senha forte!
# Teste 2
Entrada: senha
Saída:
Comprimento mínimo de 8 caracteres: NÃO
Pelo menos uma letra maiúscula: NÃO
Pelo menos uma letra minúscula: OK
Pelo menos um número: NÃO
Senha fraca!
# Teste 3
Entrada: SENHA123
Saída:
Comprimento mínimo de 8 caracteres: OK
Pelo menos uma letra maiúscula: OK
Pelo menos uma letra minúscula: NÃO
Pelo menos um número: OK
Senha fraca!
# Teste 4
Entrada: Senha!
Saída:
Comprimento mínimo de 8 caracteres: NÃO
Pelo menos uma letra maiúscula: OK
Pelo menos uma letra minúscula: OK
Pelo menos um número: NÃO
Senha fraca!
5. Limpeza de Dados de Sensores com Expressões Regulares
Você recebeu um arquivo de texto contendo dados de sensores, mas ele contém alguns ruídos e espaços extras. Sua tarefa é criar uma função que utilize expressões regulares para limpar esses dados, tornando-os mais legíveis e organizados.
Implemente a função limpar_dados_sensor(dados) que recebe uma string dados e retorna a versão limpa dessa string.
Requisitos principais:
Remoção de caracteres especiais: Elimine todos os caracteres especiais, mantendo apenas letras, números, espaços e os símbolos usados nas medidas: ponto (
.), dois pontos (:), hífen (-), grau (°) e porcentagem (%).Espaços simples: Garanta que haja apenas um espaço entre palavras e números. Remova espaços extras desnecessários.
A função deve ser capaz de lidar com os seguintes tipos de dados de sensores: temperatura (°C), umidade (%) e pressão (hPa).
Teste sua função com os seguintes casos de exemplo:
# Teste 1
Entrada: Temperatura: 23.5°C& Umidade: 45% !@#$ Pressão: 1013.2hPa ^^^
Saída: Temperatura: 23.5°C Umidade: 45% Pressão: 1013.2hPa
# Teste 2
Entrada: Temperatura: -5.6°C !!! Umidade: 70% @@@ Pressão: 999.5hPa ###
Saída: Temperatura: -5.6°C Umidade: 70% Pressão: 999.5hPa
# Teste 3
Entrada: Temperatura: 25.3°C !!! Umidade: 60% @ # $ Pressão: 1000hPa ^^
Saída: Temperatura: 25.3°C Umidade: 60% Pressão: 1000hPa
6. Relatório de Resultados com f-strings
Você foi contratado para desenvolver um programa que gere um relatório com os resultados de um experimento. Cada experimento tem um nome, uma lista de valores medidos e um valor esperado para comparação. O relatório deve exibir o nome do experimento, a média dos valores medidos com duas casas decimais, e a diferença em relação ao valor esperado, também com duas casas decimais.
Crie uma função chamada gerar_relatorio(nome_experimento, valores_medidos, valor_esperado) que recebe:
nome_experimento: Uma string com o nome do experimento.valores_medidos: Uma lista de valores medidos (a quantidade pode variar).valor_esperado: Um número de ponto flutuante.
Faça:
Calcule a média dos valores medidos.
Determine a diferença absoluta entre a média e o valor esperado.
Retorne uma string formatada com f-strings com o relatório dos resultados.
Obs: Veja que a entrada dos dados é separada por vírgulas.
Testes:
# Teste 1
Entrada: Resistência do Material, 12.4 13.2 11.8 12.9 12.0, 12.5
Saída:
Experimento: Resistência do Material
Média dos valores medidos: 12.46
Diferença em relação ao valor esperado: 0.04
# Teste 2
Entrada: Teste de Impacto, 102.5 98.7 100.8 101.0, 100.0
Saída:
Experimento: Teste de Impacto
Média dos valores medidos: 100.75
Diferença em relação ao valor esperado: 0.75
# Teste 3
Entrada: Densidade do Líquido, 0.97 0.99 1.02 0.98 0.99, 1.0
Saída:
Experimento: Densidade do Líquido
Média dos valores medidos: 0.99
Diferença em relação ao valor esperado: 0.01
Dica: Use f-strings para formatar os valores numéricos com precisão (duas casas decimais) e para criar a string de saída.
7. Analisador de Textos com Funções de Strings
Você foi contratado para desenvolver um programa que analisa frases fornecidas pelo usuário. O programa precisa identificar informações importantes, como a presença de palavras específicas, contagens de ocorrências e posições de certos termos.
Crie uma função chamada analisar_texto(frase, palavra_alvo) que recebe:
frase: Uma string representando a frase a ser analisada.palavra_alvo: Uma string representando a palavra que será pesquisada na frase.
Faça:
Verifique se a palavra-alvo está presente na frase.
Conte quantas vezes a palavra-alvo aparece na frase.
Identifique a posição da primeira ocorrência da palavra-alvo (se existir).
Retorne uma string formatada com os resultados da análise.
Obs: A análise não deve ser sensível a maiúsculas/minúsculas.
Testes:
# Teste 1
Entrada: "Python é incrível. Python é poderoso!","Python"
Saída:
A palavra "Python" está presente: Sim
Número de ocorrências: 2
Posição da primeira ocorrência: 0
# Teste 2
Entrada: "Programação é divertida e desafiadora.","python"
Saída:
A palavra "python" está presente: Não
Número de ocorrências: 0
Posição da primeira ocorrência: -1
# Teste 3
Entrada: "Este texto é apenas um exemplo para teste.","teste"
Saída:
A palavra "teste" está presente: Sim
Número de ocorrências: 1
Posição da primeira ocorrência: 36
8. Gerador de Prompts para IA
Crie uma função que receba título e descrição, e formate um prompt padronizado para modelos de IA.
Função a Ser Criada
def gerar_prompt(titulo, descricao):
"""
Gera um prompt formatado para modelos de IA.
Args:
titulo (str): O título do prompt.
descricao (str): Uma breve descrição do contexto ou objetivo.
Retorna:
str: O prompt formatado.
"""
O prompt deve começar com o título entre “=== TÍTULO ===”.
Em seguida, deve exibir a descrição precedida pela palavra “Descrição:”.
Use quebras de linha para organizar o texto, garantindo uma formatação clara e legível.
Obs:
O título deve ser destacado utilizando letras maiúsculas.
A função deve garantir que o prompt seja retornado como uma única string formatada.
Testes:
# Teste 1
Entrada:
"Classificador de Sentimentos","Crie um modelo para classificar sentimentos como positivo; negativo ou neutro."
Saída:
=== TÍTULO ===
Classificador de Sentimentos
Descrição:
Crie um modelo para classificar sentimentos como positivo; negativo ou neutro.
# Teste 2
Entrada:
"Gerador de Histórias","Desenvolva histórias criativas com base em palavras-chave fornecidas."
Saída:
=== TÍTULO ===
Gerador de Histórias
Descrição:
Desenvolva histórias criativas com base em palavras-chave fornecidas.
# Teste 3
Entrada: "Assistente de Código","Ajude os usuários a depurar e otimizar seus códigos."
Saída:
=== TÍTULO ===
Assistente de Código
Descrição:
Ajude os usuários a depurar e otimizar seus códigos.
9. Validador de Campos de Formulário com Expressões Regulares
Desenvolva um programa que verifica se os campos de telefone e CPF em um formulário foram preenchidos corretamente, seguindo os formatos padrão.
Crie uma função chamada validar_campos(telefone, cpf) que recebe:
telefone: Uma string representando o número de telefone no formato(XX) XXXXX-XXXXou(XX) XXXX-XXXX.cpf: Uma string representando o CPF no formatoXXX.XXX.XXX-XX.
Faça:
Verifique se o telefone segue um dos formatos válidos especificados.
Verifique se o CPF segue o formato válido especificado.
Retorne uma string formatada indicando se cada campo é válido ou inválido.
Testes:
# Teste 1
Entrada: "(11) 98765-4321","123.456.789-09"
Saída:
Telefone válido: Sim
CPF válido: Sim
# Teste 2
Entrada: "(21) 8765-432","123.456.78-901"
Saída:
Telefone válido: Não
CPF válido: Não
# Teste 3
Entrada: "(84) 12345-6789","987.654.321-00"
Saída:
Telefone válido: Sim
CPF válido: Sim
# Teste 4
Entrada: "(83) 2345-6789","111.222.333-4A"
Saída:
Telefone válido: Sim
CPF válido: Não
10. Explorador de Artigos da Wiki
Crie uma função que utilize a biblioteca requests para buscar o conteúdo de um artigo da Wikipedia e realizar manipulações de strings com base em palavras-chave fornecidas.
Função a Ser Criada
def explorar_wiki(url, palavra_chave):
"""
Busca o conteúdo de um artigo da Wikipedia e realiza manipulações com base em uma palavra-chave.
Args:
url (str): URL do artigo da Wikipedia.
palavra_chave (str): Palavra-chave para buscas e análises no conteúdo do artigo.
Retorna:
dict: Um dicionário contendo o número de ocorrências da palavra-chave e o título do artigo.
"""
A função deve fazer uma requisição HTTP à URL fornecida usando
requests.get().Extraia o título do artigo (entre as tags
<title>).Conte quantas vezes a palavra-chave aparece no conteúdo.
Organize as informações em um dicionário com as chaves:
"titulo"e"ocorrencias".
Observações Importantes:
Status 200: O código de status HTTP 200 indica que a requisição foi bem-sucedida. Na prática, isso significa que:
A página foi encontrada corretamente no servidor
O conteúdo foi carregado sem erros
A página está pronta para ser processada
É necessário verificar
response.status_code == 200antes de processar o conteúdo para garantir que a requisição foi bem-sucedida
Normalize as buscas para que não sejam sensíveis a maiúsculas e minúsculas.
Nota - Os números podem variar
Os artigos da Wikipedia são editados constantemente, então a quantidade exata de ocorrências muda com o tempo. Os valores nos testes abaixo são apenas uma referência aproximada do momento em que o exercício foi escrito; o que importa é que sua função conte corretamente as ocorrências no conteúdo que receber.
Testes:
# Teste 1
Entrada: "https://en.wikipedia.org/wiki/Python_(programming_language)","language"
Saída: {'titulo': 'Python (programming language) - Wikipedia', 'ocorrencias': 1325}
# Teste 2
Entrada: "https://en.wikipedia.org/wiki/Artificial_intelligence","machine"
Saída: {'titulo': 'Artificial intelligence - Wikipedia', 'ocorrencias': 331}
# Teste 3
Entrada: "https://en.wikipedia.org/wiki/Quantum_mechanics","relativity"
Saída: {'titulo': 'Quantum mechanics - Wikipedia', 'ocorrencias': 34}
# Teste 4
Entrada: "https://en.wikipedia.org/wiki/Quantum_mechanics","relatividade"
Saída: {'titulo': 'Quantum mechanics - Wikipedia', 'ocorrencias': 0}